







文章召回-基于ALS的协同过滤算法
本项目完整源码地址:https://github.com/angeliababy/ALS_col
项目博客地址: https://blog.csdn.net/qq_29153321/article/details/104007318
原理
ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面。
用户和商品的关系,可以抽象为如下的三元组:<User,Item,Rating>。其中,Rating是用户对商品的评分,表征用户对该商品的喜好程度。
一个用户也不可能给所有商品评分,因此,R矩阵注定是个稀疏矩阵。
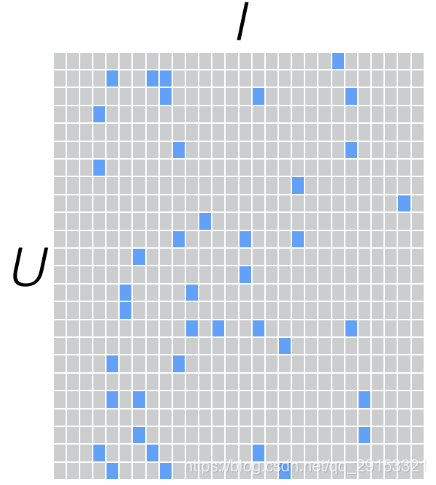
针对这样的特点,我们可以假设用户和商品之间存在若干关联维度(比如用户年龄、性别、受教育程度和商品的外观、价格等),我们只需要将R矩阵投射到这些维度上即可。
我们并不需要显式的定义这些关联维度,而只需要假定它们存在即可。一般情况下,k的值远小于n和m的值,从而达到了数据降维的目的。k的典型取值一般是20~200。
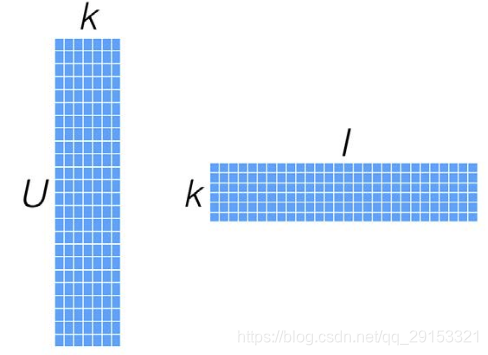
计算出来用户对未知物品的得分,同时,矩阵X和Y,还可以用于比较不同的User(或Item)之间的相似度。
优缺点:
首先,协同过滤不是全局推荐。详细如下:

实践部分
数据准备
用户资讯得分数据,也可用网上的电影数据集
用户资讯得分方案:
1. 如果不是有效阅读(阅读时长<2秒),得分为0
2. 阅读,直接2分*阅读占比
3. 点赞,直接3分
4. 评论,直接4分
5. 收藏或者分享,直接5分
6. 不喜欢,直接-1分
依据下面表格式构造训练数据,只需构建代码中用到的字段即可
CREATE TABLE `news_read` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` int(11) NOT NULL DEFAULT '0',
`member_id` int(11) NOT NULL DEFAULT '0',
`channel_id` int(11) DEFAULT NULL COMMENT '频道编号',
`news_id` int(11) DEFAULT NULL COMMENT '文章编号',
`entry_datetime` datetime DEFAULT NULL COMMENT '进入时间',
`leave_datetime` datetime DEFAULT NULL COMMENT '离开时间',
`readed_percent` int(11) DEFAULT NULL COMMENT '阅读进度',
`is_try_share` bit(1) DEFAULT b'0' COMMENT '是否尝试分享',
`review_count` int(11) DEFAULT '0' COMMENT '评论数量',
`is_review` bit(1) DEFAULT b'0' COMMENT '是否评论',
`is_collect` bit(1) DEFAULT NULL COMMENT '是否收藏',
`is_praise` bit(1) DEFAULT NULL COMMENT '是否点赞',
`is_tread` bit(1) DEFAULT b'0' COMMENT '是否踩',
`lang` int(11) DEFAULT '-1' COMMENT '1:中文、2:柬文、3:英文',
`platform` int(11) DEFAULT '-1' COMMENT '1:安卓,2:苹果',
`batch_no` varchar(64) NOT NULL DEFAULT '' COMMENT '批次号',
`source` tinyint(4) NOT NULL DEFAULT '99' COMMENT '资讯阅读入口(1、历史 2、收藏 3、频道(遗弃) 4、相关推荐 5、搜索 6、用户动态 7、资讯模块 8、视频模块 9、小视频模块 99、其它)',
`news_type` tinyint(4) NOT NULL DEFAULT '-1' COMMENT '资讯类型(1、图文,2、图集,3、视频,4、小说、6、广告推广 8、小视频)',
`add_datetime` datetime DEFAULT NULL COMMENT '添加时间',
`app_version` varchar(128) DEFAULT '' COMMENT 'APP版本',
`ip` varchar(255) DEFAULT '' COMMENT '客户端IP',
`device_id` varchar(255) DEFAULT '' COMMENT '设备ID',
`country` varchar(255) DEFAULT NULL,
`province` varchar(255) DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
`uuid` varchar(128) DEFAULT '' COMMENT '客户端全局唯一id',
`log_id` varchar(64) NOT NULL DEFAULT '' COMMENT '日志Id',
`relation_news_ids` varchar(255) NOT NULL DEFAULT '' COMMENT '延展阅读曝光的资讯',
PRIMARY KEY (`id`),
KEY `news_id` (`news_id`,`channel_id`,`member_id`) USING BTREE,
KEY `channel_id` (`channel_id`,`news_id`,`member_id`),
KEY `add_datetime` (`add_datetime`),
KEY `channelId_memberId_time` (`channel_id`,`member_id`,`add_datetime`),
KEY `member_id` (`member_id`,`add_datetime`,`channel_id`) USING BTREE,
KEY `user_id` (`user_id`,`add_datetime`,`channel_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=53485290 DEFAULT CHARSET=utf8mb4 COMMENT='资讯阅读行为表'
news_read = news_read.select(news_read.user_id,news_read.member_id,news_read.news_id,news_read.readed_percent,news_read.is_try_share,news_read.is_collect,news_read.is_review,news_read.is_praise,news_read.entry_datetime,news_read.leave_datetime,news_read.news_type,news_read.add_datetime,news_read.id)
修改程序中读取数据部分
运行程序,修改路径
spark-submit --master local --jars /home/spider/code/reconmmend_test/Trunk/news_recommed_reckon_java/action_reckon/searchword/lib/mysql-connector-java-5.1.38.jar --conf spark.pyspark.python=/usr/local/bin/python3 --conf spark.pyspark.driver.python=/usr/local/bin/python3 offline/user_news_score_t.py
ALS评估
上步中生成的news_score样例数据如下:
user_id,member_id,item,score,log_time
51778098,898036,8644098,1.04,2020-01-06 10:39:21
1.训练数据
from pyspark.mllib.recommendation import Rating, ALS
# 1.训练数据(用户序号,item,rating)
ratings = user_data_join.map(lambda x: Rating(int(x[0]), int(x[1]), float(x[2])))
2.训练
model = ALS.train(ratings,50,10,0.01)
3.给单个用户推荐物品
user = 3
topKRecs = model.recommendProducts(user, 10)
for i in topKRecs:
print(i)
4.测试数据
7天当作训练数据,1天当作测试
# 处理数据,用户序号,资讯,得分
user_data_join, user_label = get_data(datas, user_label)
5.预测数据
userProducts = ratings.map(lambda rating:(rating.user,rating.product))
print('实际的评分电影:',userProducts.take(5))
# print (model.predictAll(userProducts).collect()[0])
predictions = model.predictAll(userProducts)
6.评估
predictions = model.predictAll(userProducts).map(lambda rating:((rating.user,rating.product), rating.rating))
print('预测的评分:',predictions.take(5))
ratingsAndPredictions = ratings.map(lambda rating:((rating.user,rating.product),rating.rating)).join(predictions)
print('组合预测的评分和实际的评分:',ratingsAndPredictions.take(5))
# 组合预测的评分和实际的评分: [((1730, 8904080), (1.52, 1.5183552691178965)), ((2634, 8903648), (1.08, 1.109481704984579)), ((412, 8824284), (1.94, 1.9368518512651538)), ((759, 8841175), (2.0, 1.9916580018716354)),((846, 8825136), (5.0, 4.987908502485232))]
from pyspark.mllib.evaluation import RegressionMetrics
from pyspark.mllib.evaluation import RankingMetrics
#((196, 242), (3.0, 3.089619902353484))
predictedAndTrue = ratingsAndPredictions.map(lambda x:x[1][0:2])
print (predictedAndTrue.take(5))
regressionMetrics = RegressionMetrics(predictedAndTrue)
print ("均方误差 = %f"%regressionMetrics.meanSquaredError)
print ("均方根误差 = %f"% regressionMetrics.rootMeanSquaredError)
7.评估结果
1)训练数据拟合的准确性(7天当作训练数据,预测数据也来自训练集):
均方误差 = 0.000245
均方根误差 = 0.015641
2)测试数据的准确性(7天当作训练数据,另1天当作测试):
均方误差 = 1.663446
均方根误差 = 1.289746
参考博客:
https://blog.csdn.net/buptdavid/article/details/78970906
https://www.zybuluo.com/xtccc/note/200979















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









