







目录
0 简述
集成学习,典型的群殴策略,但是如何组织让彼此配合得当发挥最大的价值是一个值得思考的问题。
集成学习是一种机器学习方法,通过结合多个基本学习器的预测结果,从而获得比单个学习器更好的泛化性能的技术。集成学习的主要思想是“三个臭皮匠,顶个诸葛亮”,即通过组合多个弱学习器来构建一个强学习器。常见的集成学习方法包括 Bagging、Boosting、Stacking 等。这些方法可以提高模型的鲁棒性、泛化能力和准确性。在实际应用中,集成学习通常能够取得比单个模型更好的性能。
比如常见应用中对时间序列的一般会使用周期与趋势结合的方式,分别训练模型然后进行加权融合,权重大小可以根据线上的表现设定,如下图。其次为了扩展模型的多样性,在stacking策略选择第一层的学习去会使用不同类型的模型,然后对预测结果对比线性关系,把相关性较低的保留。


1 集成学习算法代表
1.1 Bagging
通过构建多个相互独立的基学习器,然后将它们的预测结果进行平均或投票来提高整体模型的性能。Bagging 的基本思想是通过自助采样(bootstrap sampling)从原始训练集中随机抽取多个子集,然后在每个子集上训练一个基学习器,最后将这些基学习器的预测结果进行组合。
- 第一步:在训练数据集中随机采样,对有m个样本训练集做T次的随机采样
- 随机采样:采集固定个数的样本,有放回的采样(每采样一个样本,都将样本放回)。一般是随机采集和训练集样本数m一样个数的样本。这样得到的采样集和训练集样本的个数相同,但是样本内容不同
- 第二步:训练一个基模型,对不同的子集进行训练。得到T个基模型。
- 第三步:T个基模型对测试数据进行预测,得到测试结果。
- 第四步:将T中结果综合起来。分类任务通常使用投票的方式得出结果,回归任务用平均的方式得到结果。
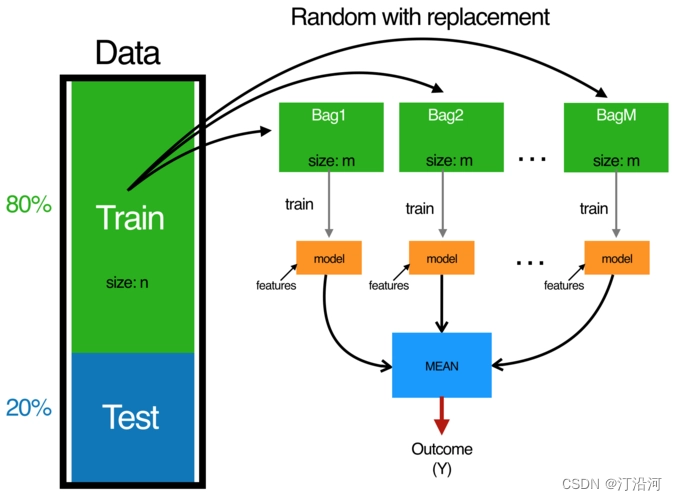
1.1.1 模型预测的结果组合的方式
- 求均值;
- 求中位数;
- 最大值;
- 最小值;
- 众数。
- 通过每个模型在测试集合的表现设定权重:逆向需要根据模型评估指标进行设定。

1.2 stacking
上面介绍的bagging,在模型结果集成使用统计策略的思想,而stacking使用模型进行学习。甚至可以把第一层的特征也输入给stacking的第二层。
-
数据集划分:
- 将训练数据集划分为多个子集,通常包括训练集和验证集。
- 通常采用交叉验证的方式进行数据集划分。
-
训练基学习器:
- 在每个子集上训练多个不同的基学习器,可以使用不同的算法或模型。
- 每个基学习器对整个训练集进行训练,但预测结果仅在验证集上生成。
-
生成元特征:
- 对于每个基学习器,在验证集上生成预测结果,这些预测结果作为元特征。
- 元特征可以是基学习器的原始预测结果,也可以是基学习器的概率输出或其他特征表示。
-
构建元学习器:
- 将基学习器的预测结果作为元特征,将真实标签作为目标,训练一个元学习器(通常是一个线性模型)来组合基学习器的预测结果。
- 元学习器可以是线性回归、逻辑回归、神经网络等模型。
-
生成最终预测:
- 使用训练好的元学习器对测试集进行预测,得到最终的集成预测结果。
- 元学习器将基学习器的预测结果组合起来,提高整体集成模型的性能。
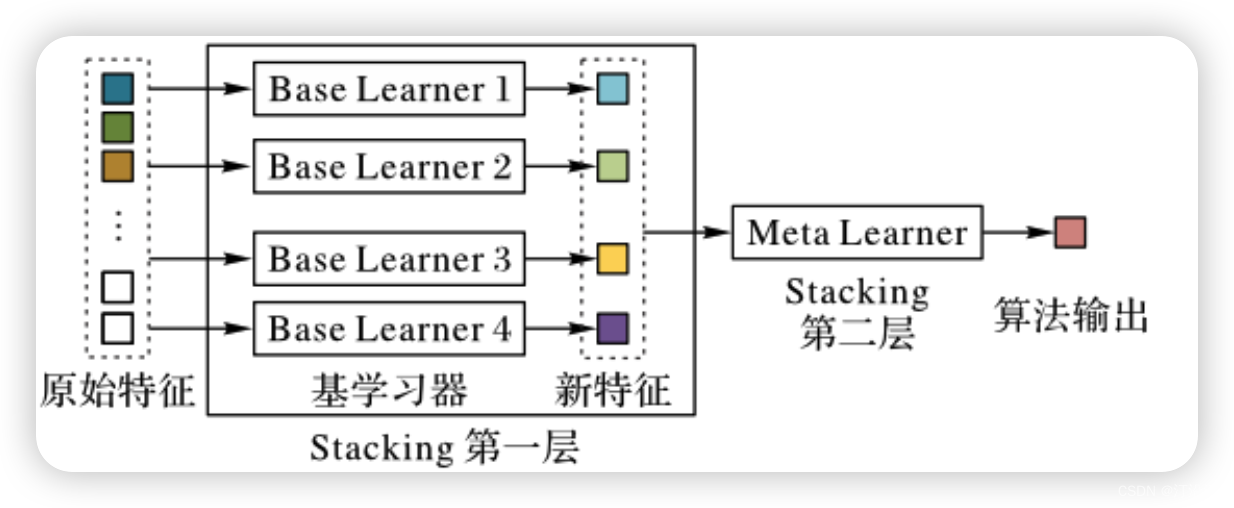

1.3 Blending
Blending(可译为混合)。它的思路和Stacking几乎是完全一样的,唯一的不同之就是Blending 的过程中不进行K折验证,而是只将原始样本训练集分为训练集和验证集,然后只针对验证集进行预测,生成的新训练集就只是对于验证集的预测结果,而不是对对全部训练集的预测结果。Blending 算法的流程如下图所示。
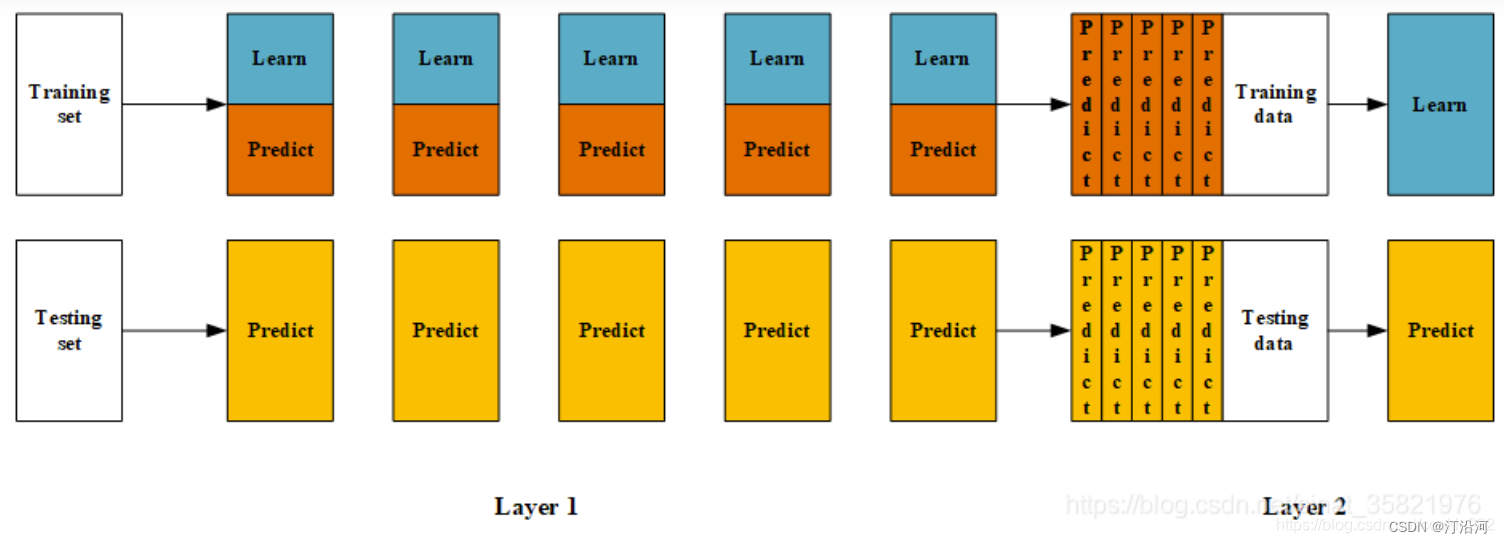
1.3 blending和stacking优缺点对比
1 blending是直接准备好一部分10%留出集只在留出集上继续预测,用不相交的数据训练不同的 Base Model,将它们的输出取(加权)平均。实现简单,但对训练数据利用少了。
2. blending 的优点是:比stacking简单,不会造成数据穿越(所谓数据创越,就比如训练部分数据时候用了全局的统计特征,导致模型效果过分的好),generalizers和stackers使用不同的数据,可以随时添加其他模型到blender中。
3.缺点在于:blending只使用了一部分数据集作为留出集进行验证,而stacking使用多折交叉验证,比使用单一留出集更加稳健。
4.两个方法都挺好,看偏好了,都可以尝试一下。















 4419
4419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









