







 iMeta是一个基于Java的模型驱动开发框架,与微服务架构紧密结合,使用元数据配置为主,适用于云环境下的Web、数据库、NoSQL和异步服务。它支持零代码开发,提供统一查询、持久化、DTS和代码生成等功能,简化了开发者的工作并支持Spring和WebFlux集成。
iMeta是一个基于Java的模型驱动开发框架,与微服务架构紧密结合,使用元数据配置为主,适用于云环境下的Web、数据库、NoSQL和异步服务。它支持零代码开发,提供统一查询、持久化、DTS和代码生成等功能,简化了开发者的工作并支持Spring和WebFlux集成。
📢📢📢📣📣📣
哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝
一位上进心十足的【Java ToB端大厂领域博主】!😜😜😜
喜欢java和python,平时比较懒,能用程序解决的坚决不手动解决😜😜😜✨ 如果有对【java】感兴趣的【小可爱】,欢迎关注我
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
————————————————如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。
iMeta是一个基于JAVA语言开发的模型驱动(MDD)开发框架,以元数据为基础,与微服务架构(Micro-Services)天然融合,配置文件为主要开发方式,适用于以关系数据库和No-Sql数据库为数据存储介质、以数据查询、持久化为主要操作方式、面向微服务的、部署在云(Cloud)中的应用程序。
- MDD:以用户模型(参考“OMG四层元模型架构”中M1层)为基础的开发框架,使用元数据描述用户模型,元数据结构借鉴OMG M2层静态元素结构,开发时以元数据为基础、以配置文件为主要开发方式。
- Zero Coding:零JAVA代码,主要开发方式是书写配置文件,包括:用户模型、数据查询、导出导出等。
- Micro-Services Inside:天然支持微服务,涉及远程服务、缓存服务、本地服务的查询统一查询配置,对开发人员透明,极大降低开发复杂度和成本。
- Deep integration with Spring:iMeta与Spring深度集成,参考Spring Boot的实现方式,实现了自动配置,开发时引入jar包即可。
- Extensible:iMeta框架采用分层架构,完全基于接口,底层使用接口定义系统脉络、体现系统整体结构;同时也提供了大量的默认实现,主要位于Spring集成层中,这些默认实现可以被替换、扩展。
iMeta框架已经为Web、数据库、No-Sql、异步服务等提供了默认实现,为了更加高效开发,最好具备以下知识。
- [必选]具有一定软件工程基础:对UML有一定了解,能够绘制UML类图,理解类间关系(继承、实现、关联、组合)的含义,最好能够将业务中共性应用场景、模型抽象出基类或接口,这些是iMeta开发的原材料。
- [可选]具有一定WEB开发基础:了解cookie、cors、http、ajax等常见概念。
- [可选]具有一定No-SQL基础:当应用程序使用No-Sql数据库(例如:Redis)存储数据时,需要了解相关No-Sql一些常见操作。
- [可选]具有一定异步编程知识:当应用程序为高性能异步应用时,需要了解Reactor、WebFlux、No-Sql异步驱动一些基本知识。
- [可选]具有一定架构能力:能够合理拆分服务,实现高内聚低耦合的微服务架构。
OMG四层元模型架构

- M0层 (实例对象层)
- 是现实世界的具体事物/数据,代表一个个具体的实例对象。
- M1层(用户模型层)
- 是对现实事物的抽象,包含类及其关系,图中M1层对一个影片管理系统建模,抽象出类Movie类,包含title属性,用于描述现实世界中的影片;
- 目的是使用软件系统描述现实世界。
- M2层(UML层)
- 对M1层建模使用的元素包括模型元素、图等进行抽象。
- 使用Class抽象描述Movie,使用Attribute(Property)抽象描述title,使用Instance抽象描述具体一个影片实例;
- M3层 (MOF层)
- 是对M2层进一步抽象,该层为递归层,即可以继续高度抽象。
- iMetaFramework参考MOF结构,抽象出元数据的结构;M1层(用户模型层)的元素就是领域元数据的原材料。
iMeta与其它架构的关系
iMeta vs ORM
| iMeta Framework | ORM | |
|---|---|---|
| 设计 | 以服务为基础 | 以实体为基础 |
| 抽象层次 | M2元数据,对M1的抽象 | M1,对业务数据的抽象 |
| 设计 | 以服务为基础 | 以实体为基础 |
| 开发视角 | 基于抽象:用户模型、类图 | 基于具体实现:实体、数据库表 |
| 功能 | 关系数据库、No-SQL数据库、远程服务操作透明化 | 数据库操作透明化 |
| 数据源 | 关系数据库、No-SQL数据库、远程服务 | 关系数据库 |
面向关系数据库(例如:Mysql)开发时,ORM框架(例如:Mybatis、Hibernate)提供了基础的数据库操作能力,还提供了一定的缓存能力。随着云(Cloud)的日益普及、微服务架构日益流行,存粹的ORM框架已经很难解决关系数据库和No-Sql数据库综合使用的应用场景。 iMeta提供面向服务的ORM能力,自动适配集成来自不同数据源的数据,iMeta的关系数据库的操作部分仍然可以使用传统ORM能力。
iMeta & Micro-Services
微服务架构在容器环境中,可以轻松弹性扩容,已经成为云(Cloud)部署环境的首选框架。 iMeta框架天然支持微服务架构,统一查询服务自动识别分拆查询服务,聚合查询来自No-Sql数据库、关系数据库、远程服务不同数据源的数据,整个过程对开发人员是透明的,极大降低开发复杂度和成本。
iMeta & Spring
Spring框架已经成为JAVA开发标配,Spring Boot的出现更是极大降低了JAVA Web开发的复杂度。 iMeta参考Spring Boot的实现方式,实现了自动配置,开发时引入jar包即可。
iMeta & Spring WebFlux
利用微服务框架可以很容易实现应用程序水平扩展,但通过WebFlux反应式框架实现纵向并发能力提升越来越流行,通过较少的资源提供更大的并发能力是一种趋势,尤其是在面向No-Sql数据库的应用中。 iMeta提供了集成WebFlux的能力,可以方便的开发涉及任务调度、网关、No-Sql数据库的应用程序。

- 总体思想
模型驱动,面向服务,快速集成。 - 系统架构
分层体系,接口层用于定义系统脉络、体现系统整体结构;
实现层借助Spring boot自动加载、灵活扩展,用于实现网络、数据库、缓存、邮件、调度任务等功能。 - 面向微服务
以服务为单元进行数据处理,将本地数据库、缓存服务、远程服务无缝集成,对开发人员透明,开发人员的视角均为用户模型。 - MDA/D
模型驱动架构、模型驱动开发,一切以用户模型为中心,以设计的视角开发高质量应用,有利于培养高素质团队,有效保留核心资产。 - 面向接口
尽可能早的在接口层中定义系统结构、体现系统设计思想;尽可能晚的与具体技术结合,降低耦合。 - 配置大于开发,约定大于配置
一切以零代码为目标,提供BOOT-STARTER一站式零JAVA代码服务组件。 - 多种扩展机制
- 框架层提供*MetaBean、*MetaAware等接口,自动注入具体实现类。
- 核心接口均有默认实现类,通过设置优先级,特定实现类可以替换默认实现类。
- 提供拦截器机制,可以在核心方法前后进行处理。
- 提供事件机制,重要环节会触发事件,通知Listener处理。
- 提供消息机制,在主流程完成时发布消息,提供事务外异步处理机制。
- 根据环境变量、配置参数可以include外部类,exclude默认类。

元数据加载主要分为两个阶段:元数据定义阶段、元数据阶段,通过实现不同接口,可以进行功能扩展。 元数据定义是元数据的原材料,经过加工可以转换成元数据。
应用场景
主要用于微服务化的数据查询、持久化和数据转换处理,例如:CRUD、导入导出,还提供任务调度、邮件、HTTP、代码生成等能力。
- 适用于服务器端开发
- 基于关系型数据库的应用
- 基于No-Sql的应用
- 基于基于关系型数据库、No-Sql、远程服务的混合型微服务架构应用
- 集成微服务框架
- Rest:Spring Cloud
- RPC:Dubbo
核心组件
- 元数据Metadata:Component、Interface、Entity、Property、DataType、Enumeration
- 接口:*MetaBean、*MetaAware,用于默认实现和扩展开发
- 事件通知:*Listener、*Event,用于扩展开发
- 仓库:*Registry
- 帮助类:*Walker、KeyIterator、Objectlizer
- CRUD:*SqlBuilder、*Service、QuerySchema
- 入口:MetaBeanFactory、TplBeanFactory
- 代码生成:*Builder、*Func
- 自动配置:*AutoConfig
- 解析器:*Parser、*Node、*Tree
核心概念
用户模型 UserModel
电子商城用户模型示例
包

类图

统计分析

用户模型中的静态类图可以认为是iMeta所需的原材料,基于此原材料生成元数据。
用户模型通常包含以下几个UML元素:包、类、属性、关系。关系主要描述类间关系,有继承、实现、关联、组合。
iMeta结合数据仓库模型,能够提供极为灵活的统计查询,一般情况下,无需一行JAVA代码。

-
- 订单Order与订单明细OrderDetail为组合关系,订单Order与买家Customer、订单明细OrderDetail与商品Goods间为关联关系。
- has-a (Association), contains-a (Composition)
- 组合是一种关系更加紧密的关联关系,重点是关系强弱和对象生命周期;
- 对于0..1的组合与关联无法准确区别时,考虑删除引用对象时,被引用对象是否同时消失,如果是,就是组合关系,否则是关联关系。
- 泛化/继承 vs 实现
-

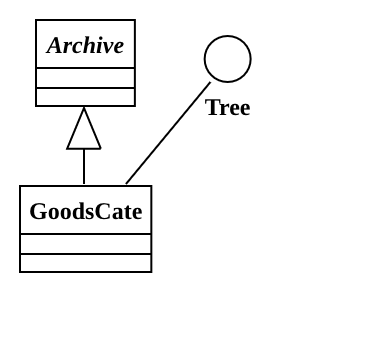
- 商品分类GoodsCate与档案Archive间为继承关系,商品分类GoodsCate与树型接口Tree间为实现关系。
- is-a (Generalization), comply-with (Realization)
- 继承和实现基于M2层编程时,除了校验规则并没有明显区别;在基于M1层(即用户模型层)编程时,继承和实现区别很大。
- 两者语义不同,继承基类用于划分类型体系,实现接口用于规定行为准则/协议;
- 在扩展性方面,实现一般优于继承,不同的实现类可以灵活替换,但继承有类型体系的含义,无法随意扩展子类。
- 开闭原则中对修改关闭、对扩展开放,核心就是面向接口编程,使用精简的接口抽象公共行为/准则/协议。
-
元数据定义 MetadataDefinition
-

域 Domain
域是对应用所属领域的抽象,域用于隔离不同的应用,域的隔离策略有:不隔离、单实例不同库、服务隔离,域的隔离级别(IsolationLevel)目前有三种:远程服务、缓存服务、本地服务,通过隔离策略决定域的隔离级别。
iMeta中域在组件(Component)上声明,组件为最小的部署单元。
域隔离级别
| 隔离策略 | 相同域 | 不同域 |
|---|---|---|
| 不隔离 | 本地服务/缓存服务 | 本地服务/缓存服务 |
| 单实例 | 本地服务(跨库)/缓存服务 | 本地服务(跨库)/缓存服务 |
| 服务隔离 | 本地服务/缓存服务 | 远程服务 |
隔离级别通过*Profile来确定,可以自定义MetaProfile。远程服务隔离级别设置在Property上,缓存服务隔离级别设置在Classifer上,本地服务隔离级别不用设置,但可能修改数据库表名。
对于远程服务和缓存服务隔离级别,需要在Classifier的service中设置访问方式,以供相应驱动使用。在Classifer的service属性中,可以指定明确的访问方式。
#服务协议格式 协议:驱动://服务器信息/数据源?参数列表 # 远程服务协议 service="remote:dubbo://<username>:<password>@<server>:<port>/<registry>?group=mall&interface=xxx.xxx&check=false&…" service="remote:dubbo://?group=mall&interface=xxx.xxx&check=false&…" service="remote:eureka://?application=xxx&…" # 缓存服务协议 service="cache:redis://<username>:<password>@<server>:<port>/<database>?key=cbo.goods.Goods&subkey=id&type=hash&…" service="cache:redis://1?key=cbo.goods.Goods&subkey=id&type=hash&…" service="cache:es://<url>?p1=v1&…" service="cache:mongo://<url>?p1=v1&…"
服务协议很多项不用设置,使用上下文中环境变量即可。如果什么都不设置,使用默认处理程序。缓存服务最好明确配置协议和驱动及关键参数。
用户模型与元数据的映射
| 用户模型 | 元数据模型 | 示例 |
|---|---|---|
| 包 | Component | order,goods |
| 包间依赖 | Component.dependencies | |
| 基本类型 | DataType | Integer,DateTime,String |
| 枚举类型 | Enumeration | OrderStatus |
| 实体 | Entity | Order,OderDetail,Goods |
| 接口 | Interface | Code,Autditable |
| 组合关系 | Aggregation(V2)/Association(V1) type="composition" | Order -> OrderDetail |
| 关联关系 | 通过类型推断 | OrderDetail -> Goods |
| 继承关系 | Generalization | Goods -> Archive |
| 实现关系 | Realization | OrderBase -> Auditable |
| 属性 | Property | code,details,createTime |
| 方法 | Operation | |
| 方法参数 | Parameter |
说明
- 关联关系推断:属性的数据类型为复杂类型时,属性所属类型与属性数据类型间为关联关系。
- 组合关系是一种关系强烈的关联关系。
- V2中使用Aggregation不使用Composition的原因是:1. Composition的缩写容易与Component混淆; 2. Aggregation取自聚合根的含义,而非UML中的聚合关系。
查询方案


查询方案为统一查询引擎对外开发的唯一数据结构,所有的查询配置都要遵守查询方案的定义。
应用模式
所有操作视角都统一到模型层,大多数应用模式仅依赖配置文件即可完成所有开发任务。
统一查询引擎
iMeta提供了统一查询引擎,将远程服务、缓存服务、本地服务的数据查询统一,实现细节对开发人员透明,所有操作视角都统一到模型层面,实现基于微服务的模型驱动开发;一般情况下,无需一行JAVA代码。
详细内容 查询引擎参考手册
统一持久化
iMeta提供了统一持久化机制,包括单实体持久化、组合实体持久化、批量新增,并提供了主外键设置、唯一性校验、数据合法性校验、默认值设置等默认规则;一般情况下,无需一行JAVA代码。
详细内容 持久化参考手册
统一DTS
iMeta提供了统一的数据转换服务,主要包括数据导出导出到Excel、csv文件;一般情况下,无需一行JAVA代码。
详细内容 DTS参考手册
代码生成和数据渲染
iMeta提供了一套模版解析引擎,提供支持设计态根据元数据生成代码和支持运行时渲染数据两种功能。
iMeta提供了一套模版解析引擎,提供支持设计态根据元数据生成代码和支持运行时渲染数据两种功能。
详细内容 模版参考手册
零JAVA代码
iMeta提供了一个简洁快速的imeta-boot-starter-service模块,仅仅通过配置文件,即可完成应用程序开发,一般情况下,无需一行JAVA代码。
详细内容 零JAVA代码参考手册
集成WebFlux
iMeta可以快速集成Spring WebFlux反应式编程框架,一般用于任务调度、路由分发、No-Sql数据库数据存储。

如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。欢迎大家订阅我后续会抽空将之前挖的坑满满填上,最近工作实在是有点多忙不过来各位粉丝见谅


















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











