







 本文介绍了在实际生产数据中处理异常点的几种常见方法,包括基于分布的Z-Score、箱线图四分位距和Grubbs检验。这些方法适用于不同类型的异常,如革新性异常、附加性异常、水平移位和暂时变更,帮助确保模型的准确性和稳定性。
本文介绍了在实际生产数据中处理异常点的几种常见方法,包括基于分布的Z-Score、箱线图四分位距和Grubbs检验。这些方法适用于不同类型的异常,如革新性异常、附加性异常、水平移位和暂时变更,帮助确保模型的准确性和稳定性。
在实际生产数据中,由于工业器械等各种因素可能伴随一些异常点数据。如果不及时处理很大程度会导致数据数据分布的改变,也为模型拟合带来困难。如果处理较好一个线性回归就很好的work。
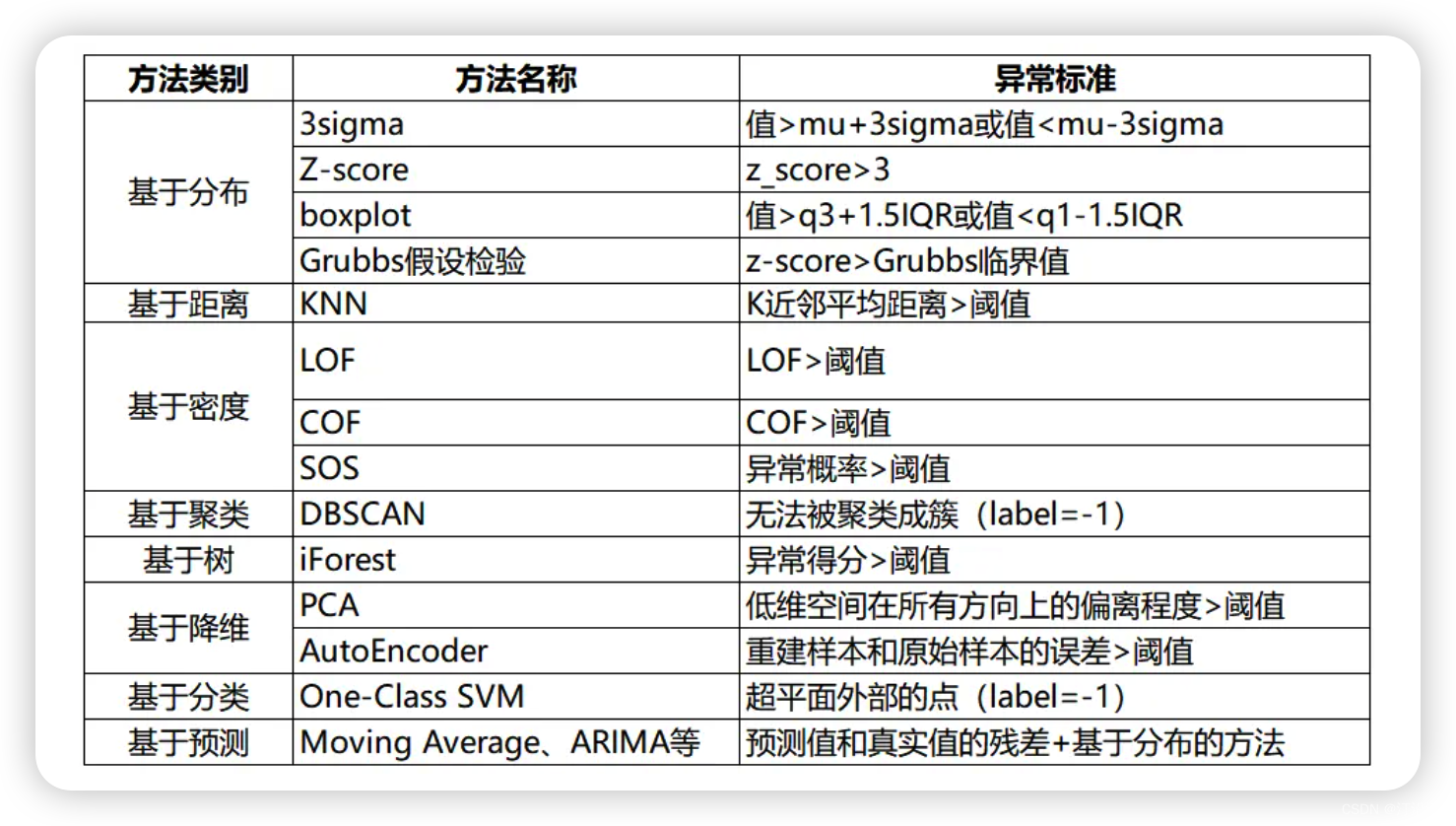
常见的异常有如下几种:
- 革新性异常:innovational outlier (IO),造成离群点干扰不仅作用于X(T),而且影响T时刻以后序列的所有观察值。
- 附加性异常:additive outlier (AO),造成这种离群点的干扰,只影响该干扰发生的那一个时刻T上的序列值,而不影响该时刻以后的序列值。
- 水平移位异常:level shift (LS),造成这种离群点的干扰是在某一时刻T,系统的结构发生了变化,并持续影响T时刻以后的所有行为,在数列上往往表现出T时刻前后的序列均值发生水平位移。
- 暂时变更异常temporary change (TC):造成这种离群点的干扰是在T时刻干扰发生时具有一定初始效应,以后随时间根据衰减因子的大小呈指数衰减。
1 基于分布的方法
1.1 Z-Score 方法
基于数据点与平均值之间的标准差来识别异常值。通过ZScore将正态分布的数据转化为标准正态分布数据,公式下:
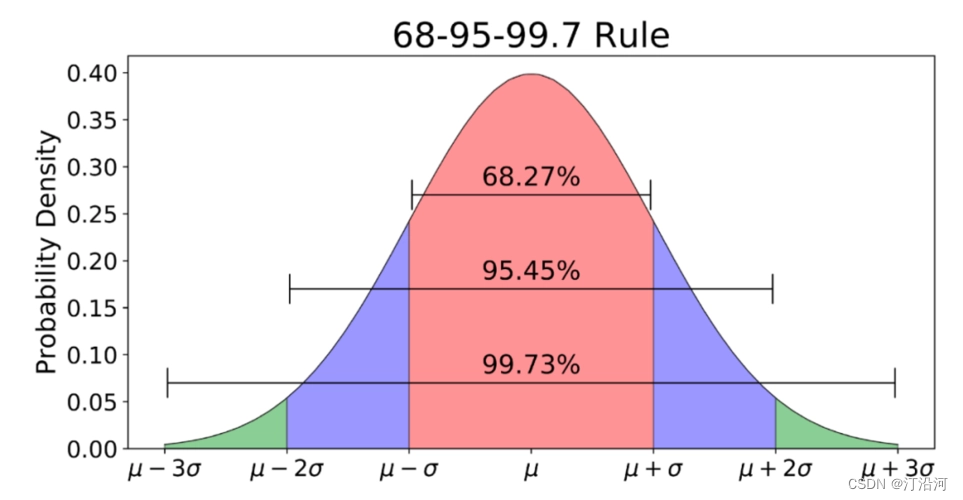
如果符合正态分布,则有68%的数据在±σ \sigmaσ之间;95%的数据在±2σ \sigmaσ之间;有99.7%的数据在±3σ \sigmaσ之间。
但大部分场景的数据都不满足正态分布的数据。
import numpy as np
from scipy.stats import zscore
# 生成随机数据
data = np.random.randn(100)
# 计算Z-Score
z_scores = zscore(data)
# 定义阈值,判断是否为异常值
threshold = 2.5
outliers = np.where(np.abs(z_scores) > threshold)[0]
print("Z-Score Outliers:", outliers)1.2 箱线图方法
使用四分位距来确定异常值的阈值。
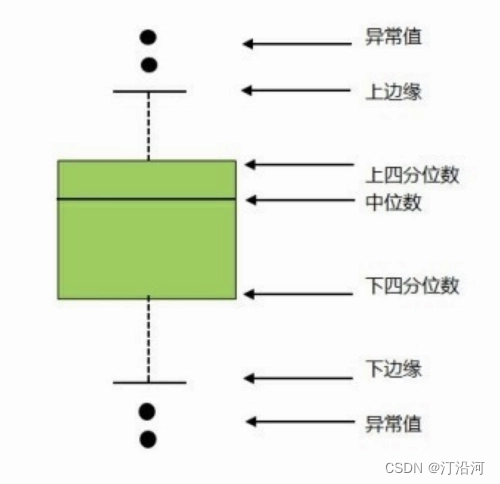
箱形图是数字数据通过其四分位数形成的图形化描述。这是一种非常简单但有效的可视化离群点的方法。考虑把上下触须作为数据分布的边界。任何高于上触须或低于下触须的数据点都可以认为是离群点或异常值。
箱形图剖析:
四分位间距 (IQR) 的概念被用于构建箱形图。IQR 是统计学中的一个概念,通过将数据集分成四分位来衡量统计分散度和数据可变性。
简单来说,任何数据集或任意一组观测值都可以根据数据的值以及它们与整个数据集的比较情况被划分为四个确定的间隔。四分位数会将数据分为三个点和四个区间。
四分位间距对定义离群点非常重要。它是第三个四分位数和第一个四分位数的差 (IQR = Q3 -Q1)。在这种情况下,离群点被定义为低于箱形图下触须(或 Q1 1.5x IQR)或高于箱形图上触须(或 Q3 + 1.5x IQR)的观测值。
def throwOutliers(datas,features):
import scipy.stats as st
dicts = {}
for feat in features:
print("======================================")
data = datas[feat]
u = data.mean()
std = data.std()
_,p = st.kstest(data,'norm',(u,std))
print('均值为:%.3f,标准差为:%.3f' % (u,std))
print("%s判定为正态分布的P值是%0.3f" % (feat,p))
color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')
fig = plt.figure(figsize = (6,4))
ax1 = fig.add_subplot(2,1,1)
data.plot.box(vert=False, grid = True,color = color,label = feat,ax=ax1)
s = data.describe()
q1 = s['25%']
q3 = s['75%']
iqr = q3 - q1
mi = q1 - 1.5*iqr
ma = q3 + 1.5*iqr
print('分位差为:%.3f,下限为:%.3f,上限为:%.3f' % (iqr,mi,ma))
print("======================================\n")
error = data[(data.values<mi) | (data.values>ma)]
normal = data[(data.values>=mi) & (data.values<=ma)]
dicts[feat] = error.index
ax2 = fig.add_subplot(2,1,2)
plt.scatter(normal.index,normal,color = 'k',marker='.',alpha = 0.3)
plt.scatter(error.index,error,color = 'r',marker='.',alpha = 0.5)
plt.show()
return dicts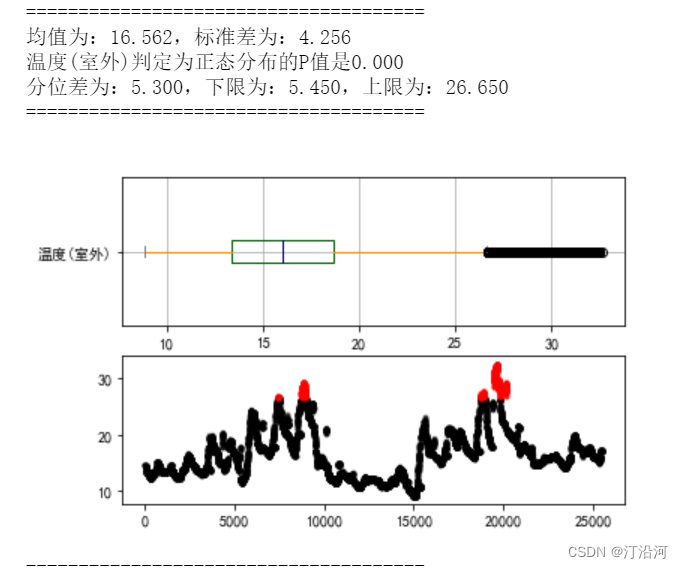
1.3 Grubbs测试
Grubbs’Test为一种假设检验的方法,常被用来检验服从正太分布的单变量数据集(univariate data set)Y 中的单个异常值。若有异常值,则其必为数据集中的最大值或最小值。原假设与备择假设如下:
- H0: 数据集中没有异常值
- H1: 数据集中有一个异常值
使用Grubbs测试需要总体是正态分布的。算法流程:
- 样本从小到大排序
- 求样本的mean和dev
- 计算min/max与mean的差距,更大的那个为可疑值
- 求可疑值的z-score (standard score),如果大于Grubbs临界值,那么就是outlier。
from outliers import smirnov_grubbs as grubbs
print(grubbs.test([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.min_test_outliers([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.max_test_outliers([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.max_test_indices([8, 9, 10, 50, 9], alpha=0.05))目前做简单的数据处理上述三个方法足够。
ref :14种数据异常值检验的方法!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









