







1.数据准备:
这里的实验数据是本人自己提取的,具体方式是:
(大家可以根据自己喜好进行如下步骤)
1.选取3个不同类别的文本,每类500篇,共1500篇。
2.使用TF-IDF或词频等方式,从每个类型的文本中选出100个特征词,3个类别,共300个特征词。将300个特征词存入一个list中。
3.使用300个特征词的列表去遍历每一篇文本,如果第x个特征词在该文本中出现次数为n,则对应该文本的特征list的第x为记为n。1500篇文本,1500个特征list分别对应每个文本。
4.对每个文本设置标签,使用one-hot方式表示即可
5.将其文本顺序打乱即可,但保证其对应关系不变 文本——文本特征list——标签
例如:
这里我使用TF-IDF从3个不同类别的文本中提取到的300个特征词:

我们甚至可以从这些词中看出这三类文本的类别分别为:房产,星座,游戏
当然,有些词的区分性不是太好,我们可以通过增加文本数量,设置更精确的停用词实现更好的效果。
提取一篇文本的特征list:
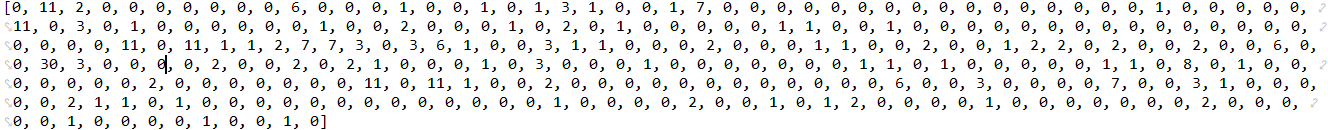
文本特征list的每一位与特征词list的每一位一一对应,例如文本特征list[1]=11,对应特征词list[1]=“一个”,即表示"一个"这个词在该文本中出现11次。
再对这篇文本设置标签:
[0, 1, 0]
表明该文本属于第二类。
2.代码实现:
这里使用RNN中LSTM进行实验,对于RNN以及其LSTM就不做讲解 (我感觉我也不一定能讲解得比其他人清楚),这里就推荐我感觉还不错的几个相关参考:
深度学习基础(六):LSTM模型及原理介绍
Tensorflow 实践RNN(一)
第十四章——循环神经网络(Recurrent Neural Networks)
BiliBili视频 深度学习框架Tensorflow学习与应用
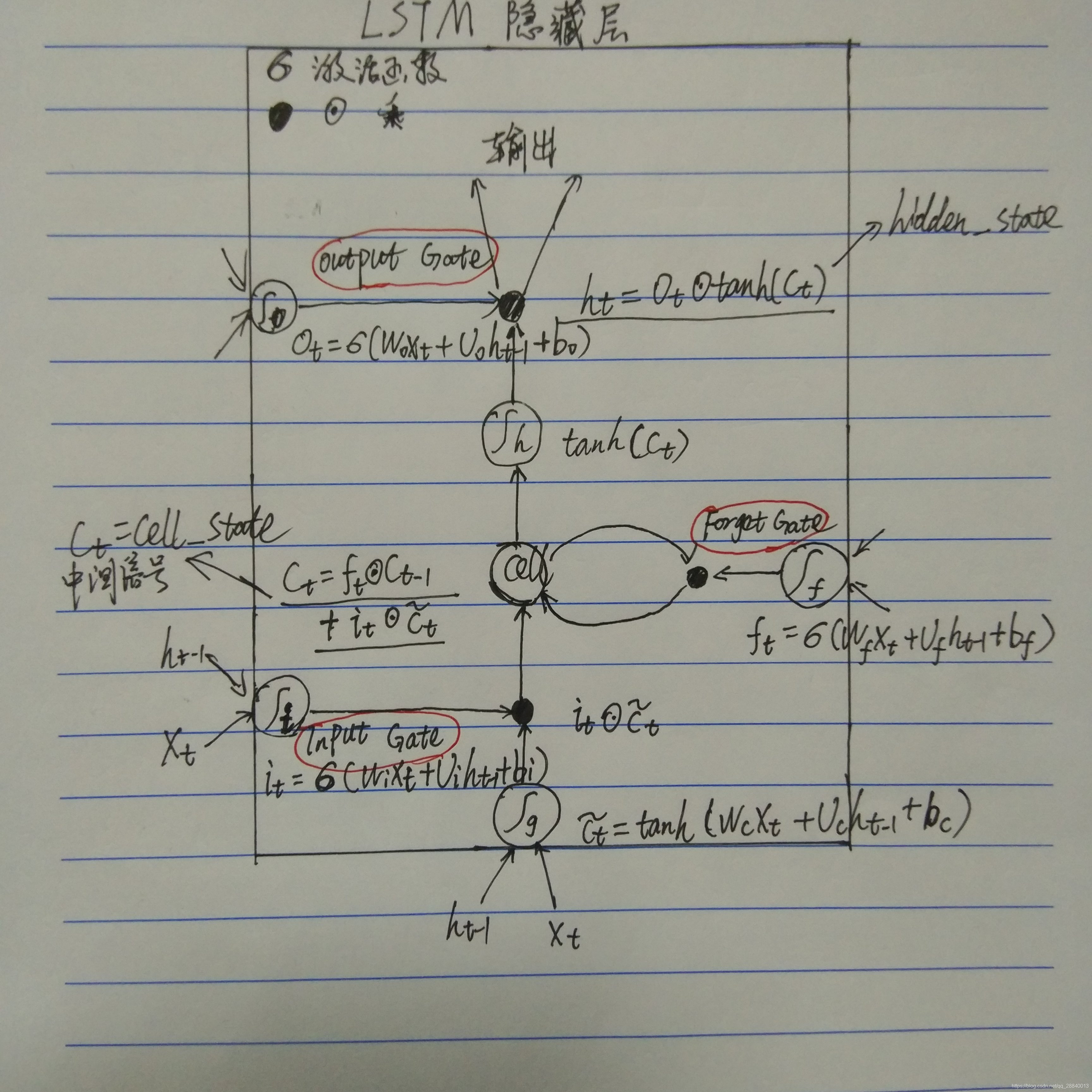
对于LSTM隐藏层,大家可以将上述文本结合下图进行理解:

代码及注释:
import tensorflow as tf
import dataN #这里是自己写的获取数据的python文件,可以获取到1200个训练数据,训练标签。300个测试数据,测试标签
train_dataN,train_labelN,test_dataN,test_labelN=dataN.dataone()
n_input=10 #一行10个数据,输入一行
max_time=30 #一共30行,每个数据分为30次传入
lstm_size=50 #隐藏层单元数
n_classes=3 #3个类别
batch_size=10 #每次10个样本
n_batch=int(len(train_dataN)/batch_size) #一共分为多少个批次
x=tf.placeholder(tf.float32,[None,300])
#None表示一次传入数据的个数未知,他会根据实际情况自动设置
y=tf.placeholder(tf.float32,[None,3])
weights=tf.Variable(tf.truncated_normal([lstm_size,n_classes],stddev=0.1)) #[100,3]
biases=tf.Variable(tf.constant(0.1,shape=[n_classes]))
def RNN(x,wights,biases):
inputs=tf.reshape(x,[-1,max_time,n_input]) #[批数量,30,10]
lstm_cell=tf.contrib.rnn.BasicLSTMCell(lstm_size)
#定义LSTM基本cell(基本隐藏层单元结构,这里选用BasicLSTMCell,当然还有其它选项可以自行了解)
# BasicRNNCell(num_units,activation=None,reuse=None)
# num_units: int, 隐层个数。activation: 非线性激活函数 默认: tanh。reuse: (optional)不管
outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32)
#tf.nn.dynamic_rnndynamic_rnn(cell,inputs,sequence_length=None,initial_state=None,dtype=None,parallel_iterations=None,swap_memory=False,time_major=False,scope=None)
# cell:需要传入tf.nn.rnn_cell空间下的某一类rnn的实例,再本例中,传入了tf.nn.rnn_cell.BasicRNNCell(hidden_num),一个包含hidden_num个隐层单元的基本RNN单元。
# inputs:输入数据
# 如果 time_major == False (default) input的形状必须为 [batch_size, sequence_length, frame_size]
# 如果 time_major == True input输入的形状必须为 [sequence_length, batch_size, frame_size]
# 其中batch_size是批大小,sequence_length是每个序列的大小,而frame_size是序列里面每个分量的大小(可以是shape,例如[3,4])
# sequence_length:序列的长度,如果指定了这个参数,那么tf会对长度不够的输入在尾部填0。
# initial_state:初始化状态(可选), 需要是一个[batch_size, cell.state_size]形状的tensor.一般初始化为0。
# 函数返回:一个 outputs, state的tuple:
# outputs: RNN输出tensor:
# 如果 time_major == False (default) outputs的形状为:[batch_size, sequence_length, cell.output_size]
# 如果 time_major == True outputs的形状: [sequence_length, batch_size, cell.output_size].
# 其中cell是刚刚传入的第一个参数的cell.
# state[0]是cell_state
# state[1]是hidden_state,见上图,hidden_state也即是当前隐藏层的输出即output
result=tf.nn.softmax(tf.matmul(final_state[1],wights)+biases)
return result
prediction=RNN(x,weights,biases)
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y)) #损失函数
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #学习率为1e-4,使用基于梯度下降的方式最小化交叉熵
correct_predict=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1)) # argmax 1表示一行中最大值的下标,0表示一列中最大值的下标
accuracy=tf.reduce_mean(tf.cast(correct_predict,tf.float32)) #将结构化为float类型
init=tf.global_variables_initializer() #初始化
with tf.Session() as sess:
sess.run(init)
for i in range(n_batch): #共1200个训练数据,这里10个为1批次batch 进行训练
TrainData_batch=train_dataN[i*batch_size:(i+1)*n_batch]
TrainData_label=train_labelN[i*batch_size:(i+1)*n_batch]
sess.run(train_step,feed_dict={x:TrainData_batch,y:TrainData_label})
print("正确率为: ")
print(sess.run(accuracy, feed_dict={x: test_dataN, y: test_labelN}))
#训练完成后,一次性将所有测试数据传入进行测试,得到总的正确率。
运行结果:
通过测试,我得到的测试数据总的正确率为50%~70%左右。

对这个结果,我是不太满意的,RNN这样的算法相对于普通神经网络,卷积神经网络CNN反而产生了更差的结果,这让我产生了疑惑,问题出在了哪?
3.相关思考总结
1.在LSTM中,time_major是指什么?不同输入输出的形状有什么不同之处?
time_major的参数说明:
time_major: The shape format of the inputs and outputs Tensors. If true, these Tensors must be shaped [max_time, batch_size, depth]. If false, these Tensors must be shaped [batch_size, max_time, depth]. Using time_major = True is a bit more efficient because it avoids transposes at the beginning and end of the RNN calculation. However, most TensorFlow data is batch-major, so by default this function accepts input and emits output in batch-major form.
即当time_major == False,output形状为 [批数量,每个数据行数,cell.output_size]
当time_major ==Ture,output形状为 [每个数据行数,批数量,cell.output_size]
我们发现,仅仅是输出数据[0],[1]位发生了交换,同样input也是如此,那这样的交换是为什么呢?
其参数大概是这样的说明:使用time_major = True更有效,因为它避免了RNN计算开始和结束时的转置。 但是,大多数TensorFlow数据都是批处理主数据,因此默认情况下,此函数接受输入并以批处理主体形式发出输出。
我的理解是:time_major是用来适配输入输出参数的形状(是否是批量操作)
那如果将上述代码(批量处理),中配置time_major = True(默认为False,批量),会发生什么?
喔,产生了一条关于数据格式错误的报错,那说明time_major的确决定了输入输出参数的形状:

但上述所说 使用time_major = True避免了RNN计算开始和结束时的转置,这个转置如何理解?希望有知晓的大佬分享一下。
2.为什么通过上述代码LSTM进行文本分类反而得到了更差的结果?
对此我的猜测为:
1.输入的训练数据为随机数据,并没有对RNN这样逐层加深的网络产生很好的效果
2.我们知道神经网络批量处理得到的批量的权重和偏置,再将这批量的权重和偏置进行迭代,或许LSTM中并没有或没有很好的迭代方式。
3.或者,LSTM中 X(t)总是需要依赖前一个结果Y(t-1)去得到Y(t),即它的每个数据是线性的,相互依赖的。
带着这些疑问,我做了另一个实验,将数据进行逐个传入,让其逐个更新权值(之前是批处理),代码如下:
(只需要修改传入数据的格式和计算准确率的方式即可)
import tensorflow as tf
import dataN #这里是自己写的获取数据的python文件,可以获取到1200个训练数据,训练标签。300个测试数据,测试标签
train_dataN,train_labelN,test_dataN,test_labelN=dataN.dataone()
n_input=10 #一行10个数据,输入一行
max_time=30 #一共30行,每个数据分为30次传入
lstm_size=50 #隐藏层单元数
n_classes=3 #3个类别
x=tf.placeholder(tf.float32,[None,300])
y=tf.placeholder(tf.float32,[None,3])
weights=tf.Variable(tf.truncated_normal([lstm_size,n_classes],stddev=0.1))
biases=tf.Variable(tf.constant(0.1,shape=[n_classes]))
def RNN(x,weights,biases):
inputs=tf.reshape(x,[-1,max_time,n_input]) #[10*30]
lstm_cell=tf.contrib.rnn.BasicLSTMCell(lstm_size)
#tf.nn.rnn_cell.BasicRNNCell(num_units,activation=None,reuse=None)
#num_units: int, 隐层个数。activation: 非线性激活函数 默认: tanh。reuse: (optional)不管
outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32)
#tf.nn.dynamic_rnndynamic_rnn(cell,inputs,sequence_length=None,initial_state=None,dtype=None,parallel_iterations=None,swap_memory=False,time_major=False,scope=None)
#cell:需要传入tf.nn.rnn_cell空间下的某一类rnn的实例,再本例中,传入了tf.nn.rnn_cell.BasicRNNCell(hidden_num),一个包含hidden_num个隐层单元的基本RNN单元。
#inputs:输入数据
#如果 time_major == False (default) input的形状必须为 [batch_size, sequence_length, frame_size]
#如果 time_major == True input输入的形状必须为 [sequence_length, batch_size, frame_size]
#其中batch_size是批大小,sequence_length是每个序列的大小,而frame_size是序列里面每个分量的大小(可以是shape,例如[3,4])
#sequence_length:序列的长度,如果指定了这个参数,那么tf会对长度不够的输入在尾部填0。
#initial_state:初始化状态(可选), 需要是一个[batch_size, cell.state_size]形状的tensor.一般初始化为0。
#函数返回:一个 outputs, state的tuple:
#outputs: RNN输出tensor:
#如果 time_major == False (default) outputs的形状为:[batch_size, sequence_length, cell.output_size]
#如果 time_major == True outputs的形状: [sequence_length, batch_size, cell.output_size].
#其中cell是刚刚传入的第一个参数的cell.
#state[0]是cell_state
#state[1]是hidden_state
results=tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)
return results
prediction=RNN(x,weights,biases)
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y))
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
saver=tf.train.Saver()
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(len(train_dataN)):
sess.run(train_step,feed_dict={x:[train_dataN[i]],y:[train_labelN[i]]})
acc=0
for t in range(len(test_dataN)):
pre=sess.run(prediction,feed_dict={x:[test_dataN[t]],y:[test_labelN[t]]})
pre_index_max = 0 #初始化最大值下标
label_index_max=0
pre=pre.tolist()
for q in range(3):
if (pre[0][q]>pre[0][pre_index_max]):
pre_index_max=q
for p in range(3):
if (test_labelN[t][p]>test_labelN[t][label_index_max]):
label_index_max = p
if (pre_index_max==label_index_max):
acc+=1
print(acc/300)
最后得到了 75% 的准确率,比批处理的有了更高的准确率。
对此又产生了一个问题 批训练(batch)与逐个数据训练对结果的影响有多大?(这里就暂不讨论这个问题了,我对这个问题的理解可以查看:深度学习中批训练(batch)与逐个数据训练对结果的影响的思考(无实验) )
对于其它猜测,由于太麻烦,就懒得实验了。在询问了一些大佬后,得到“确实会对结果造成影响的答复”。
如果大家有其它看法和理解,可以在评论区讨论。















 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









