







实验代码
代码下载
https://github.com/yunjey/StarGAN
依赖库安装
利用anaconda创建pytorch和tensorflow的虚拟环境来跑程序,公司可以上外网,框架安装过程以外的顺利。
$ conda create -n env_starGAN python=3.6
$ conda activate env_starGAN
$ conda install pytorch=0.4.0 cuda90 -c pytorch
此时报错
“The path ‘lib/libcublas.so’ specified in the package manifest cannot be found.”
输入
$ conda clean -all
将anaconda中多余残存的文件全部删除,再次安装就装好了
安装tensorflow:
$ conda install tensorflow-gpu=1.3
报错
UnsatisfiableError: The following specifications were found to be in conflict:
- pytorch=0.4.0 -> *[track_features=cuda90]
- pytorch=0.4.0 -> cudnn[version='>=7.0.5,<=8.0a0']
- tensorflow-gpu=1.3 -> tensorflow-gpu-base==1.3.0 -> cudnn=6.0
代码中tensorflow只是为了用tensorBoard,版本应该没有什么限制,那就下载最新的吧
conda install tensorflow-gpu
安装tensorflow1.12版本完成
代码运行
$ python main.py --mode train --dataset CelebA --image_size 128 --c_dim 5 \
--sample_dir stargan_celeba/samples --log_dir stargan_celeba/logs \
--model_save_dir stargan_celeba/models --result_dir stargan_celeba/results \
--selected_attrs Black_Hair Blond_Hair Brown_Hair Male Young
结果展示
下图为我自己跑的结果,每一列依次为 ‘original’ , ‘Black_Hair’, ‘Blond_Hair’, ‘Brown_Hair’, ‘Male’, ‘Young’。实验结果也不尽如人意,有些图效果不好,特别是young这一列。另外就是帽子和眼镜对结果的影响。

文章阅读
略读疑问
https://zhuanlan.zhihu.com/p/44563641
- 网上已经有很多这篇文章的翻译了,starGAN解决的问题是多领域迁移的问题,即一个生成器判别器可以用来解决不同的风格转换的问题,它是如何做到这一点的呢,为何有效?
- 另一点是解决了多数据集训练的问题,比如fig1注解中提到的,用RaFD的数据集训练的表情模型用到CelebA数据集上得到较好的结果,这一点如果真的做到了也很厉害,想知道是如何做到的。
精读翻译

-
图1: 上图展示了从RaFD数据集上学习得到的转换知识应用到CelebA数据集得到的多领域图像转换的结果。第一和第六列是输入图像,其他列是starGAN生成的图像。请注意,生成的图像都是由同一个生成器生成的,并且诸如生气,开心,恐惧等表情标签都是从RaFD数据集中来的,而不是CelebA。
-
摘要: 近期在两个图像领域进行转换已经取得了巨大的成功。然而,现有的方法对于处理超过两个领域的转换问题仍然有很大的局限性,对于每一对图像转换任务都需要单独训练一个模型。为了解决这一局限性,我们提出了starGAN,一种新颖的可扩展的方法,能够只用一个模型去进行多领域转换任务。这样一个统一模型使得只利用一个模型对不同的数据集进行多领域的图像转换任务成为可能。这也使得StarGAN相对于现有模型在图像转换任务上有着更好的质量,也具有更加新颖的灵活转换的能力。我们在经验上证明了我们方法在人脸转换和表情分析方面的有效性。
-
Introduction: 主要贡献:
-
我们提出了StarGAN,一种新颖的生成对抗网络,能够只用一个生成器和判别器学习多领域图像之间的映射。
-
我们证明了利用mask vector的方法我们成功的在不同的数据集上学习多领域图像的转换,这也使得我们提出的StarGAN能够控制各领域的标签。
-
我们使用StarGAN在人脸属性转换和人脸表情分析任务中提供了定量和定性的结果,展示了本模型相对于其他模型的优越性。

-
图2: 跨领域模型和我们提出的StarGAN模型对比,(a)中跨领域模型需要没两个图像领域对之间就训练一个生成器。(b)中starGAN能够只用一个生成器学习不同领域图像间的映射。图中展示了一个跨领域连接的五角星。
-
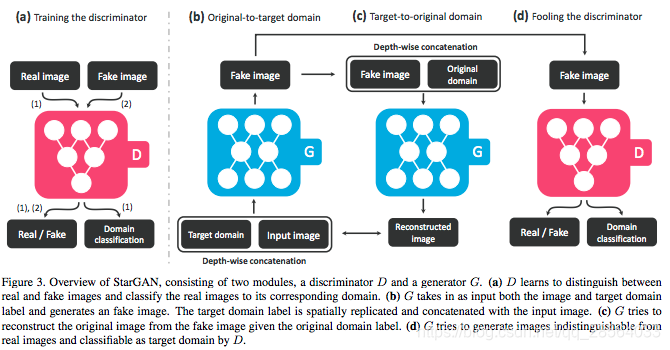
图3: StarGAN主要由两部分构成,一个判别器D和一个生成器G。(a)D学习判别真图和假图,并将真实图像分类到其所属类别。(b)G将图像和领域标签作为输入,生成假的图像。图像领域标签通过空间复制和输入图像concate在一起。©G从假的生成图像以及原始图像标签重构出原始图像(d)G生成的图像和真实图像无法被D区分,且被D分类为目标领域。
-
3. StarGAN网络结构: 我们首先描述了我们提出的StarGAN,在一个数据集中进行多领域的图像转换任务;然后我们讨论了如何使StarGAN能合并包含不同标签的数据集以及对其中任意的标签属性灵活进行图像转换。
-
- 3.1 多领域图像转换:
我们的目标是训练一个生成器G,能够多领域映射。为了实现这一目标我们训练了一个生成器G,它能将带有领域标签c的输入图像x转换为输出图像y,G(x,c)->y。我们随机生成目标领域标签c使得G能够灵活的转换输入图像。我们也引入了辅助判别器使得单个判别器能够控制多领域。也就是说,我们的判别器既产生图像也产生标签的可能性:D:x->{Dsrc(x),Dcls(x)},图3说明了我们提出方法的训练过程。
- 3.1 多领域图像转换:
-
-
- 对抗误差(Adversarial Loss)
为了使生成图像与真实图像无法区分,我们使用以下对抗损失函数:
Ladv=Ex[logDsrc(x)] + Ex,c[log(1 - Dsrc(G(x,c)))]
G生成图像G(x,c),由输入图像x和目标领域标签c的到,同时判别器D试图区分开真实图像和生成图像。这篇文章中我们将Dsrc(x)作为输入图像x经过判别器D之后得到的可能性分布。生成器G使这个式子尽可能的小,而判别器D则尽可能使其最大化。
- 对抗误差(Adversarial Loss)
-
-
-
- 分布判别损失函数(Domain Classification Loss)
对于一个输入图像x和目标分布标签c,我们的目标是将x转换为输出图像y,y能够被正确分类为目标分布c。为了实现这一目标,我们在D的顶部加入了辅助分类器,并加入分布分类损失函数,使其对生成器和判别器都起到正则化的作用.也就是说,我们将这个式子分解为两部分:一个真实图像的分布分类损失用于约束判别器D,一个假的图像的分布分类损失用于约束生成器G。其公式如下所示:
Lrcls = Ex,c’[-logDcls(c’|x)]
其中,Dcls(c’|x)代表D计算出来的领域标签的可能性分布。通过将这个式子最小化,判别器D学习将真实图像x正确分类到其相关分布c’.我们假设输入图像和分布标签(x,c’)都在训练数据中给出。另一方面,假图像的分布分类的损失函数定义如下:
Lclsf = Ex,c[-logDcls(c|G(x|c))]
也就是说,生成器G试图使这个式子最小化,使得生成的图像能够被判别器判别为目标领域c
- 分布判别损失函数(Domain Classification Loss)
-
-
-
- 重构误差(Reconstruction Loss)
通过最小化对抗损失和分类损失,生成器G能够生成尽可能真实的图像,并且能够被分类为正确的目标领域。然而,最小化这两个损失函数并不能保证转换后的图像在改变输入图像中与分布相关的部分的同时保留了输入图像的其他大部分内容,为了缓解这一问题,我们对生成器使用了循环一致性损失函数,定义如下:
Lrec = Ex,c,c’[||x - G(G(x,c),c’)||1]
其中,生成器G以生成图像G(x,c)以及原始输入图像领域标签c’为输入,努力重构出原始图像x。我们选择L1范数作为重构损失函数。注意到我们两次使用了同一个生成器,第一次将原始图像转换到目标领域的图像,然后将生成的图像重构回原始图像。
- 重构误差(Reconstruction Loss)
-
-
-
- 完整的损失函数表示(Full Objective)
最终,生成器G和判别器D的损失函数表示如下:
LD = -Ladv + λ \lambda λclsLrcls
LG = -Ladv + λ \lambda λclsLfcls+ / l a m b d a /lambda /lambdarecLrec
其中 λ \lambda λcls和 λ \lambda λrec是控制分类误差和重构误差相对于对抗误差的相对权重的超参数。在所有实验中,我们设置 λ \lambda λcls = 1 , λ \lambda λrec = 10。
- 完整的损失函数表示(Full Objective)
-
-
- 多数据集训练
starGAN的一个重要优势在于它能够同时合并包含不同标签的不同数据集,使得其在测试阶段能够控制所有的标签。从多个数据集学习的问题在于标签信息对每个数据集而言只是部分已知。在CelebA和RaFD的例子中,前一个数据集包含诸如发色,性别等信息,但它不包含任何后一个数据集中包含的诸如开心生气等表情标签。这会引起问题,因为在将G(x,c)重构回输入图像x时需要完整的标签信息c’
- 多数据集训练
-
-
- 向量掩码(Mask Vector)
为了缓解这一问题,我们引入了向量掩码 m m m,使StarGAN模型能够忽略不确定的标签,专注于特定数据集提供的明确的已知标签。在StarGAN中我们使用n维的one-hot向量来代表 m m m,n表示数据集的数量。除此之外,我们将标签的同一版本定义为一个数组:
c ‾ \overline{c} c = [c1,…,cn, m m m]
[·]表示串联,其中ci表示第i个数据集的标签,已知标签ci的向量能用二值标签表示二值属性或者用one-hot的形式表示多类属性。对于剩下的n-1个未知标签我们简单的置为0.在我们的实验中,我们使用了CelebA和RaFD数据集,此时n为2
- 向量掩码(Mask Vector)
-
-
-
- 训练策略
利用多数据集训练StarGAN时,我们使用上面定义的 c ‾ \overline{c} c作为生成器的输入。如此,生成器学会忽略非特定的标签,而专注于指定的标签。除了输入标签 c ‾ \overline{c} c,此处的生成器与单数据集训练的生成器网络结构一样。另一方面我们也扩展判别器的辅助分类器的分类类别到到所属聚集的所有标签。最后,我们将我们的模型按照多任务学习的方式进行训练,其中,判别器只将已知标签相关的分类误差最小化即可。例如,当模型用CelebA的图像进行训练时,判别器只是把CelebA中涉及到的属性标签的分类误差最小化,而不是RaFD数据集相关的面部表情的标签。通过这样的设置,判别器学习到了所有数据集的分类特征,生成器也学会控制所有数据集的所有标签。

- 训练策略
-
-
图4 脸部属性转换在CelebA数据集上的结果,第一列是输入图像,后四列展示了单属性的转换结果,最右边四列则展示了多属性转换结果,H:发色,G:性别,A:变老
-
实践
-
- **提高GAN的训练:**为了稳定训练过程,得到质量更好的图像,我们使用带梯度惩罚的WGAN策略作为对抗损失函数
-
- **网络结构:**和CycleGAN一样
-
实验 略
-
结论 这篇文章中我们提出了StarGAN,一种可扩展的只用一个生成器和判别器进行多领域图像到图像转换的模型。除了在可扩展性方面的优势,由于多任务学习策略在生成能力上的提升,StarGAN相对于其他现有方法也能生成质量更高的图像。除此之外,本文提出的单向量掩码也也使得StarGAN能够利用包含不同分布标签的不同数据集,进而可以处理从这些数据集中学习到的所有的属性标签。
疑问解答
- 关于单生成器解决多属性迁移的方法,文章的解决办法类似条件GAN,生成器的输入需要有期望的输出图像的domain这个信息,用以控制使生成图像的属性(发色,年龄,性别)。对应的判别器也加上一个domain判断的功能,用以约束和增强生成器往对应domain上生成。 domain标签添加方法:The target domain label is spatially replicated and concatenated with the input image,用one-hot的方式进行标签;个人感觉这就是条件GAN的延伸,通过不同的输入条件控制不同的属性迁移方向,感觉在性能上不一定能比得过专门为这个属性迁移而训练的生成器,当然,单模型做到多属性迁移这一点还是很棒的。
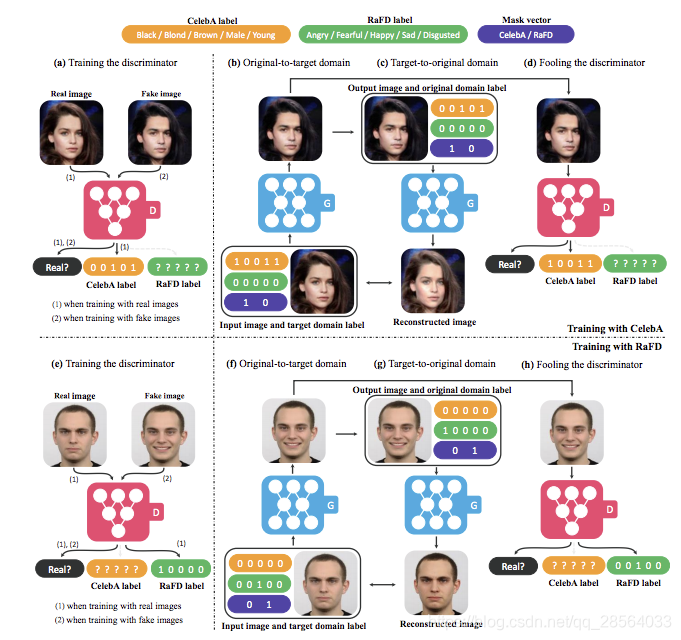
- 关于多领域多数据集的问题上图能很好地说明是如何做到的,与但数据集的区别就在于标签的设置上稍微复杂了一点点。训练的时候通过加一个mask vector指示是哪一个数据集,所有数据集的属性全部都列上去,但只标出所属数据集的标签就行。这一点确实还挺机智的,佩服。
最终总结
多属性多数据集都是通过添加条件(属性标签,数据集标签)来达成目的,总体来看还是条件GAN,而且属性也无法调节强弱,同时期的文章AttGAN在控制属性的同时还可以调节强弱,之后再来个对比分析吧















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









