






为了生成region proposal,我们在feature map(由共享卷积层的最后一层上输出)上滑动一个small network。这个small network以一个feature map上nn的空间窗口作为输入。每个sliding-window被映射到一个更低维特征(256-d for ZF and 512-d for VGG, with ReLU following)。这些特征再给到两个FC层(一个box回归层,一个分类层)。本文的n=3,注意在原图的有效面积是很大的(171 and 228 pixels for ZF and VGG, respectively)。这个small network在单个位置的说明如下图。注意small network是以sliding-window的方式操作的,所有的空间位置共享全连接层。这种结构被nn的conv层和两个11 conv 层部署(一个reg,一个cls)。

anchor
在每一个 sliding-window的位置,我们同时预测多个region proposals(最大K个)。所以reg 层有4k个输出(用于编码k个box的坐标),cls层有2k个分数(用于预测每个proposal是不是object,用 two-class softmax layer实现)。k个proposals是相对k个reference boxes(称为anchor)进行参数化的。Anchor位于sliding-window的中心,anchor的长宽和纵横比是相关联的(如上左图)。默认使用三个长宽和三个纵横比,所以在每个sliding-window的位置获得9个anchors。对于一个WH的conv feature map,有WHk个anchors(
i)anchor是体现在sliding-window上;
ii)其坐标值和ground truth box的坐标值在同图,在原图 ;
iii)那是如何由sliding window的anchor映射回去的?
1)平移不变性
对于anchors和用于计算proposals相对anchor的函数,我们的方法都有平移不变性。如果一张图片的object被移动,proposals应该移动并且相同的函数应该能够预测在任何位置的proposals。
平移不变性还能减少模型的大小,参数比 MultiBox减少两个数量级(two orders of magnitude),可以减少过拟合。
2)多尺度的anchor作为回归的References
我们的方法是在以多尺度和纵横比anchors的参考下进行分类和box的回归的。这仅仅
依赖于原图和单尺度的特征图,并且使用单一尺度的filters(sliding windows on the feature
map)。
因为这种基于anchor的多尺度设计,我们可以简单的使用在单尺度原图上计算得到的conv features,就像通过Fast R-CNN 检测器做的呢样。
Loss function
对于训练RPN,我们给每一个anchor分配一个2值标签(是或不是object)。给两类anchor分配正标签:(i)anchor和一个ground truth box有最大的IOU,(ii)anchor和任何ground truth box有IOU>0.7。注意,一个的ground truth box可能对多个anchor分配正标签。通常第二种情况就可以满足决定正标签的样本;但是我们仍然采用第一种,因为有时候第二种办法会找不到正标签。当IOU<0.3时,分配一个负标签。具有其他IOU值的anchor不用做训练。
在这些定义下,我们最小化一个多任务目标函数。定义如下:
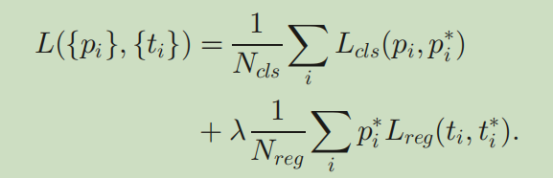
这里,i是在一个mini-batch中某一个anchor的索引,pi是anchor i是一个object的预测概率。Pi是ground-truth label ,如果anchor是正标签,pi=1;反之,pi*=0。ti是预测box的参数向量,ti是一个与正标签anchor相关的ground-truth box的向量。分类loss Lcls是个两分类的log loss,回归loss用Lreg(ti,ti)=R(ti-ti*) 其中R是smooth L1。piLreg的pi意思是,只有当是正标签的anchor时才会有Lreg。分类loss和回归loss分别各自包含pi和ti。
两部分分别被Ncls和Nreg归一化,然后被λ加权求和。在本文实施中,Ncls=256(mini-batch size) 并且 Nreg大约=2400(anchor位置的数量)。默认λ=10,这样两部分的权重大致相等。实验表明结果对很宽范围的λ不敏感。注意,归一化也不是必须的,可以简化。
对于box回归,采用以下四个坐标。其中x,y,w和h分别表示box的中心坐标和他的宽和高。变量x,xa,x分别是是预测box,anchor box和ground-truth box(y,w,h同理)。这可以被认为是从一个anchor box到一个附近ground-truth box的回归。
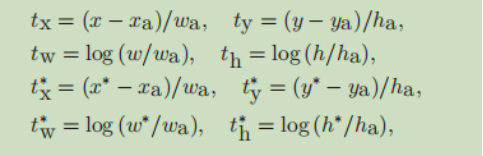
Lreg(ti,ti)=R(ti-ti*)=R((i-i*)/somewhat),注意分母和anchor的坐标有关系。
然而,我们使用了与ROI不同的方法得到box回归。ROI算法是在任意大小的ROI集合上执行的,并且回归权重有所有区域共享。我们的公式中,用于回归的特征来自feature map 上相同的大小(3*3)。为了有尺寸的变化,一组k个box 回归器被学习。每个回归器负责一个尺寸和纵横比,k个回归器不共享权重。所以尽管是固定尺寸的特征,它仍然可以预测不同尺寸的box。
Training RPNs
RPN可以通过BP和SGD训练。我们遵循以图像为中心的抽样策略训练网络。每个mini-batch源自单张图片(包括多个正负标签的anchor)。这样可以对所有的anchor的loss function进行优化,但是这会偏向负样本,因为其占主导地位。所以,我们随机在一张原图(image)上抽取256个anchor(正负标签1:1)去计算一个mini-batch的loss function。如果正样本不够128个,就用负样本补充。
随机初始化所有的新的layers(高斯,u=0,标准差=0.01),共享卷积层使用用ImageNet pre-training的model。PASCAL VOC dataset训练时,前60k的mini-batch使用lr=0.001,之后20k使用lr=0.0001。Momentum=0.9,weight decay=0.0005.















 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









