







有不对的地方,欢迎指正
冒泡排序
核心思想
假如n个数按照由小到大的顺序排列,从后往前升序相邻两两比较大小,(我觉得比较好理解),如果前一位比后一位大就立刻把它俩换位,直接交换位置,第一遍下来,最大的在最后一位,之后不用在比较最后一位了,第二遍,次大的在第二位。。。。。。第一遍比较了n-1次,交换了不确定次,第二遍比较了n-2次。。。。。
void bubble_sort(int a[],int n)
{
int tem=0;
for(int i=n-1;i>0;--i)
{
for(int j=0;j<i;++j)
{
if(a[j]>a[j+1])
{
tem=a[j];
a[j]=a[j+1];
a[j+1]=tem;
}
}
}
}
选择排序
核心思想
具体方法为:
遍历一次,记录下最值元素所在位置,遍历结束后,将此最值元素调整到合适的位置
第一次遍历,比较n-1次,只需一次交换,便可将最值放置到合适位置
void sort(int a[],int n){
for(int i=0;i<n;i++)//外层循环
{
int min=a[i];//每次循环把a[i]假设当前最小的数
int index=i;//相当一个索引,始终指向最小的
for(int j=i+1;j<n;j++)//内层循环,从剩下的数中找有没有更小的
{
if(a[j]<min)
{
min=a[j];
index=j;//跟新索引
}
}
int temp=a[index];//交换
a[index]=a[i];
a[i]=temp;
}
}
改进
void select_sort(int a[],int n)
{
int k,temp;
for(int i=0;i<n-1;i++)
{
k=i;//假设最小为a[i],用k标记
for(int j=i+1;j<n;j++)//内层循环,从剩下的数中找有没有更小的
{
if(a[j]<a[k])
{
k=j;//找到新的最小的,跟新k的值
}
}
if(i!=k)//比较i和k的值,判断是否交换
{
temp=a[i];
a[i]=a[k];
a[k]=temp;
}
}
}
两者的区别
同样数据的情况下,2种算法的循环次数是一样的,比较次数也一样,但选择排序只有0到1次交换,而冒泡排序只有0到n次交换。
影响我们算法性能的主要部分是循环和交换,显然,次数越多,性能就越差。复杂度都为O(n*n)。但效率不同
冒泡排序:
当数据处于倒序的情况时,交换次数同循环一样(每次循环判断都会交换),
复杂度为O(n*n)。当数据为正序,将不会有交换。复杂度为O(0)。乱序时处于中间状态。正是由于这样的原因,我们通常都是通过循环次数来对比算法。
选择排序:
由于每次外层循环只产生一次交换(只有一个最小值)。所以f(n)<=n
所以我们有f(n)=O(n)。所以,在数据较乱的时候,可以减少一定的交换次数。
快速排序
核心思想:
插入排序
核心思想:
插入排序就是每一步都将一个待排数据按其大小插入到已经排序的数据中的适当位置,直到全部插入完毕。
1,从第一个元素开始,该元素a[0]可以认为已经是被排序。
2,取出下一元素,在已经排序的元素序列中从后往前扫描
3,如果该元素a[0](已排序),大于新元素a[1],则将该元素a[0]移到下一位置
4,重复3,直到找到已排序的元素小于或等于新元素的位置
5,将新元素插入到该位置
6,重复2
插入排序方法分直接插入排序和折半插入排序两种,这里只介绍直接插入排序,折半插入排序请看另一篇文章http://blog.csdn.net/qq_29232943/article/details/52939374
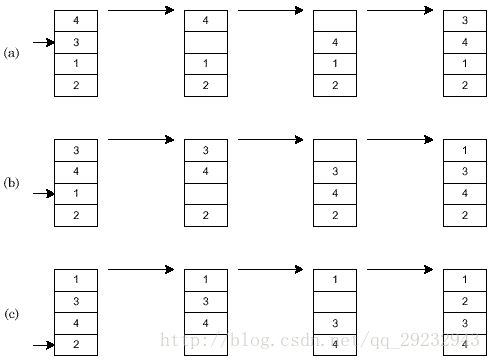
图1演示了对4个元素进行直接插入排序的过程,共需要(a),(b),(c)三次插入。
#include <iostream>
using namespace std;
void insert_sort(int a[],int n);
int main()
{
int a[]={3,41,369,1,2,4,5,9};
int n=8;
insert_sort(a,n);
for(int i=0;i<n;i++)
{
cout<<a[i]<<" ";
}
return 0;
}
void insert_sort(int a[],int n)
{
for (int i=1;i<n;i++)
{
for(int j=i;(j>0)&&(a[j]<a[j-1]);j--)
{
int tem=a[j];
a[j]=a[j-1];
a[j-1]=tem;
}
}
}
最好情况,已经是升序了,只需要n-1次比较,最坏情况,是降序的,要n(n-1)/次比较
平均复杂度为O(n2)















 3819
3819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









