name = ['china','japan','korea','iran','saudi','lraq','qatar','arab',
'uzbekistan','thailand','vietnam','oman','bahrain','northkorea','indonesia']
# 将国家名字保存在列表,以便调用
country =[[50, 50, 9], [28, 9, 4], [17, 15, 3], [25, 40, 5], [28, 40, 2], [50, 50, 1],
[50, 40, 9], [50, 40, 9], [40, 40, 5], [50, 50, 9], [50, 50, 9], [50, 50, 9],
[40, 40, 9], [40, 32, 17], [50, 50, 9]]
# 将国家成绩保存为列表,以便调用
word1 = []
word2 = []
asia = []
groupi = []
groupj = []
groupk = []
namei = []
namej = []
namek = []
for i in range(15):
word1.append(country[i][0])
word2.append(country[i][1])
asia.append(country[i][2])
# 把2006,2010,2007年的排名读入列表word1,word2,asia中
for i in range(15):
word1[i] = (word1[i] - min(word1)) / (max(word1) - min(word1))
for i in range(15):
word2[i] = (word2[i] - min(word2)) / (max(word2) - min(word2))
for i in range(15):
asia[i] = (asia[i] - min(asia)) / (max(asia) - min(asia))
# 将每个年度的数据归一化
for i in range(15):
country[i][0] = word1[i]
country[i][1] = word2[i]
country[i][2] = asia[i]
# 将归一化后的数据放回原来的列表内
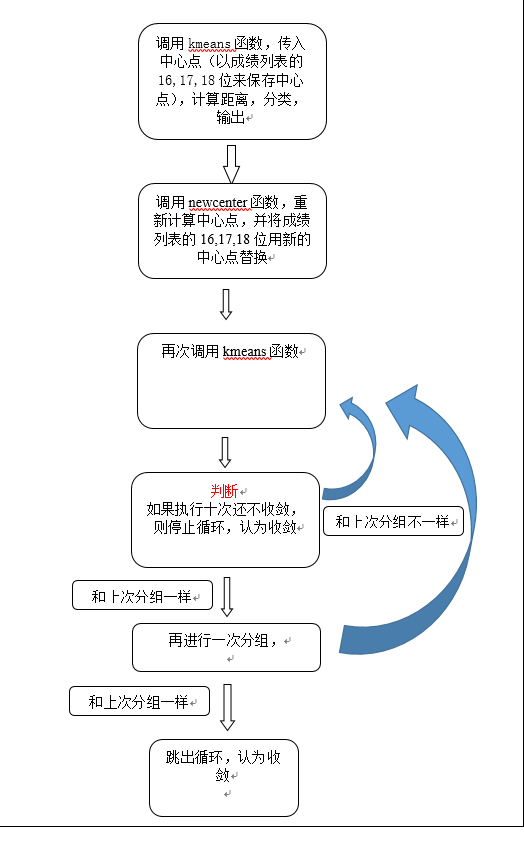
def kmeans(i, j, k,number,country): # i,j,k表示以哪几个点为种子点,number表示第几次分组,country是成绩列表
namei.clear()
namej.clear()
namek.clear()
# 将上次的分组清空
dis = []
for m in range(15):
dis.append(pow(
pow(country[m][0] - country[i][0], 2) + pow(country[m][1] - country[i][1], 2) + pow(country[m][2] - country[i][2],
2), 0.5))
# 计算country[]到中心点country[i]的距离,将距离添加到dis的列表里面
dis.append(pow(
pow(country[m][0] - country[j][0], 2) + pow(country[m][1] - country[j][1], 2) + pow(country[m][2] - country[j][2],
2), 0.5))
dis.append(pow(
pow(country[m][0] - country[k][0], 2) + pow(country[m][1] - country[k][1], 2) + pow(country[m][2] - country[k][2],
2), 0.5))
index = dis.index(min(dis)) # 找出最小值的下标
if index == 0:
groupi.append(country[m]) # 将最小值的那个国家添加到分组中去
namei.append(name[m])
if index == 1:
groupj.append(country[m])
namej.append(name[m])
if index == 2:
groupk.append(country[m])
namek.append(name[m])
dis.clear()
number = str(number)
print("第" + number + "次分组为:")
print(namei)
print(namej)
print(namek)
def newcenter(group): # 重新计算中心点
center0 = 0
center1 = 0
center2 = 0
center = []
for i in range(len(group)): # 求和
center0 = group[i][0] + center0
center1 = group[i][1] + center1
center2 = group[i][2] + center2
center.append(center0 / len(group)) # 将新的中心点的三个数据添加到列表center
center.append(center1 / len(group))
center.append(center2 / len(group))
return center
number = 1
country.append(country[1]) # 用country的16,17,18位来存放中心点
country.append(country[9])
country.append(country[12])
kmeans(15, 16, 17,number,country)
nai = namei
naj = namej
nak = namek
# 将分组读入nai,naj,nak,用于判断是否收敛
count = 1
while count <= 10: # 当运行10次,结束循环,认为收敛
number = number+1
country[15] = newcenter(groupi)
country[16] = newcenter(groupj)
country[17] = newcenter(groupk)
groupi.clear()
groupj.clear()
groupk.clear()
kmeans(15, 16, 17,number,country)
if namei == nai and namej == naj and namek == nak:
number = number + 1
country[15] = newcenter(groupi)
country[16] = newcenter(groupj)
country[17] = newcenter(groupk)
groupi.clear()
groupj.clear()
groupk.clear()
kmeans(15, 16, 17, number, country)
if namei == nai and namej == naj and namek == nak:
break
# 如果这次和上次的分组一样,则在进行一次分组,如果还是一样,跳出循环,认为收敛
count = count + 1
结果: |








 4192
4192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























