







数据层、视觉层在之前的文章中已经介绍,这篇讨论了激活层的相关知识。
在激活层中,对输入数据进行激活操作,实际上就是一种函数变换,是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输出一个blob数据;在运算过程中,没有改变数据的大小,即输入输出的数据大小是相等的。
输入: n * c * h * w
输出: n * c * h * w
常用的激活函数有sigmoid、tanh、relu等,下面对这些激活函数分别进行介绍。
(1)Sigmoid非线性激活函数的形式

其图形如下图所示:
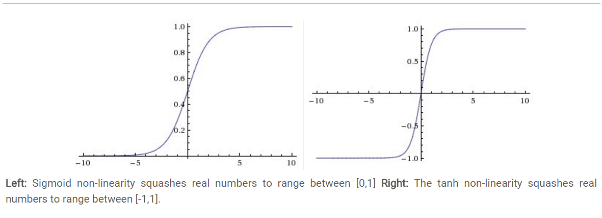
Sigmoid容易饱和,并且当输入非常大或者非常小的时候,神经元的梯度就非常接近于0了,从图中可以看出梯度的趋势。这就使得我们在反向传播算法中反向传播接近于0的梯度,导致最终权重基本没什么更新,我们无法递归地学习到新数据了。另外需要注意的是,参数值不能设置太大,否则大部分神经元可能都会处在saturation的状态而把gradient kill掉,这会导致网络变得很难学习。
另外,Sigmoid函数的输出不是零均值的,这会使得后层神经元的输入是非0均值的信号,这会对梯度产生影响。
(2)tanh双曲线正切函数
函数形式及图形如下图所示:
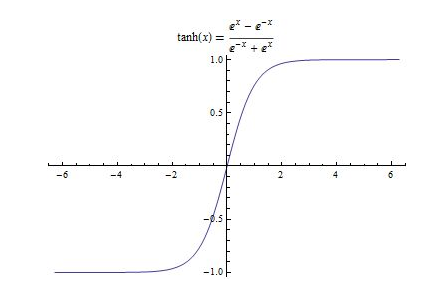
tanh函数和sigmoid函数有异曲同工之妙,但和sigmoid不同的是,他把实值输入压缩到-1~1的范围,因此它基本是0均值的,所以在实际应用当中,tanh比sigmoid更常用。但是它也存在饱和的问题。
(3)ReLU函数
ReLU激活函数的数学表达式是:f(x)=max(0,x)。下图即为它的图形形式:
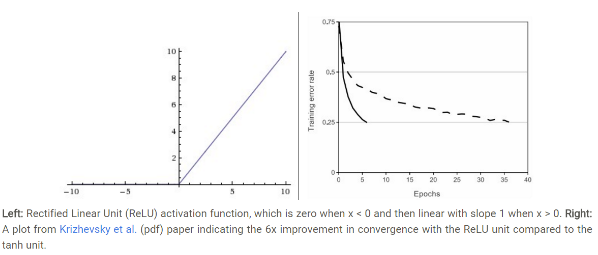
ReLU的优缺点如下:
优点:1)Krizhevskyetal.发现使用ReLU得到的SGD的收敛速度会比sigmoid/tanh快很多;而且它的梯度不会饱和。
2)相比于sigmoid/tanh需要计算指数等,计算复杂度高,ReLU只需要一个阈值就可以得到激活值。
缺点:ReLU在训练的时候很“脆弱”,很容易就会导致神经元“坏死”。由于ReLU在x<0的时候梯度为0,这样就导致负的梯度在这个ReLu被置零,而且这个神经元有可能再也不会被任何数据激活。
(Leaky ReLUs就是用来解决ReLu坏死的问题的,而关于Leaky ReLU的效果,众说纷纭,没有清晰的定论,所以在这里不作过多说明)















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









