







观察了最近发的文章的数据,发现大家对深度学习这个领域特别感兴趣。于是希望能够用一篇文章概述一下深度学习,从深度学习里面的主要概念出发。不炫技数学,点到为止,理解至上。为了叙述更清楚,后文中灰色字体会稍微涉及到数学概念,但是灰色字体不看也不影响全文理解。
如果你想要学习深度学习,不妨收藏这一篇文章,等你具体接触到某一具体领域的时候,回过头来看,说不定会有不同的理解。
什么是深度学习?
什么是深度学习,深度体现在哪?又为什么叫做学习?今天我尝试用一篇文章讲明白深度学习。
放心食用,不含任何高深数学——
首先,深度学习来源于对大脑的仿生学。
想象一个脑细胞是如何工作的:接收来自其他脑细胞电信号的刺激,当刺激达到一定程度会被激活,然后将一定强度的电信号传给别的脑细胞。
这就是最简单的神经元模型M-P模型,在讲深度学习发展史那一期当中讲过。
其中,当前神经元接收来自别的神经元的传递的电信号,当同时接收的电信号达到一定的阈值,产生输出,把电信号传递给下一个神经元。(以下叙述中,脑细胞=神经元)
这是一个非常理所当然的设想,这就好比你的神经元本来都在摸鱼,处于一个peace状态,突然你的脑袋被打了一下,于是一系列神经元细胞被依次激活,某个信号通路被打通,你感觉到了疼。
从这个角度理解,单个神经元模型在数学上就只是一个简单的线性模型而已。 意思就是一个神经元接收来自多个其他地方的信号,这些信号的累加决定这个神经元发送出的信号。
而深度学习,就是很多个这样的神经元真的像脑神经一样的叠加:
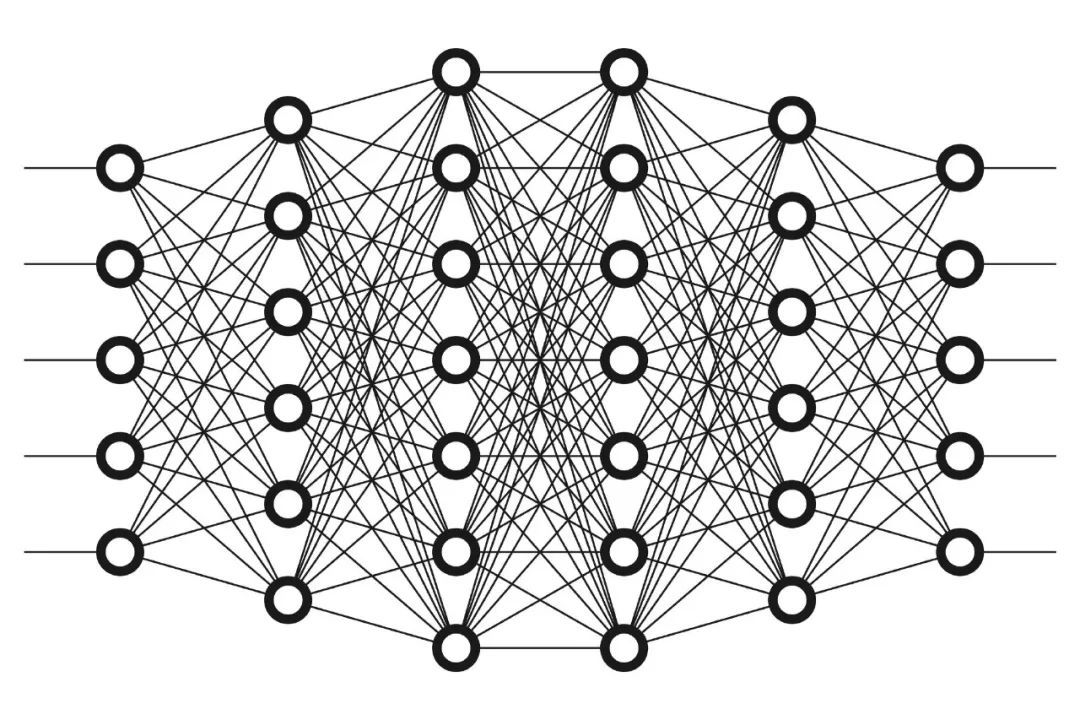
到这里,已经可以回答上面的问题了。深度学习的“学习”指的是什么?指的就是训练每个“神经元”的敏感程度。
可以想象,当一张很大的神经网络里面的每个神经元的敏感程度不一样,那么当看到不同的事物、接受不同的刺激的时候,被激活的神经元也会不同。
就好像我看到食物,就激活了我的食欲。看到数学,就激活了我的疲乏。
深度学习要做的就是编织这么大一张神经网络,然后去调整里面每一个神经元的敏感程度,最终我们希望使得这个网络可以像人类一样认识图像、听懂声音等等。
深度学习的深度指的是什么呢?就指的是这个神经网络非常“深”,有非常多层、非常多个神经元。
那么具体是怎么做的呢?我这里举一个简单的小例子:
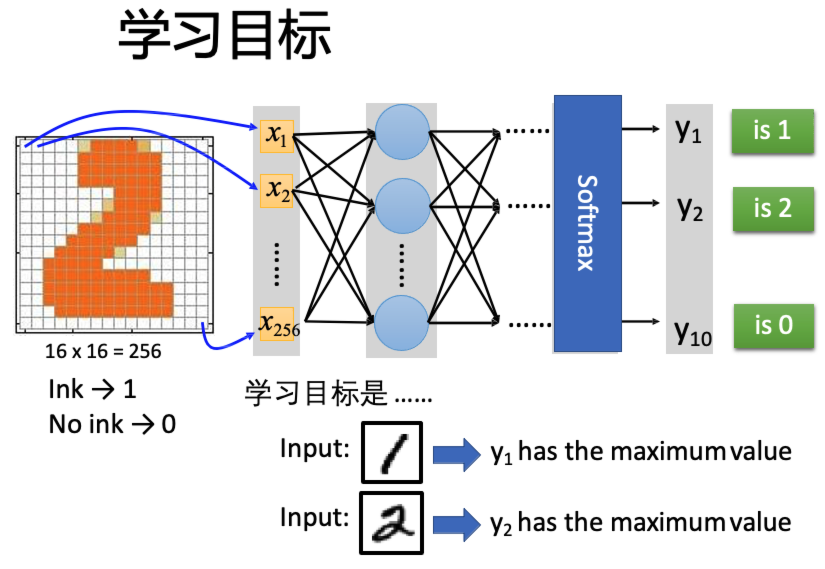
这里我有一个16×16像素的图片上面写着数字“2”,我用一个16×16的矩阵来表示这个图片,橙色的像素点表示为1,白色的像素点部分表示为0。把这个矩阵拉直成一个256维的向量。
有1的位置就表示有电信号,0的位置就表示没有电信号。
把这一串信号给一个深度神经网络,这串信号就会一层一层激活,最后传递到最后一层。最后一层我们给人为设置成十个神经元。
我们希望,当这个深度神经网络看到了数字2的时候,最后一层中的第二个神经元被激活。以此类推,当看到了数字1的时候,最后一层中第一个神经元被激活...(如上图)
那如果它错了呢?这就要“教训”它了。
我们要告诉它正确的结果,同时给它一个大嘴巴子。威胁它下次再错就再给它一个大嘴巴子,迫使它调节每一个神经元的敏感度,使得下一次产生正确的结果。这就是深度学习的学习过程。
具体的说,在数学上我们会建立一个损失函数,这个损失函数是参数的函数,在知道输入和输出的情况下,想办法寻找一个参数让这个损失函数的值最小。
如果懂一点数学的,可以类比多元回归中的最小二乘法。在最小二乘法中,如果满足一定的条件,我们是可以求出最优参数的显式解的。但是深度神经网络往往非常复杂,无法直接求出损失函数的最小值点。
所以深度学习的学习过程其实就是建立一个损失函数,这个损失函数就表示为模型给出的结果和我们想让他它得到的结果之间的距离。
然后通过调整每一个神经元的敏感度使损失函数的值最小。
在高考中,求函数极值问题就是数学试卷的最后一道题...
这里往往使用的一种方法叫做梯度下降法。
这个方法非常直观。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









