







搜索系统简介
一个基本的搜索引擎系统主要由离线(建库)和在线(检索)两部分构成,离线侧主要完成“网页获取——网页分析——建倒排索引库”的过程,在线侧主要完成“query获取——query处理——与doc进行相关性匹配”的过程。首先给出一个全貌图:
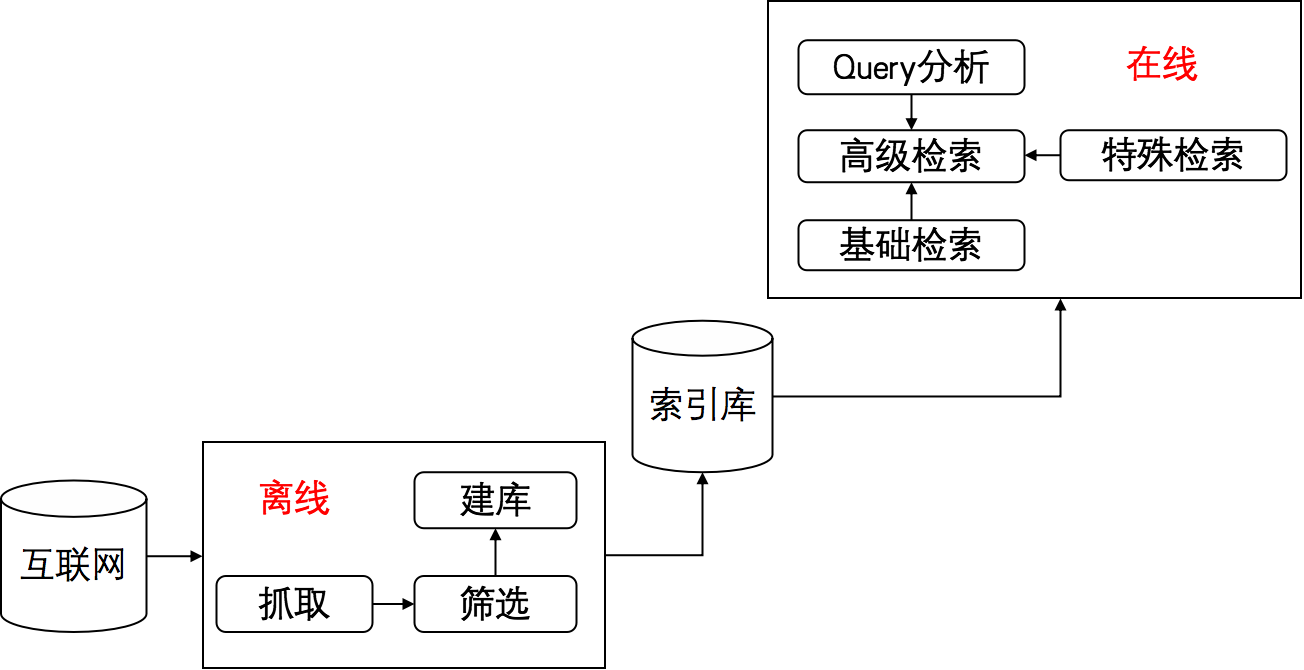 搜索系统概览
搜索系统概览
网页获取
做过爬虫的人都知道,网页获取实际上就是一个spider的过程,spider通过“抓取网页——分析页面——进网页库——提取链接——抓取网页”的循环过程从互联网上源源不断的获取网页,评价一个spider的优劣主要从“覆盖率”、“时效性”以及“更新率”三个方面来衡量,“覆盖率”强调网页内容的全面丰富,针对于通用搜索而言,搜索引擎希望能获取到互联网上各种各样的全面资源;“时效性”强调网页内容的时鲜度,尤其表现在新闻等领域;“更新率”强调网页内容的及时更新,页面变死、页面内容有变化等都能使用户直接感知到,因此spider必须要保证及时的更新网页。
索引库建立
首先给出几个搜索领域的关键词含义:
- term:网页内容切词后最基本的表述单位
- 正排表:以url为key,以term及其属性集合(比如term在页面中出现的次数、term在页面中的位置等)为value的数据结构
- 倒排表:以term为key,以url及term在该url中的属性集合为value的数据结构
- brief:页面上除了term,还有页面本身的属性,比如页面内容的丰富度、页面时间、页面权威性,这些信息和term没有关系,可以用数组直接存储brief信息,称为brief表
网页成功获取到网页库之后,需要进行“正文提取——切词——倒排索引”过程来建立倒排索引库,倒排索引库以term为基本单位,形成“term->拉链”的倒排单元。搜索即是query和网页的匹配过程,网页需要切词,query同样需要切词成term,因此从倒排索引中拉出拉链的过程就可以理解为是query的切词term和网页的切词term相匹配的过程。
在线检索
Query分析
上述过程中提到query需要切词,因此query分析就称为搜索过程中的一个重要部分,而query侧的term主要有“term的重要性”和“term的紧密度”两个重要属性,这两个属性直接决定不同的query从倒排索引中拉出的拉链结果。
- term的重要性:描述term在query中是否重要,重要的term在匹配的页面中必须出现,不重要的term可以省略或者赋予较低的权重
- term的紧密度:描述query中相邻或者相隔的几个term的关系是否紧密;如果term在query中是紧密的,在页面中也必须是紧密的
基础检索
基础检索的部分可以理解为query的term与doc的term进行匹配以及匹配后的多term归并的过程,即粗排序,完成url对query的打分。
- term归并:query分析得到很多term,圈出包含这些term的页面,得到url集合
- 权值计算:通过若干因素,计算出每个url对query的打分
高级检索
在基础检索中,query与doc的相关性等计算都细化到了term粒度,已经失去了原始query和doc的整体语义信息,因此需要高级检索通过计算query和页面的文本相关性来做精排序。
更复杂的算法可以根据用户的搜索-点击行为,构建点击率模型,或者根据学习排序的方法优化排序模型。
特殊检索
特殊检索主要是与业务强相关的检索,即在通用的排序规则上,开发人员可以根据业务需要进行一些自定义排序策略的开发,比如电商场景中根据点击量等对某些商品进行提升、根据商品的上架时间进行热度的更新等等。
参考:https://pminmin.github.io/2019/05/29/%E6%90%9C%E7%B4%A2%E7%B3%BB%E7%BB%9F%E7%AE%80%E4%BB%8B/















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









