







 本文介绍了NLP中处理文本的基本过程,包括从TF-IDF到BERT模型的向量表达方法,重点讲解了分词技巧和tokenizer的使用,以及如何为模型提供适当的输入格式,如词索引、token_type_ids和attention_mask。
本文介绍了NLP中处理文本的基本过程,包括从TF-IDF到BERT模型的向量表达方法,重点讲解了分词技巧和tokenizer的使用,以及如何为模型提供适当的输入格式,如词索引、token_type_ids和attention_mask。
0 介绍
NLP任务最初,就是在于如何处理文本。无论从TFIDF到word2Vec的过程,还是BERT都是想找到文本的向量表达,如何表示更好处理我们的下游任务。那么,这个过程是如何做的呢,本文主要就是介绍这一个过程,还是代码为主,你要知道所有的大模型都干了这个。
面对这么多的字,以及字之间的组合这是一个指数级别的增长。再者现在的网络文化无时无刻不再增加新的词汇,“提灯定损”,你懂的!VOF。那么模型具有一定的延时性,不可能包好所有的词,一个典型的没见过的用一个统一的符号代表。引入新的特殊含义字符:
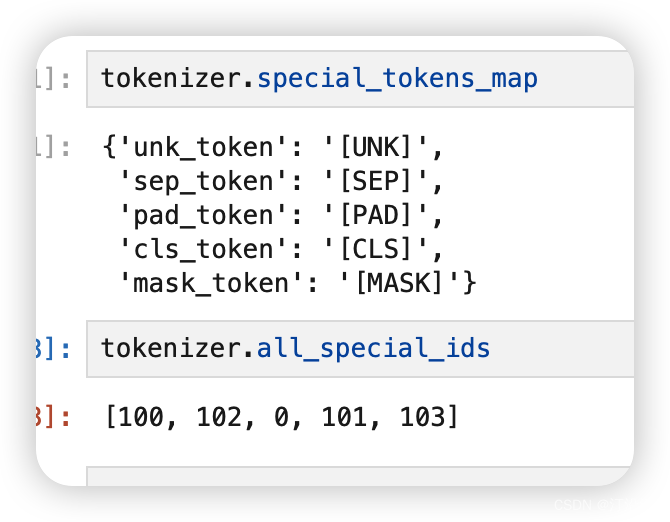
tokenizer.special_tokens_map:
1 简单分词
from transformers import AutoTokenizer
sen = "欲买桂花同载酒,终不似少年游!"
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer = AutoTokenizer.from_pretrained("./dianping")
tokens = tokenizer.tokenize(sen)
tokens
['欲', '买', '桂', '花', '同', '载', '酒', ',', '终', &
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









