







项目背景
作为旧金山的一家个人对个人的借贷公司,Lending Club成立于2006年。他们是第一家注册为按照美国证券交易委员会SEC(Securities and Exchange Commission)的安全标准向个人提供个人贷款的借贷公司。与传统借贷机构最大的不同是,Lending Club利用网络技术打造的这个交易平台,直接连接了个人投资者和个人借贷者,通过此种方式,缩短了资金流通的细节,尤其是绕过了传统的大银行等金融机构,使得投资者和借贷者都能得到更多实惠、更快捷。对于投资者来说可以获得更好的回报,而对于借贷者来说,则可以获得相对较低的贷款利率。
盈利模式:Lending Club的利润主要来自对贷款人收取的手续费和对投资者的管理费,前者会因为贷款者个人条件的不同而有所起伏,一般为贷款总额的1.1-5%;后者则是统一对投资者收取一样的1%的管理费
特色:特别重视用户的信用记录,平均只有10%的申请通过信用记录审核。这是其能吸引到很多大的投资用户,并且风险控制和利润都取得长足进步的主要原因。其管理层的背景及其雄厚,多位金融和政界传奇人物,从其首轮融资即得到1000万美元的融资便可见其规模。
2006年成立于美国加利福利尼亚州;2014年于纽交所上市,并同时开展企业贷款服务;截止到2018年底平台累计发放贷款445亿美元,平均坏账率7.7%,年均借款利率13.38%;
LC介绍:https://www.huxiu.com/article/41472.html
文章思路:提出问题——理解数据——数据预处理——解决问题——得出结论
一 提出问题
文章主要基于Python对Lending Club信贷业务数据的分析,主要是想通过2018年Q4数据分析平台业务特点和客户群体特征,进而简要分析逾期的影响因素。
一个人是否还款可以从还款能力和还款意愿来评估。下面从两个角度进行深入分析。
1 平台角度:平台的数据指标更多构建来衡量结果的指标,简要分析了解平台整体情况。s
2 客户角度:任何可以量化客户的还款能力的信息均可以用作硬信息,可描述客户还款意愿的信息则为软信息。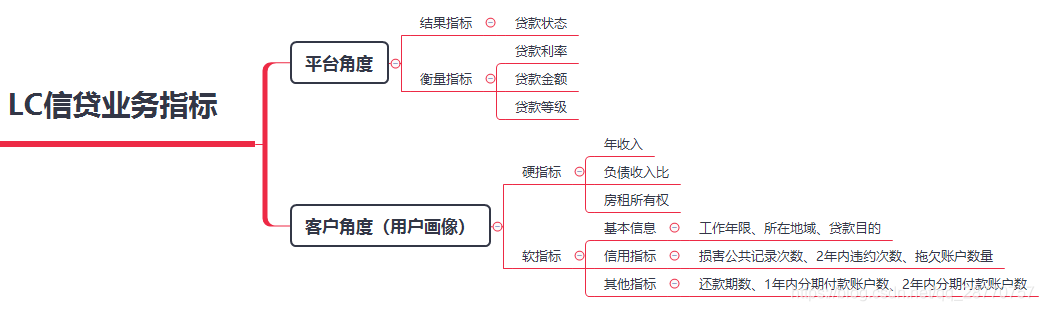
二 数据理解
数据来源LC官网:https://link.zhihu.com/?target=https%3A//www.lendingclub.com/info/download-data.action
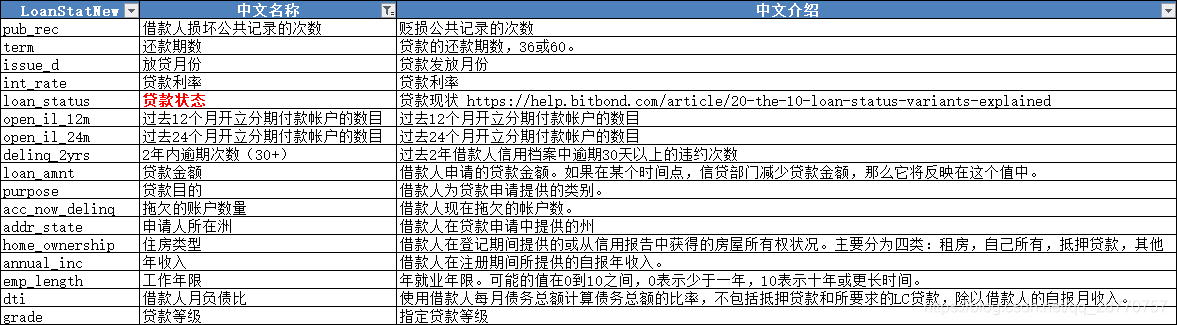
原始数据维度:103546行,145个字段。选取18个相关字典字段进行分析。
三 数据预处理
3.1 选取子集并重命名
选取子集
used_col = ['loan_status','issue_d','loan_amnt','term','int_rate','grade','annual_inc','dti','home_ownership',
'emp_length','purpose','addr_state','acc_now_delinq','pub_rec','delinq_2yrs','open_il_12m','open_il_24m']
used_data = loans[used_col]# 使用rename函数对字段重命名
used_data = used_data.rename(columns={'loan_status':'贷款状态','issue_d':'放贷日期','loan_amnt':'贷款金额',
'term':'还款期数','int_rate':'贷款利率','grade':'贷款等级',
'annual_inc':'年收入','home_ownership':'房屋所有权','dti':'负债收入比',
'emp_length':'工作年限','purpose':'贷款目的','addr_state':'申请人所在洲',
'acc_now_delinq':'拖欠账户数量','pub_rec':'损害公共记录次数',
'delinq_2yrs':'2年内违约次数','open_il_12m':'1年内分期数','open_il_24m':'2年内分期数'})
used_data2=used_data.copy() # 备份
used_data.head(3) # 查看前3行数据

3.2 处理缺失值
# 查看空值缺失值情况
def not_null_count(column):
column_null = pd.isnull(column) #判断某列属性是否存在缺失值
null = column[column_null]
return len(null)column_null_count = used_data.apply(not_null_count)
column_null_count
得知负债收入比含有28个缺失值,筛选数据来观察
used_data.loc[used_data['负债收入比'].isnull()]
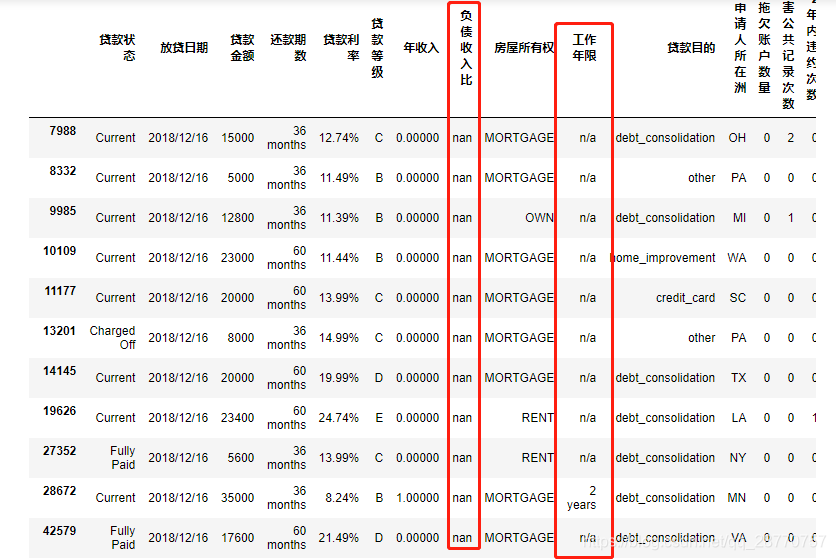
# 观察发现众多指标中,工龄为'n/a'的客户缺失比例较大,所以用其均值对nan进行填充。
# 有时候也需要0填充used_data['负债收入比'].fillna(value=0)
used_data['负债收入比'] = used_data['负债收入比'].fillna(used_data.loc[used_data['工作年限']=='n/a']['负债收入比'].mean())
# 填充后观察整体数据类型情况
used_data.info()
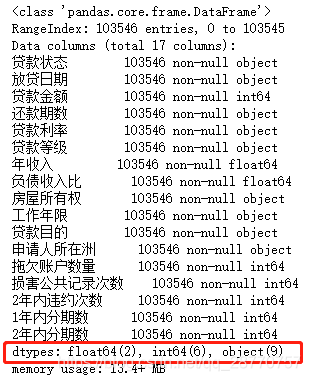
通过观察可知,数据已无缺失值;浮点型数据有2个,整型有6个,字符串有9个。
其中放贷日期可以转换为日期格式,贷款利率和工作年限可以量化,优先处理。
3.3 数据类型转换
# 字符串转日期格式
used_data['放贷日期'] = pd.to_datetime(used_data['放贷日期'],format='%Y/%m/%d')
#errors='coerce' 如果原始数据不符合日期的格式,转换后的值为空值NaT
#format 是你原始数据中日期的格式
# 特殊字符串转浮点型——贷款利率
used_data['贷款利率']= used_data['贷款利率'].str.rstrip("%").astype("float")# 特殊字符串转数值——工作年限
used_data['工作年限'].value_counts()

通过观察可知:年龄类别有12个,除小于1年('< 1 year')和空值('n/a')外,其余都可以用分列直接分列出对应的工龄,其中10+year需要二次分列。所以有两种处理方法:
1.通过函数处理方式处理,此处选择这种;
2.通过替换成对应年份的方法处理(后面类别数据会用到)。
# 1.编写函数处理方式处理
def coding_y(data_y):
codlist = []
for i in data_y:
if i == '< 1 year':
cod = 0
elif i == 'n/a':
cod = -1
else:
cod = i.split(' ')[0].split('+')[0] # 先分列空格,此时只有”10+“未处理好,需再次分列+号
codlist.append(cod)
cod_y = pd.Series(codlist)
return cod_y
used_data['工作年限'] = coding_y(used_data['工作年限']).astype('int') #调用函数并转换类型,方便可视化和统计# 查看前两行,格式已转换
used_data.head(2)

3.4 查看整体数据情况
分别从字符串和数值类型来查看整体的数据情况,把握后面分析的重点
查看字符串型数据情况
# 通过select_dtypes函数筛选出object对象的对应信息
# 可分别得到非空值数量、unique数量,最大频数变量,最大频数,以及新添加一列特征变量top_pre,表示最大变量占比
used_data_des = used_data.select_dtypes(include=['object']).describe().T
used_data_des['top_pre']=used_data_des['freq']/used_data_des['count']
used_data_des
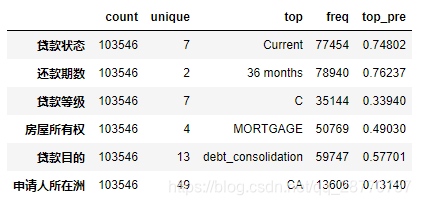
可以得出:
-
贷款状态有7种,其中Current(未结清但无逾期)占比74.8%最高;
-
还款期数有2种,36期占比76.2%,可用于多变量分析的对比参数;
-
贷款等级有7类,是LC评定客户的等级,C等级占比33.9%最高;
-
房产所以权有4种,其中按揭贷款接近一半;
-
贷款目的有13类,其中债务合并占比57.7%,俗称以贷还贷,此类型客户逾期概率高,需深入观察;
-
申请人所在洲有49个,美国共有50各州,说明LC业务量强大;其中LC的成立地区加利福尼亚州(CA)占比13%最高
查看数值型数据情况
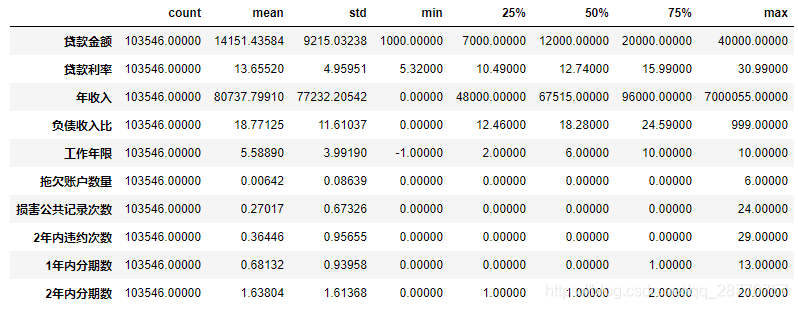
# 查看数值型数据情况
used_data.describe().T
四 解决问题
4.1 平台角度-结果指标-贷款状态分析
LC数据字典提供网站:https://help.bitbond.com/article/20-the-10-loan-status-variants-explained
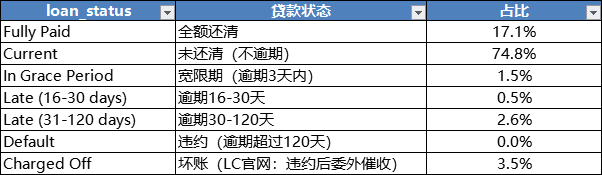
LC网站与LC字典解释有些有出入,比如说LC网站说有逾期30-90,但是LC字典只有逾期30-120比较接近;所以以下说明加入了自己的理解,不合理的欢迎指正。
综上:可根据逾期和未逾期划分贷款状态
未逾期标记为1:完全还清和部分还款客户;
逾期都标记为0:这里可以再细分宽限期和逾期
mapping_dict = {"贷款状态": {
'Current':0,'Fully Paid':0,
'Charged Off':1,'Late (31-120 days)':1,'Default':1,
'Late (16-30 days)':1,'In Grace Period':1 }
}
used_data = used_data.replace(mapping_dict)attr = ['正常', '逾期'] # 名称的顺序要和标签的顺序一致
pie = Pie("贷款状态占比")
pie.add("", attr, [int(i) for i in pd.value_counts(used_data["贷款状态"])] ,is_label_show=True)
pie
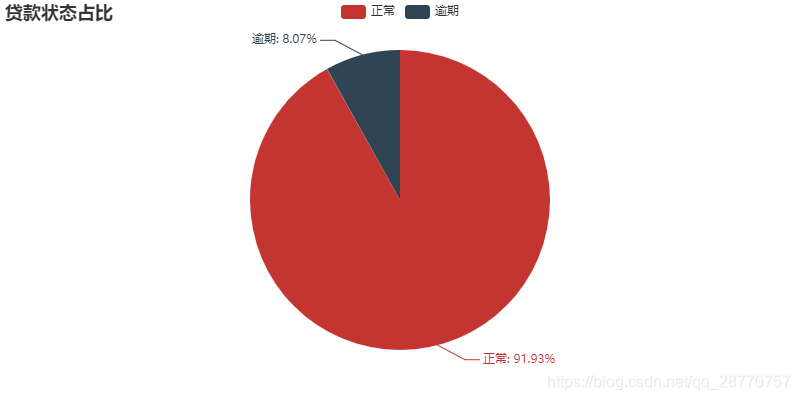
LC正常状态客户占91.93%,逾期客户占8.07%,整体情况良好;
在逾期客户中违约占比0.008%,但委外催收占比3.5%,极有可能是将逾期120天以上的贷款全部委外给催收机构。其实这在P2P或者银行中比较常见的,自身贷前袋中贷后都做的话业务有点大,尤其是贷后逾期严重的客户比较难催,一般都会委外给专业的催收机构。
4.1.1 平台角度-衡量指标-贷款利率&贷款金额
fig = plt.figure()
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
fig.set_size_inches(12,5)sns.distplot(used_data['贷款利率'],ax=ax1)
sns.distplot(used_data['贷款金额'],ax=ax2)ax1.set(xlabel='贷款利率',title='贷款利率分布',)
ax2.set(xlabel='贷款金额',title='贷款金额分布')
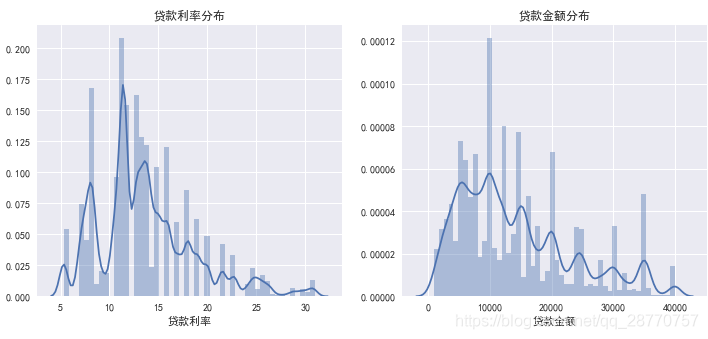
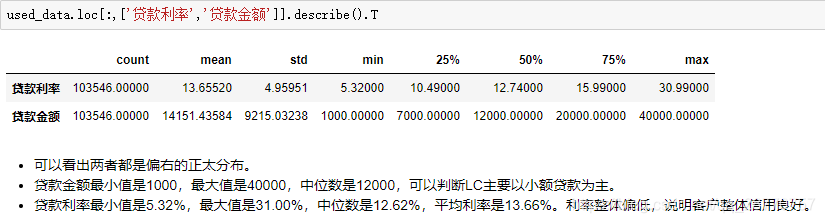
4.1.2 平台角度-衡量指标-贷款等级
# used_data['贷款等级'].value_counts() #查看等级排序
attr = ["C", "B","D","A","E","F","G"]
pie = Pie("贷款等级比例")
pie.add("", attr, [float(i) for i in pd.value_counts(used_data['贷款等级'])] ,is_label_show=True)
pie
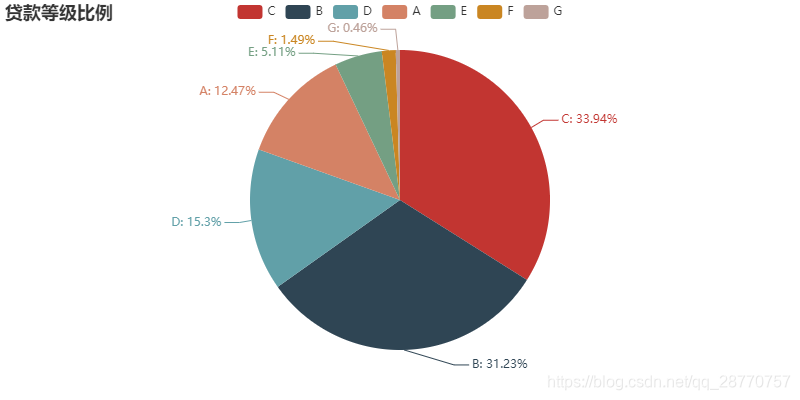
贷款等级最高的C和B,占比均在30%以上,其次是A和D,占比分别是12.5%和15.3%,前四个等级(A-D)占比高达92.9%,可见LC审核之严格.
前面得出正常还款的客户同样高达90%以上,是不是这部分客户就是A-D等级呢?逾期的客户是哪些等级呢?
# 使用 FacetGrid.map 构建结构化多绘图网格,查看不同等级下贷款状态的利率
order_dj = ['A', 'B', 'C', 'D', 'E', 'F', 'G'] # 指定贷款等级排序,方便查看等级与利率关系
g = sns.FacetGrid(used_data,row='贷款状态',col='贷款等级',col_order=order_dj)
g.map(plt.hist, "贷款利率");
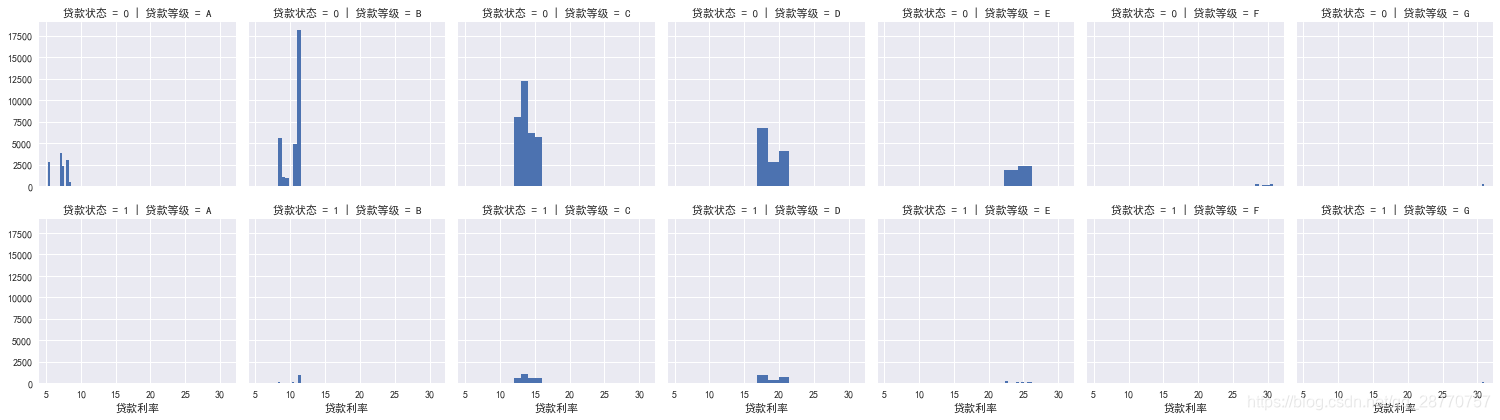
LC客户的信用等级从A-G,等级越高,贷款利率就越小(越偏向左,第一排贷款状态为0时更加直观);
其中正常客户(贷款状态=0)分布在A-E等级。可以反应出正常还款的客户客户信用好,财务状况较好,违约发生的可能性较低,因此等级越高,利率自然也相对较低。
逾期的客户(贷款状态=0)最多的等级是C和D。D等级占比是C等级的一半,但是逾期却差不多,后面需查看用户特征。
4.2 客户角度
4.2.1 硬性信贷指标:年收入、负债收入比
fig = plt.figure()
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
fig.set_size_inches(12,5)sns.distplot(used_data['年收入'],ax=ax1)
sns.distplot(used_data['负债收入比'],ax=ax2)ax1.set(xlabel='年收入',title='年收入分布')
ax2.set(xlabel='负债收入比',title='负债收入比分布')
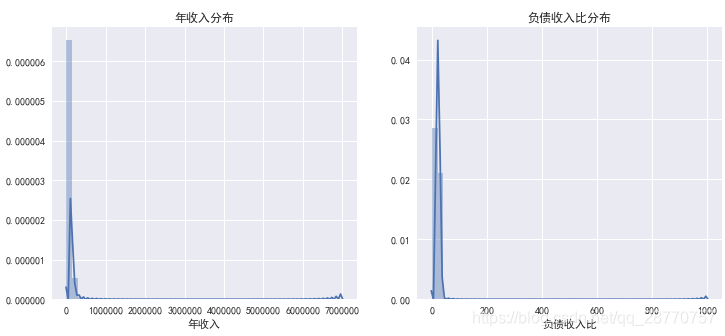
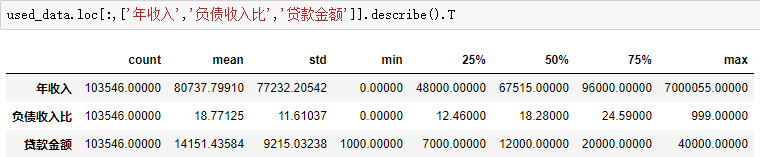
- 年收入最高为700万,均值为8万,75%低于10万。LC客户除极少部分是高收入人群外,大部分客户收入较为一般;
- 普遍认为负债务收入比40%是临界点,LC75%的客户负债收入比在24.59&以下,说明客户债务情况良好,负担债务意愿佳;
- LC以客户群体收入一般,但是负债情况良好,证明LC小额贷款的切入及客户定位都非常的精准。
4.2.1 硬性信贷指标:房租所有权
# used_data['房屋所有权'].value_counts() #查看房屋所有权排序
attr = ['住房贷款', '租房', '自己所有','其他']
pie = Pie("房屋所有权占比")
pie.add("", attr, [int(i) for i in pd.value_counts(used_data["房屋所有权"])] ,is_label_show=True)
pie
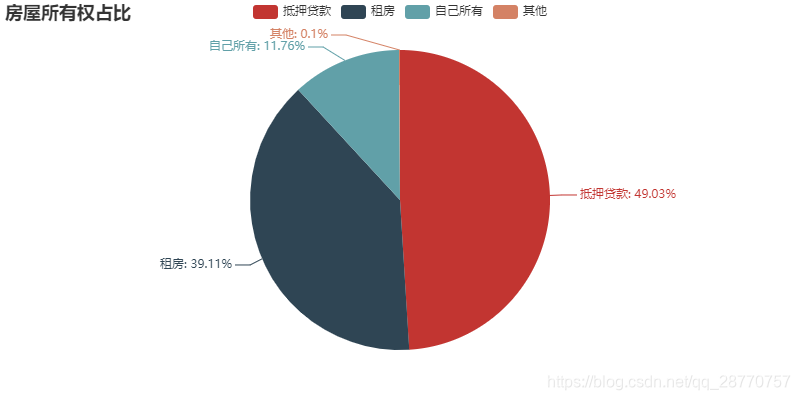
- 在住房类型种类中住房贷款和租房两者占比88%以上,说明LC客户群体定位比较精准。
- 住房贷款占比高达49.03%,这部分客户负债较高,个人的资金流动差,更容易贷款;
- 其次是租房39.11%,租房客户贷款说明客户群体较为普通,也即有可能是刚出社会不久的年轻人,收入较低支出较大,更容易贷款。
4.2.2 软性信贷指标:工作年限
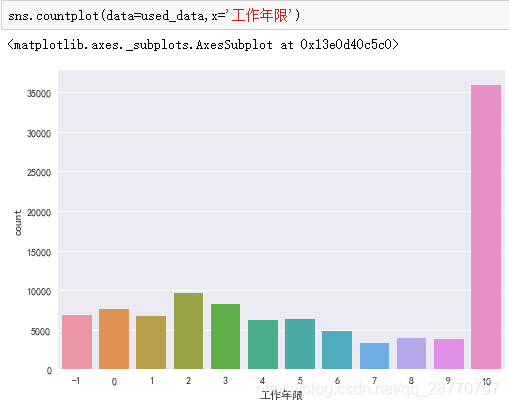
- 工作超过10的客户远远高于其他年限,这部分人群成家立业,家庭开支房贷等支出大,经济压力大,是LC贷款客户的最大群体。
- 其次下来是年限在2-3稍微高于其他年限,而且6-9年占比较低,可以看出消费需求大没有多少积蓄的职场新人也是LC的重要群体之一。
4.2.2 软性信贷指标:地域(申请人所在州)
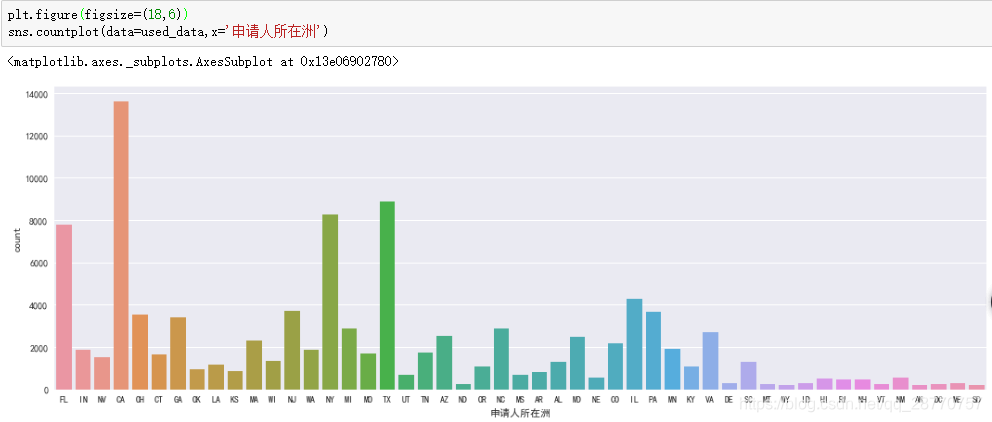
- 客户占比最高的地区是LC的成立地区加利福尼亚州CA,世界知名的“好莱坞”和“硅谷”均在州内,经济活跃,消费能力强;
- 其次是纽约NY,德克萨斯州TX,佛罗里达州FL等东南沿海发达地区,排在后面的也是沿海发达地区居多,客户普遍经济能力强,金融意识强。
- LC公司客户地区多分布在沿海经济发达地区。
软性信贷指标:贷款目的
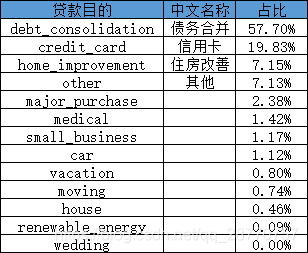
- 57.7%的客户贷款目的是为了债务合并,19.8%是信用卡还款,近8成的客户是以贷还贷的,一旦资金异常,逾期概率就会很高。
4.2.3 信用指标:损害公共记录次数2年内违约次数/拖欠账户数量
fig = plt.figure()
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
fig.set_size_inches(18,5)
sns.countplot(used_data['损害公共记录次数'].sort_values(),ax=ax1)
sns.countplot(used_data['2年内违约次数'].sort_values(),ax=ax2)
sns.countplot(used_data['拖欠账户数量'].sort_values(),ax=ax3)ax1.set(xlabel='损害公共记录次数',title='损害公共记录次数分布')
ax2.set(xlabel='2年内违约次数',title='2年内违约次数分布')
ax3.set(xlabel='拖欠账户数量',title='拖欠账户数量分布')
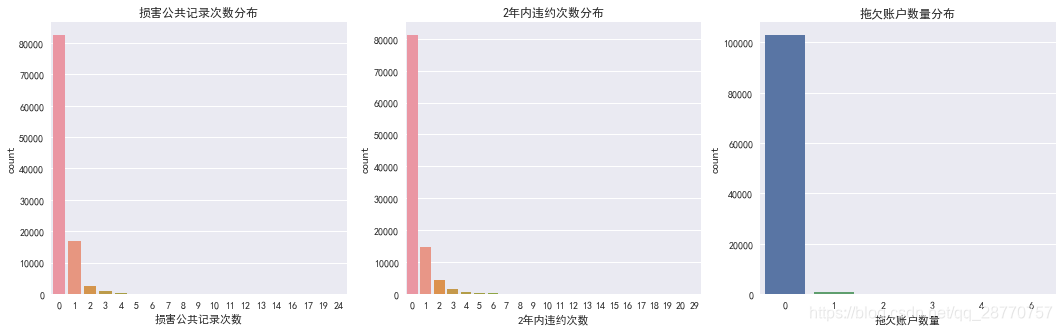
- 超过80%的客户无损害公共记录次数和2年内违约次数,拖欠账户数量几乎没有,可见平台客户信用非常好。
4.2.4 其他指标:还款期数/1年内开立分期付款帐户的数目/1年内开立分期付款帐户的数目
sns.lmplot(x="1年内开立分期付款帐户的数目", y="2年内开立分期付款帐户的数目", col="还款期数", hue="贷款状态", markers=["o", "x"], palette="Set1",data=used_data);
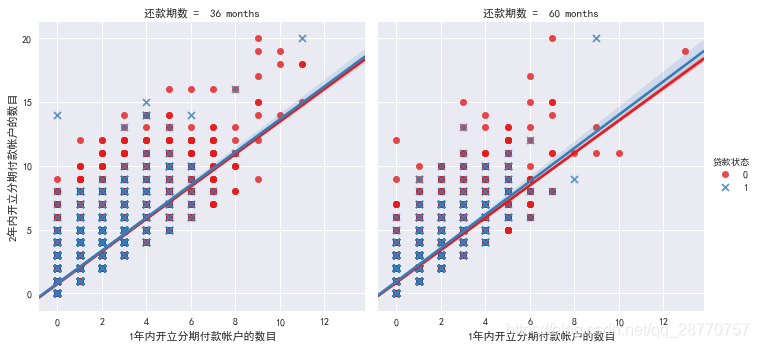
- 可以看到1年内开立分期付款帐户的数目和2年内开立分期付款帐户的数目成正相关;
- 逾期客户开户分期数少,正常的客户开户分期数多,可以作为区分是否逾期的一个特征。
结论
平台运营特点
- 平台整体运营情况良好,正常客户占91.93%,逾期客户占8.07%。
- 平台以小额贷款为主,借款金额主要集中在中位数1.2万前后;
- 平台贷款利率相比于传统金融机构偏高,平均利率为13.66%,最高达30.99%;
- 平台7个贷款等级中前四占比92.9%,正常客户集中在前5等级,逾期客户集中在C、D等级。
客户群体特征
综上,评估LC客户的还款能力和还款意愿
硬性评估:平台客户群体以中产阶级为中坚力量,49%的客户贷款买房、12%的可以有自己的房产。财务状况、负债情况良好,整体还款能力不错;
软性评估:平台客户工龄以10年以上为主,主要集中在CA,NY等沿海经济发达地区,都有一定的家庭和社会地位;近8成客户以贷还贷,而且超过80%的客户无损害公共记录次数和2年内违约次数等,信用良好。
家庭社会地位,以贷还贷,信用良好逾期概率小等等都能够反映LC客户的偿还意愿比较好。
影响客户逾期的因素更多要从客户角度去分析指标,上面提到的客户角度的指标都是可以作为参考的指标。可以在贷前做用户画像,评分卡,建模等方式来评估。
本篇主要基于LC信贷数据简要分析平台业务特点和客户特征,初步判断影响逾期的因素,未做深入相关性分析,还有诸多不足之处,后续慢慢完善。

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









