






谷歌开源其用于AI生成文本的水印工具
图片由Jim Clyde Monge提供
近年来,互联网上由AI生成内容引发的错误信息传播已成为一个重大问题。尽管已经有许多尝试来检测AI生成的内容,但尚未出现高精度的工具。
甚至OpenAI也停止了其AI分类器,原因是检测AI和人类书写文本的准确率较低。
我们正在努力整合反馈,并目前正在研究更有效的文本溯源技术,并承诺开发和部署使用户能够了解音频或视觉内容是否由AI生成的机制。——OpenAI
现在,谷歌通过开源其自己的工具SynthID来应对错误信息的挑战,这是一种设计用于检测AI生成内容的工具。
什么是SynthID?
SynthID是谷歌DeepMind的一项技术,通过直接将数字水印嵌入到AI生成的图像、音频、文本或视频中来标记和识别AI生成的内容。
这会影响生成的质量或速度吗?
根据谷歌的说法,SynthID不会影响由Gemini创建的生成文本的质量、准确性、创造力或速度。
谷歌还通过其负责任生成式AI工具包开源了这项技术,提供了创建更安全AI应用程序的指导和基本工具。
该技术在谷歌的负责任生成式AI工具包中可用,也可在Hugging Face上访问,这使开发人员能够负责任地在其AI应用程序中嵌入和检测水印变得更加容易。
SynthID如何工作
生成式水印提供了一种解决方案,在生成过程中微妙地嵌入可识别标记,使得无需访问LLM本身即可进行检测,同时不影响质量。
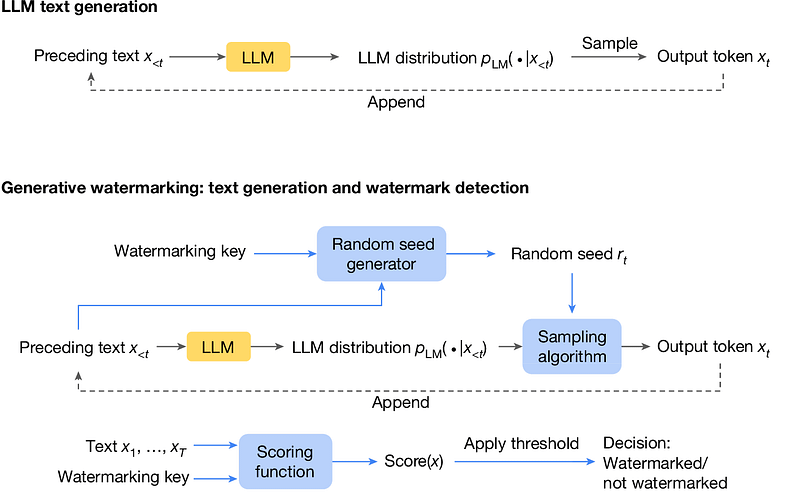
在实践中,它在模型生成管道中的工作原理如下:
图片来自Nature.com
- 标准文本生成:在架构的顶部部分,标准LLM文本生成按顺序从左到右生成标记,每个标记从LLM的概率分布中采样,基于前面的上下文。
- 水印集成:在架构底部部分,引入了一个生成式水印系统,其中包括三个关键组件:随机种子生成器、采样算法和评分函数。
这些元素协同工作,通过SynthID-Text方法中的锦标赛采样算法实现水印嵌入文本生成和检测。
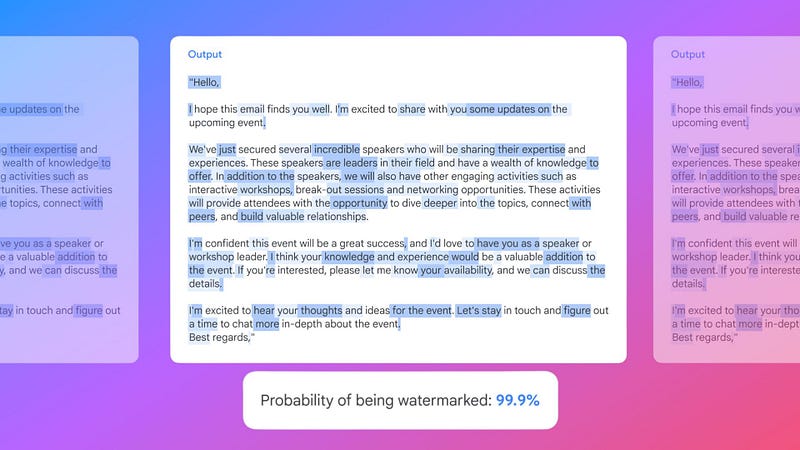
例如,如果你要求Gemini使你的电子邮件听起来更专业,带有水印的修订版本可能如下所示:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
图片来自谷歌
这段文字的概率为99.9%。
你可以从以下Nature技术论文中了解更多关于SynthID的信息。
[
可扩展的大语言模型输出识别水印 - Nature
大语言模型(LLMs)已实现高质量合成文本的生成,通常难以区分…
www.nature.com
](https://www.nature.com/articles/s41586-024-08025-4)
应用水印
要嵌入水印,SynthID Text充当模型生成管道内的logits处理器。它使用伪随机g函数修改模型logits以编码水印信息,在确保生成文本质量和水印可检测性之间取得平衡。
通过参数化g函数并控制其在文本生成过程中的应用来配置水印。
以下是一个示例配置:
{
"ngram_len": 5,
"keys": [654, 400, 836, 123, 340, 443, 597, 160, 57, 29, 590, 639, 13, 715, 468, 990, 966, 226, 324, 585, 118, 504, 421, 521, 129, 669, 732, 225, 90, 960],
"sampling_table_size": 65536,
"sampling_table_seed": 0,
"context_history_size": 1024
}
要应用水印,请初始化SynthIDTextWatermarkingConfig并将其作为watermarking_config参数传递给.generate()方法,如下所示:
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
SynthIDTextWatermarkingConfig,
)
# 初始化模型和分词器
tokenizer = AutoTokenizer.from_pretrained('repo/id')
model = AutoModelForCausalLM.from_pretrained('repo/id')
# 设置SynthID Text水印配置
watermarking_config = SynthIDTextWatermarkingConfig(
ngram_len=5,
keys=[654, 400, 836, 123, 340, 443, 597, 160, 57, 29, 590, 639, 13,715 ,468 ,990 ,966 ,226 ,324 ,585 ,118 ,504 ,421 ,521 ,129 ,669 ,732 ,225 ,90 ,960],
sampling_table_size=65536,
sampling_table_seed=0,
context_history_size=1024
)
# 使用水印配置生成文本
tokenized_prompts = tokenizer(["your prompts here"])
output_sequences = model.generate(
**tokenized_prompts,
watermarking_config=watermarking_config,
do_sample=True,
)
watermarked_text = tokenizer.batch_decode(output_sequences)
此设置允许嵌入SynthID水印文本的生成,确保可检测性,同时保持输出质量。
检测水印
水印设计为可被训练分类器检测,同时对人类读者保持不可见。每个应用于你模型的水印配置都需要一个专门训练过的检测器来识别其唯一标记。
训练检测器的基本过程如下:
1.选择一个水印配置。
2.收集至少10K个示例组成的检测器训练集,分为带水印和不带水印以及训练或测试。
3.使用你的模型生成不带水印的输出。
4.使用你的模型生成带有水印的输出。
5.使用此数据集训练一个水印检测分类器。
6.部署带有配置好的水印系统和训练好的检测器模型。
Transformers提供了一个贝叶斯检测器类,以及一个end-to-end示例,用于训练一个识别特定配置下带有水印文本的检测器。
如果多个模型使用相同的分词器,只要检测器训练集包含所有相关模型的样本,它们就可以共享相同的水印配置和检测器。
如何试用SynthID
为了帮助你更好地理解如何进行水印,我们来做一些示例。有三种方式可以做到这一点:
1.使用这个Google Colab Notebook在你的浏览器上运行SynthID。
2.在HuggingFace上使用这个空间运行SynthID。
3.在你的本地机器上运行SynthID。强烈建议本地使用虚拟环境。
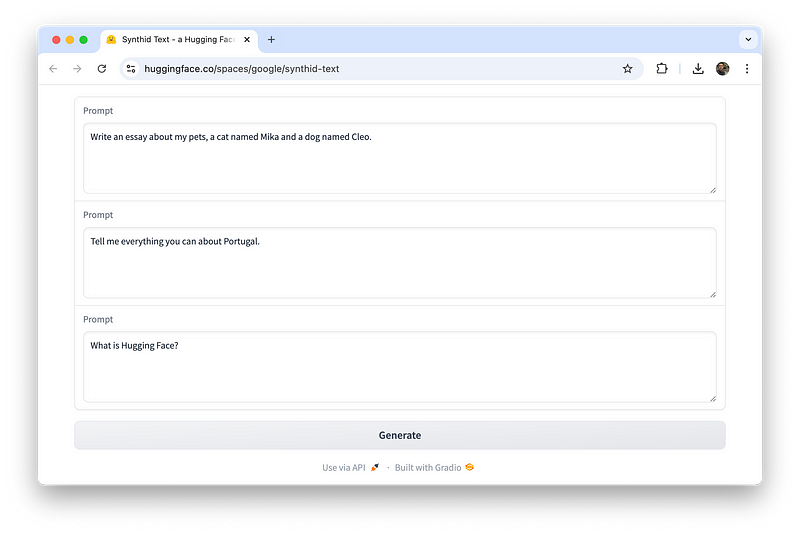
最简单的方法是在HuggingFace上尝试SynthID,但谷歌当前提供的SynthID空间似乎无法正常工作。为了给你一个概念,请前往这个Hugging Face空间并尝试输入一些文本提示。
图片由Jim Clyde Monge提供
输入最多三个提示,然后点击“生成”按钮。
以下是一个示例:
提示1: 写一篇关于我宠物的小猫Mika和小狗Cleo的文章。
提示2: 告诉我关于葡萄牙的一切。
提示3: Hugging Face是什么?
Gemma将为你提供每个非空提示对应的带有水印和不带有水印的响应。
现在,让我们尝试这个免费的Google Colab Notebook在浏览器上测试SynthID。
图片由Jim Clyde Monge提供
这个notebook演示了如何使用SynthID Text库应用和检测生成文本上的水印。
它分为三个主要部分,并打算从头到尾运行完毕。
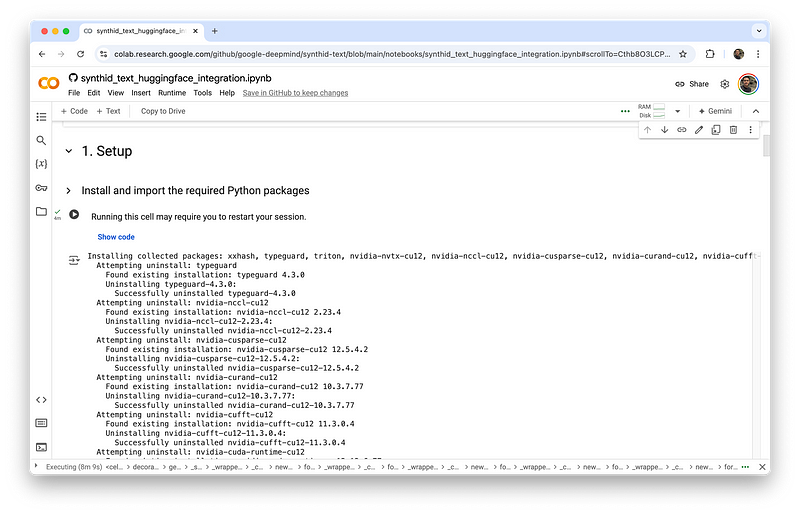
- 设置:导入SynthID Text库,选择你的模型(Gemma或GPT-2)和设备(取决于你的运行时,可以是CPU或GPU),定义水印配置,并初始化一些辅助函数。
- 应用水印:使用Hugging Face Transformers库加载你选择的模型,使用该模型生成一些带有水印的文本,并比较带有水印文本与基础模型生成文本之间的困惑度。
- 检测水印:训练一个检测器来识别带有特定水印配置下生成的文本,然后使用该检测器预测一组示例是否由该配置下生成。
对于每一步,在左侧点击小小播放按钮并等待出现绿色勾号。这表明该过程已成功完成。

图片由Jim Clyde Monge提供
在“选择你的模型”步骤中,你需要从HuggingFace获得一个令牌,以便Google Notebook下载所需模型。
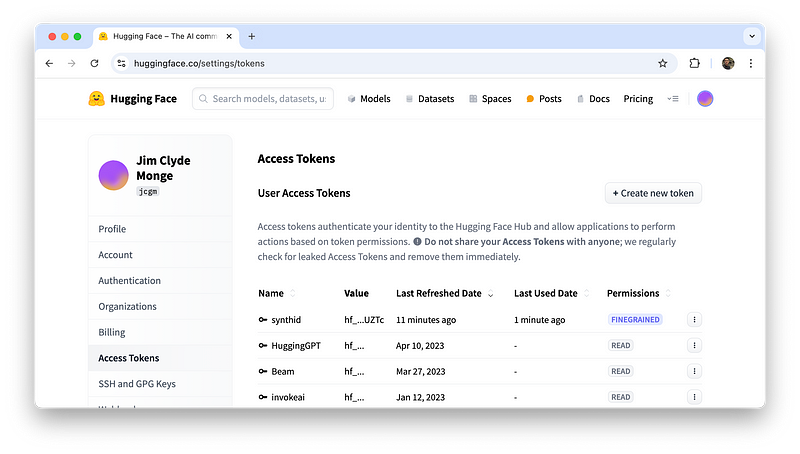
图片由Jim Clyde Monge提供
确保编辑令牌权限以允许访问某些存储库。
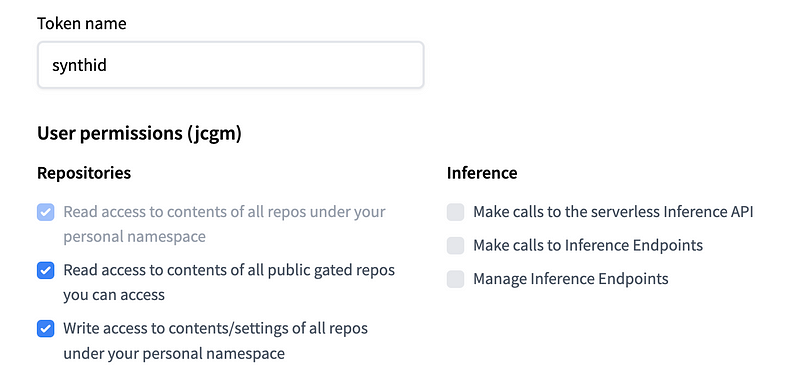
图片由Jim Clyde Monge提供
要本地运行SynthID,请按照GitHub存储库上描述步骤操作。
并非完美解决方案
SynthID文本水印对某些转换具有鲁棒性,例如裁剪部分文本、修改几个单词或轻微改写。然而,它也存在一些局限性:
- 模型依赖性:SynthID仅适用于谷歌Gemini模型。
- 编辑精度下降:用另一个AI或通过广泛改写编辑带有水印的内容会降低检测精度。
- 翻译敏感性:翻译或大量改写可能会使水印的可检测性消失。
最终思考
看到像谷歌这样的科技巨头找到控制AI聊天机器人引发的错误信息传播的方法,同时发布强大的语言模型,这确实令人鼓舞。这里有点讽刺意味,但我理解他们这样做是为了在竞争激烈的市场中保持领先地位。
值得注意的是,SynthID仅适用于谷歌的语言模型。尝试将其用于Claude或ChatGPT生成的文本,结果可能不准确。这是开发人员和普通用户需要注意的重要限制。SynthID并不能提供解决错误信息的完美方案。
我希望其他科技公司如OpenAI、Anthropic或亚马逊也能开发自己的AI内容水印工具。这将有助于减少互联网上AI生成内容的传播,并帮助研究和学术领域的专业人士。
作为开发人员,我还没有尝试过SynthID,但我计划进行一些实验,看看它在使用Gemini创建的应用程序上的效果如何,以及是否对性能和输出质量产生影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









