







目前,基于区域的方法主要分为两类:任务解耦和的RCNN[1]和任务高度耦合的FCN[2]。
RCNN是将任务分解,目标检测、定位与分割依次逐一进行,前者决定后者的输入,因此称为任务解耦和。而FCN则将三类任务在一个网络中同时进行,不分先后,任务高度耦合。FCN已在医学图像领域有很多表现优异的衍生网络,如U-NET[12]等,而RCNN则应用较少。
1全卷积网络FCN
1.1FCN
用于图像分割的全卷积网络区别于其他网络最大的特点就是,可以接受任意大小的输入并产生相同大小的像素级分割结果,这一特性是由于它用卷积层代替了全连接层带来的,解除了全连接对输入大小的要求。并通过上采样+跳跃连接的形式来弥补池化下采样所造成的大小和信息损失,保持输入输出大小一致。
不过,FCN更适合于目标检测定位后的局部图像块的分割,并不适合大场景多目标的检测分割。同时,FCN可以看作基于网络最深层的分类结果,借助低层特征的信息填充进行上采样的过程,并没有改变特征提取的过程,只是在分类器层面进行了修改。因此,大多流行的分类网络,如VGG[13]和GoogleNet[14],可以很容易的转化成全卷积的结构。因此,通过调优现有的优秀网络模型可以较为方便的获取FCN。
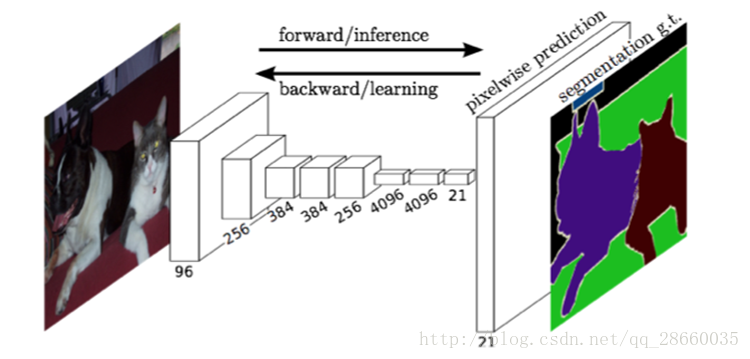
图1FCN网络结构
1.2U-Net
深层卷积神经网络训练需要大量样本,而医学图像并不具备这一条件,因此,U-Net在FCN的基础上进一步提高了数据利用效率,并提出了一种对称的网络结构,用对称的上采样弥补下采样所损失的信息。
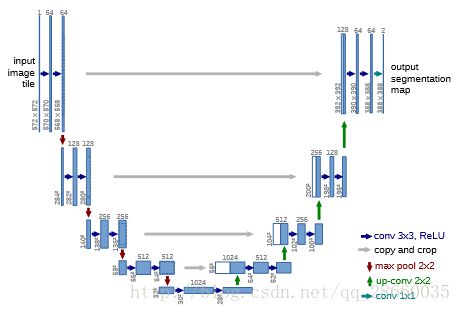
图2U-Net网络结构
分类网络通过池化来减少参数、增加非线性、扩大感知野并实现平移旋转尺度不变性,但同时也造成了信息损失,尤其是一些低层特征(如边界信息)的大量损失。因此我们需要通过连接、融合低层特征的方式,恢复底层信息,实现高精度分割。U-Net在用于分类的卷积神经网络后面加上了一段和前半部分对称的上采样过程用于增加输出的分辨率。并且,前半部分输出的低层特征将与后半部分输入结合来细化边界信息。
网络的整体设计模仿了VGG的设计理念,每下采样一次就加倍特征图数量。此外,为了最大化利用有限的数据,弹性形变和重叠拼接技术被用于数据增强。而且,为了迫使网络学习细微但极其重要的分割边界,预先生成了权值图(直接乘到损失值上),用于补偿来自确定类的不同频率的像素,强调边界信息。

图3U-Net单个训练样本a为输入原图b为分割结果c为标签文件d为像素级损失值权值
2基于区域的卷积神经网络RCNN
另一类方法就是解耦和任务的RCNN,将各任务级联,分布进行。
2.1R-CNN
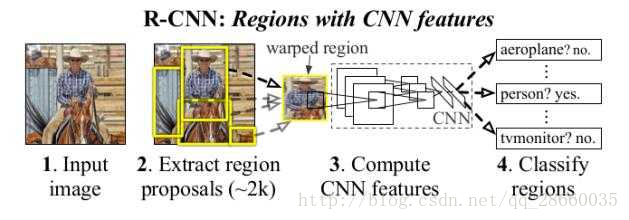
图4R-CNN系统流程图
从图4我们可以看出,该系统就是区域提案+CNN。对于输入的图片首先提取区域提案,对每个区域提案都输入CNN计算特征,而后将特征输入分类器确定该区域结果。
这里用到的区域提案方法是选择性搜索,分2步进行:1.放缩尺度依次提出初始提案;2.计算临近区域提案的相似度,合并相似区域。相似度的计算可以基于直方图或SIFT特征。最后确定的检测结果主要根据非极大值抑制,即如果一个区域与一个有更高分数的区域的交并比大于一个阈值则拒绝该区域提案。
对于正、负样本数量严重不均衡的问题,此处决定每次均匀采样32个正样本、96个负样本,共128个图作为一个mini-batch。而且,该网络的调优技术也很值得参考。该网络采用了针对性的调优方法,困难负样本挖掘,即专门选取那些被高分误认为正样本的负样本进行训练。这一优化策略可以使得网络快速收敛到一个更优解。
此外,网络还增加了一个线性回归模型用于预测最后结果的检测窗口。
2.2FastR-CNN[3]
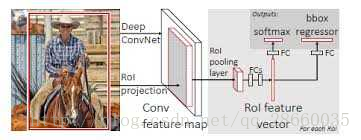
图5 Fast R-CNN系统流程图
根据共享计算的思路,不再将每个区域提案输入CNN计算,而是将整张图输入CNN获得特征图(VGG中比原图小16倍),我们就可以根据位置对应关系获得每个点的特征值。用RoIPool层再对各提案区域中的点,均匀分成固定数量分区域(如7x7),对每个区域进行最大值池化,即可获得各提案区域固定大小的特征图小块,用于分类和检测窗口回归。
此外,利用多任务损失值进行网络优化。最后的损失值是分类损失值和定位损失值的加和。分类损失值采用交叉熵,定位损失值在较小时采用guan光滑微变的L2范数,在较大时采用L1范数,防止损失值爆炸。
2.3FasterR-CNN[4]
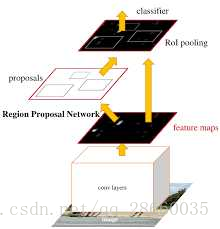
图6 Faster R-CNN系统流程图
从题目可以看出,这一网络最主要的实现的速度的提升,即对R-CNN中最费时的区域提案进行了优化,将区域提案并入卷积神经网络网络完成,由一个RPN(区域提案网络)根据卷积网络提取的特征图,以完成区域提案。RPN充当注意力机制来和FastR-CNN进行融合。
很多方法通过缩放图像形成图像金字塔或通过使用多种尺寸的滤波器形成滤波器金字塔,来完成多尺度区域的提取。RPN是通过在回归函数中使用不同大小和横纵比的参考框金字塔来完成多种尺度的特征提取的。具体实现方法是,通过锚点机制完成的。通过在卷积网络的输出特征图上的每个位置标记锚点,每个锚点位置同时预测多个提案,每个提案是以该锚点为中心的一片区域(不同尺度和横纵比,比如3种尺度和3种横纵比,就是9个锚点框)。这种机制同时也具有尺度不变性。
对于RPN的训练,则是为了防止提案过于偏向负样本,就随机取128个提案,不过正负样本各占一半。对于整个FasterR-CNN的训练则分成4步进行,以实现RPN和FastR-CNN的卷积特征的共享:
第一步,调优用于分类的预训练模型来训练RPN;第二步,使用第一步训练出来的RPN所产生的提案来训练一个单独的FastR-CNN(同样是调优用于分类的预训练模型);第三步,使用FastR-CNN的卷积网络部分来初始化RPN,只训练RPN独有的层(固定共有的卷积网络部分);第四步,只训练FastR-CNN独有的层(固定共有的卷积网络部分及RPN层)。
2.4MaskR-CNN[5]
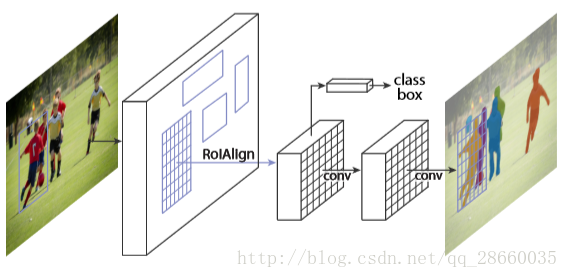
图6 Mask R-CNN系统流程图
从流程图我们可以很明显的看出,这一网络将像素级分割并入了FasterR-CNN中,不过区别于全卷积类型的网络,MaskR-CNN仍保持R-CNN各任务高度解耦和的风格。此外,为了实现准确的分割,还改进了兴趣区域池化层,主要很大程度解决了对不准的问题(RoIAlign)。
主要做法就是在定位框的那条网络旁并联了一个分支,用于预测物体掩码。因此,分割网络的输入和重定位框是一样的,两个任务是同步进行的,这就不同于很多其他方法将重定位区域和作为分割网络的输入。并且为每一类单独进行掩码预测,避免了各类之间的竞争。相应的损失值也是一样的,哪一类的掩码就只对这个类的输出结果生效。具体的网络结构时模仿FCN创建的,以保存空间位置信息,避免被全连接层破坏。不过,FCN中进行情景分割时,进行了逐像素的softmax和多项交叉熵损失值。MaskR-CNN进行了逐像素sigmoid和二值化损失值。
此外,提出了RoIAlign以优化RoIPool带来的空间位置错位问题。区域提案是对原图进行兴趣区域提取,再用RoIPool找到卷积产生的特征图对应位置提取特征小块,计算方法是对原图中的位置除以在卷积过程中的步长乘积(如VGG就是16),再取整,这样找到对应区域的特征小块就因为取整导致对不齐。因此RoIAlign就不再对除后结果取整,而是通过双线性插值确定原图兴趣区域中每个点的特征值,再进行池化等操作就相对准确。
此外,该方案应用了新提出的(FPN)特征金字塔网络的技术,实现了不同尺度特征的更有效利用,在单一尺度输入的情况下,很好的解决了多尺度问题。FPN采用了自上而下的侧向连接将不同尺度的特征连接融合(上采样后相加)起来,再进行3x3的卷积以消除混叠现象,而后在所有尺度上进行预测,重复这个过程,直到得到最佳的分辨率。FPN在不增加计算量的前提下,很好的解决了多尺度下小物体的精准快速检测问题。
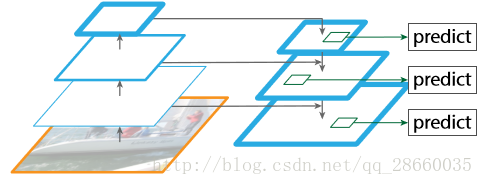
图7 FPN特征金字塔
参考文献:
[1]Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik; RichFeature Hierarchies for Accurate Object Detection and SemanticSegmentation The IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2014, pp. 580-587
[2]JonathanLong, Evan Shelhamer, Trevor Darrell; Fully Convolutional Networksfor Semantic Segmentation The IEEE Conference on Computer Vision andPattern Recognition (CVPR), 2015, pp. 3431-3440
[3]RossGirshick; Fast R-CNN. The IEEE International Conference on ComputerVision (ICCV), 2015, pp. 1440-1448
[4]Ren, Shaoqing and He, Kaiming and Girshick, Ross and Sun, Jian.Faster R-CNN: Towards Real-Time Object Detection with Region ProposalNetworks. Advances in Neural Information Processing Systems. 2015,pp. 91--99
[5]Kaiming He and Georgia Gkioxari and Piotr Dollr and Ross B.Girshick.Mask R-CNN.
[12]Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networksfor biomedical image segmentation. In: Navab, N., Hornegger, J.,Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp.234–241. Springer, Heidelberg (2015).
[13]P. H. Pinheiro and R. Collobert. Recurrent convolutional neuralnetworks for scene labeling. In ICML, 2014. 1, 2, 4, 7, 8
[14]P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, andY.LeCun.Overfeat: Integratedrecognition, localization and detection usingconvolutional networks. In ICLR, 2014. 1, 2, 4
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









