







 本文介绍了作者在数据挖掘课程中初次接触爬虫,特别是使用Scrapy框架爬取微信相关网站的经历。文章讨论了爬虫的基本概念、Scrapy框架的工作原理,以及遇到的robots.txt限制和反爬机制。作者分享了如何针对反爬策略进行调整,包括设置Scrapy不遵守robots.txt,以及对网站的反爬策略如IP封锁、User-Agent识别等进行了探讨。最后,作者提到了实战中爬取weixin.sogou.com的步骤,并总结了学习爬虫和Python的重要性。
本文介绍了作者在数据挖掘课程中初次接触爬虫,特别是使用Scrapy框架爬取微信相关网站的经历。文章讨论了爬虫的基本概念、Scrapy框架的工作原理,以及遇到的robots.txt限制和反爬机制。作者分享了如何针对反爬策略进行调整,包括设置Scrapy不遵守robots.txt,以及对网站的反爬策略如IP封锁、User-Agent识别等进行了探讨。最后,作者提到了实战中爬取weixin.sogou.com的步骤,并总结了学习爬虫和Python的重要性。
缘由
在之前完全没有接触过爬虫的我,甚至都不知道爬虫是何物,然而在数据挖掘课程第二次大作业中却要我们小组直接用scrapy框架做一个爬取朋友圈的爬虫,一接到作业的我们马上就懵逼了,别说是scrapy了,我们就连什么是爬虫,爬虫原理是什么都一无所知,突然就要爬微信朋友圈,还要两周内,开什么玩笑。
但是怎么也得做,就分工着做,折腾了一段时间,总算有点收获和更加清晰的认识,现在有点小进度,就来报告一下进度~(其实是来总结的.)
话说爬虫
先说说爬虫,爬虫常被用来抓取特定网站网页的HTML数据,定位在后端数据的获取,而对于网站而言,爬虫给网站带来流量的同时,一些设计不好的爬虫由于爬得太猛,导致给网站来带很大的负担,当然再加上一些网站并不希望被爬取,所以就出现了许许多多的反爬技术。
Scrapy
Scrapy是用python写的一个爬虫框架,当然如果只是写一些简单爬虫,python自己就有做爬虫的库,scrapy只是更加流水线化,各部分分工更加清晰.它的结构如下图:
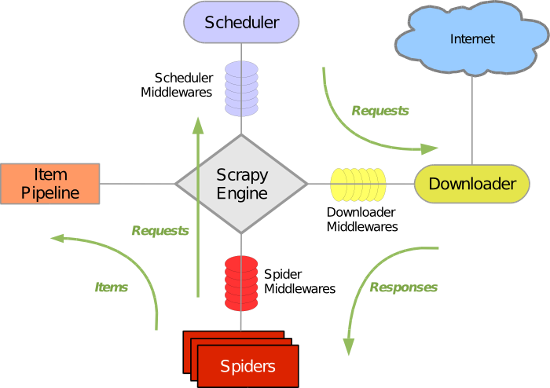
首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。
当然,光是学会最基础的scrapy的使用是很快的,因为demo很多,但是对于实际爬取却并不是这么简单,就拿weixin.sogou.com(或者chuansong.me)来说,一开始我以为,只要在spider里面start_urls里面把爬取URL入口改成 http://weixin.sogou.com,再定义一下parse规则选择要抓取的内
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









