










最近在学习NLP(自然语言处理),于是先看了看都有神马包可以使用,查了一遍网上说是NLTK包,下载了然后才想到我是要学中文的自然语言处理,于是就想看看专门处理中文的包有哪些。
又是一番搜索,我找到了网络大神们目前比较推崇的结巴分词(jieba),下载下来试了一下,感觉分词功能不错,于是写篇文章记录一下。
我用的是centos7的虚拟机,已经安装了anaconda3(后文会解释安装centos7虚拟系统的曲折经历),下载结巴分词有如下几种方式:
1、全自动安装:
easy_install jieba
或者
pip install jieba
/
pip3 install jieba(我是全自动安装的)
3、手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
然后用root用户在终端直接进入python,进入python命令行页面。
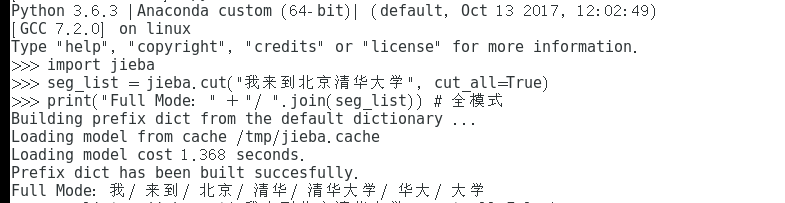

代码示例如下(记得每次在print出结果之前,都需要对变量重新赋值):
# encoding=utf-8
import jieba
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
目前就是刚刚上手,如何具体应用可能还需要跟nltk一起钻研后才能给出,我会在下一篇文章中做更深层次的说明。















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









