







前言
离上一篇更新的博文应该过了挺久的了( python爬虫(上)–请求——关于旅游网站的酒店评论爬取(传参方法)),因为中间考完试紧接着就去实习的缘故,然后到新环境各种熟悉什么的,所以后面有所学到的东西就来不及汇总,终于在某个礼拜天的下午,喝着我的雀巢速溶咖啡,一边写着这篇总结。
上一篇我自己也回去又看了一遍,其实上一篇的博文主要还是用的是 传参 的方法,什么叫传参的方法?就是着重点在分析交互中各种数据请求来源,然后找到我们需要的数据来源,再写个脚本把数据请求回来,最后做个提取就OK了,这种办法的优点在于执行得很快,对比于后面我要说的一种 模拟浏览器 的方法来说,在请求页面的效率上会快上很多,而传参方法的难点在于寻找数据来源的那个URL还有它尾巴的一堆参数的构建,当然简单的比如上一篇的艺龙的酒店评论的话,直接用chrome的开发者工具XHR项目里面就可以找到,但当遇到更为复杂的页面结构,或者采用更加复杂技术的页面(比如混淆代码啊,压缩代码之类的),传参这种办法的工作就变得十分繁琐,特别是在XHR里面没有找到数据来源的URL的时候,要在一堆js脚本里面找到你要的数据的请求来源的时候,你会彻底懵逼了,反正我是懵逼了好几次,而且爬虫有个真理——越是接近人的操作的爬虫越是好的爬虫。因为网站是为了人去访问而服务的,那么就算网站反爬很厉害,但是也不可能去因为爬虫而误伤了正常的用户,对于一个网站而言得不偿失,所以当我懵逼了几次以后,果断转用模拟浏览器的方法,我在这里要明确一点,传参的思路和模拟浏览器的思路是不一样的,所以要分开来认识他们
爬虫制作总览
经过实习这一段时间以来的学习和研究,包括对python这门语言更加深入的了解,还有对爬虫中遇到的问题的总结,我觉得大致上爬虫的制作思路如下:
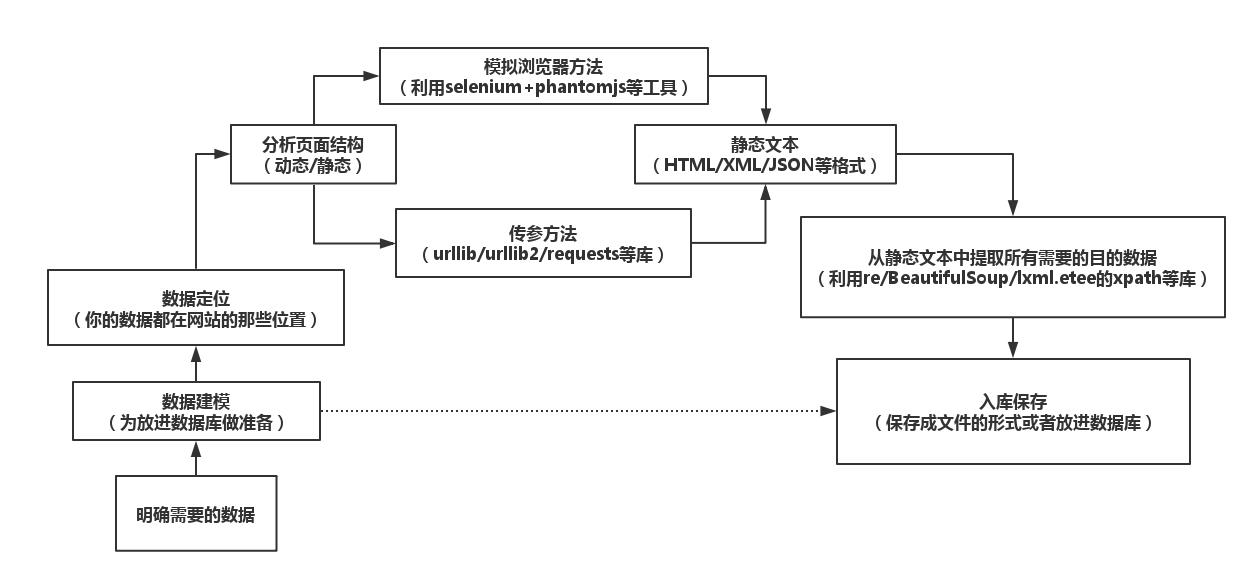
P.s.更正上图lxml.etee为lxml.etree
上图中需要补充的是,有时候有登录的需求,登录里面会涉及验证码的问题,其实说白了就是OCR技术的应用,还有访问过频,封IP或者是弹验证码的问题,这些都是爬虫会遇到的独特问题,不过一般按照上图的思路去做爬虫,遇到上面这些问题再相对应的做应对策略就好.
其实爬虫好玩的地方在于与网站程序猿的之间的博弈,一般而言,没有哪个网站是希望自己的数据被爬虫爬去的,当然谷歌百度这种大的搜索引擎除外,每天都被成百上千的练手也好,娱乐也罢的大大小小的爬虫们爬网站内容,哪个服务器受得了,所以对于山那头的程序猿而言,爬虫生死之战在于把关好请求页面这一步,不让爬虫程序拿到完整静态页面;对于开发爬虫的程序猿而言,爬虫生死之战就在能否成功到达拿到完整静态文本那一步——请求页面(完整是针对动态页面而言需要完整加载出目的数据的文本),因为拿到静态文本以后,我要怎么做网站那头的程序猿就算使用洪荒之力也已经限制不了我了,这时候慢慢做提取都可以,请求页面就是前言里面说的两种办法:传参or模拟浏览器.
【P.s.传参和模拟浏览器最大的不同是获取数据的地方不一样。传参让人感觉更加底层,就是有点贴近http协议的那种底层,总给人一种要做非常细致推敲工作的过程的感觉,传参取得数据的地方就是你所请求的URL返回的文本,而难就难在这个URL怎么构造才能骗过山那头的各种脚本顺利请求回包含目的数据的源码; 而模拟浏览器的办法,就有点取巧,但是却是面对现在越来越复杂的网站架构技术的最佳办法,也是最贴合人操作浏览器这种想法的方法(最不容易被封),模拟浏览器操作的办法取得数据的地方是浏览器的内核,因为模拟浏览器方法的核心思想是:无论你中间技术怎么复杂,怎么变化,你最终还是要在浏览器内核中渲染好加载好数据来呈现给用户,而渲染好加载好后的必定是一个静态文本,那么我直接拿这个静态文本再提取数据就好了。模拟浏览器操作的方法虽然比传参的方法慢,但是胜在它稳,而且爬取思路非常清晰简单:D】
模拟浏览器动作
模拟浏览器的方法其实就是把一个人每天到目的网站上复制黏贴目的数据的过程用程序和机器实现,这过程为:用浏览器打开网站→输入信息和提交等动作→浏览器请求相关网页→浏览器渲染返回信息→人把渲染出来的信息复制黏贴保存系下来.
这样日复一日,每天都重复一样的机械性 的动作,这毫无疑问是很低效的,但是却是最保险稳定的,因为被封IP的几率很小,甚至可以忽略不计,但是估计这个人得累死,那么我们这些懒鬼当然希望能够让机器帮助我们实现日复一日的这样机械的过程,那么就得模拟这一个过程,这里我们要用到selenium来模拟人来操作浏览器。
(1)模拟登陆–Selenium
首先是模拟用户登录,以登录后的状态去请求接下来的页面,因为项目内容保密的缘故,一些信息不方便透露,不过单纯用到的技术还有思想还是可以分享一下的
Q:为什么最好用登录后状态去请求数据?
A:(收集自网上的回答)
1.一方面可能是因为你要的数据在登录后才有,比如微博;
2.另外一方面也可能是因为你需要会员登录获得优惠的价格信息;
3.而从单纯的技术的角度的来说,用登录状态来爬是有好处的:
①携程网站对于爬虫的频率是有限制的,爬取频率过高,服务器会返回429错误,此时如果没有登录用户无法正确获取数据;
②建议:登录账号后利用Cookie进行数据的爬取,虽然登录后过于频繁请求也会导致429错误(python的话20线程10min就会出现),但只要等3min就可以继续快乐地爬取了,而且爬取的数据不会出错,而不登录会数据出错
③而值得注意的是,用账号登录之后生成的Cookie不到几个小时就会失效
模拟用户登录在很久以前还没有验证码的时候还是很简单的,特别是配合selenium的情况下是非常容易做到的,但是自从山那头的程序猿们发明和发展了验证码后,模拟用户登录就没有那么容易了
补充:关于selenium安装,pip install也可以,apt-get install 也可以,通过pip 安装的都是比较新的版本,而且扯多一句,用pip的话还可以安装一些历史版本,而apt-get是系统安装过的方法,这样安装的永远
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2186
2186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









