









版权声明:本文为博主原创文章,未经博主允许不得转载。
序言
- 下载软件与工具包
- pscp.exe : 用于从本地到目标机器的文件传输
- hadoop-2.7.3.targ.gz: Hadoop 2.7 软件包
- JDK 1.8: Java 运行环境
- 准备四台安装好CentOS (选择基本服务器安装,最小安装会少这少那比较麻烦,反正我没有折腾了很久没有成功)的机器,且已经配置网络环境(链接方式选择桥接)。(只需要记住四台机器的IP地址,主机名后面设置)
- 机器1: 主机名 node, IP: 192.168.169.131
- 机器1: 主机名 node1, IP: 192.168.169.133
- 机器1: 主机名 node2, IP: 192.168.169.132
- 机器1: 主机名 node3, IP: 192.168.169.134
文件准备
-
添加用户组与用户(选择安装在root用户下可以省略这步,建议在root用户下安装,这样其他用户可以方便访问)
- 1
- 2
- 1
- 2
-
复制本机文件到目标机器
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-
解压并复制文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
权限修改
-
修改夹所有者
- 1
- 1
-
修改组执行权限
- 1
- 1
若是以root用户安装不需要1、2步骤,root的安装是文件位置如下:Java:/usr/local/jdk1.8Hadoop:/usr/local/hadoop2.7如安装在root下,以下的遇到路径的配置做相应的修改
配置系统环境
-
配置系统变量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
配置主机域名
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
关闭防火墙
- 1
- 2
- 1
- 2
配置Hadoop集群
(一)、namenode配置如下:
-
修改配置文件----添加Java环境
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
-
配置从节点主机名
- 1
- 2
- 3
- 1
- 2
- 3
-
拷贝文件并覆盖以下文件
- /home/hadoop/hadoop2.7/etc/hadoop/core-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- /home/hadoop/hadoop2.7/etc/hadoop/hdfs-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- /home/hadoop/hadoop2.7/etc/hadoop/mapred-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- /home/hadoop/hadoop2.7/etc/hadoop/yarn-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
(二)datanode配置
1、所有datanode都重复
“
配置Hadoop集群”
前的操作
2 、拷贝jdk和Hadoop文件到node1、node2、node3节点与node节点相应的路径下(scp 命令,不懂得百度一大堆)
2 、拷贝jdk和Hadoop文件到node1、node2、node3节点与node节点相应的路径下(scp 命令,不懂得百度一大堆)
3、修改slaves文件, 除了做secondnamenode节点外(这里是node1),其他节点均清空slaves
[hadoop@node ~]$
>
/home/hadoop/hadoop2.7/etc/hadoop/slaves
配置无密码登录
-
在所有主机上创建目录并赋予权限-----root安装此步骤省略
- 1
- 2
- 1
- 2
-
在node主机上生成RSA文件
- 1
- 1
-
生成并拷贝 authorized_keys文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
在所有主机上修改拥有者和权限-----root安装此步骤省略
- 1
- 2
- 1
- 2
-
修改ssh 配置文件
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-
重新启动ssh
- 1
- 1
Note: 第一次连接仍然需要输入密码。
启动Hadoop
-
进入Node 主机,并切换到Hadoop账号
- 1
- 1
-
格式化 namenode
- 1
- 1
-
启动 hdfs
- 1
- 1
-
验证 hdfs 状态
-
启动 yarn
- 1
- 1
- 验证 yarn 状态
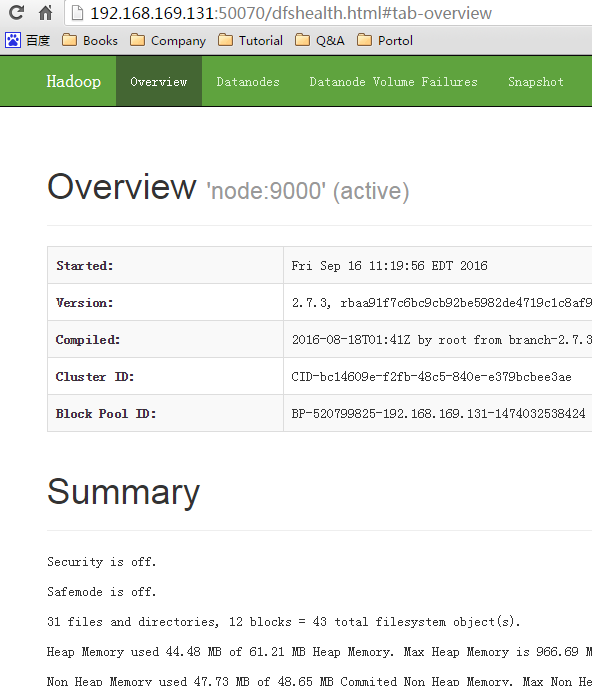
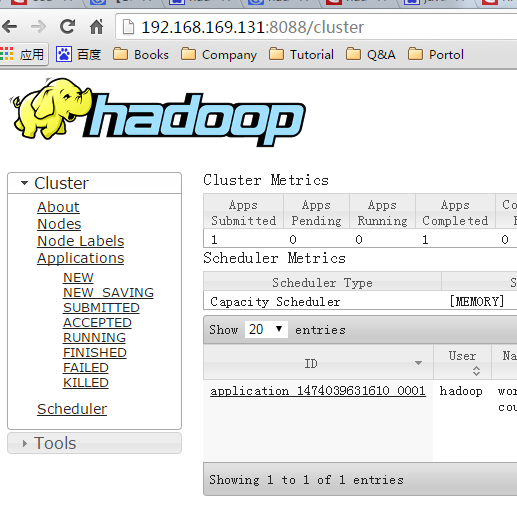
默认举例
-
创建文件夹
- 1
- 2
- 3
- 1
- 2
- 3
-
上传文件
- 1
- 2
- 3
- 1
- 2
- 3
-
执行Map-Reduce
- 1
- 1
-
查看状态
- 1
- 1
-
浏览结果
- 1
- 1
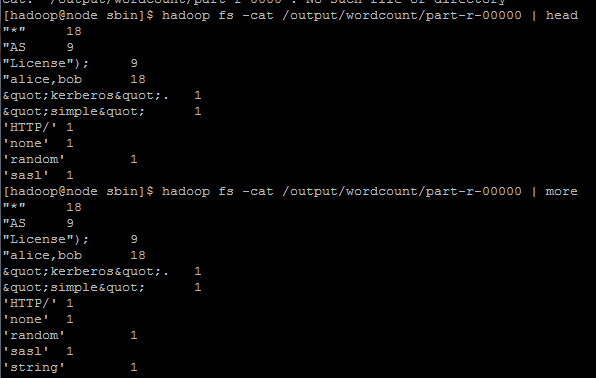
http://www.cnblogs.com/liuling/archive/2013/06/16/2013-6-16-01.html
本文转子博主:小杭嘟嘟嘟,在此表示感谢!!!















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









