







 本文讲述了如何利用Git进行高效的代码管理和协同工作,以及Docker如何解决环境问题和实现快速部署。通过Git进行版本控制,实现代码的有序管理,避免协同开发中的混乱。同时,Docker作为虚拟容器技术,解决了不同系统间的环境差异,使得开发环境可以轻松迁移。Dockerfile用于自动化构建镜像,提高工作效率。两者结合,为团队协作和项目部署提供了强大支持。
本文讲述了如何利用Git进行高效的代码管理和协同工作,以及Docker如何解决环境问题和实现快速部署。通过Git进行版本控制,实现代码的有序管理,避免协同开发中的混乱。同时,Docker作为虚拟容器技术,解决了不同系统间的环境差异,使得开发环境可以轻松迁移。Dockerfile用于自动化构建镜像,提高工作效率。两者结合,为团队协作和项目部署提供了强大支持。
前言
事情是这样的,首先之前不知道git这个利器,就把代码复制来粘贴去,一个人写代码还好,几个人,特别是一个团队协同工作,这种复制粘贴,U盘拷贝代码,QQ发来发去代码的方式简直就是噩梦,非但麻烦,而且非常凌乱,反正我是受不了。然后,知道git以后才发现自己和它相见恨晚,先别说什么版本控制工具,首先光是托管代码就让我爽一番(svn工作流模式),请注意,我现在是以完全菜鸟的视角阐述,大神们请掠过。
引入了git,整个协同工作有条不紊多了,我的思路也清晰多了,可是问题又来了,项目开始的时候我只是考虑本机开发的问题,嗯,在本机的确没有问题了,但是后面有个新人加进项目后有个问题突然暴露了出来——多人协同开发中除了代码还有环境[环境描述,依赖,缓存,参数,配置等]!首先他和我习惯用不同的系统开发(他用windows,我用linux - -),然后各种环境问题(一会儿缺这个包,一会儿又编译不通过,等下报个错,分分钟折腾死你)。讲真,加班加点不重要,我突然想到,如果以后要部署到很多服务器,那岂不是又要重重复复做同样的功夫?想想都心累,可是docker解决了我这个困扰。
docker是个热门的虚拟容器的技术,其实我是想都没有想过要用到它的时候,虽然我之前知道有docker这么一个玩意,好像很牛逼,但是也就是仅仅停留在知道的程度,至于它能做什么,为什么会存在,我没有任何概念,我曾一度想看懂一点docker,但是各种什么虚拟啊,容器啊,完全搞不懂,想想那时候还是大二的懵懂青春.
git+docker,一个管理代码,一个管理环境
Git
Git相信大家都不陌生,git是linus大神继linux内核以后又一个杰作之一,关于git的历史,可以上Wikipedia看一看,然而在说git之前,我想聊聊svn。
svn也是一种版本控制工具,其实“版本控制工具”这个词乍一听完全不知所云,那就抛开它的定义,直接说它究竟做了什么。一开始呢,写代码的人不多,大家就直接把代码传来传去就好了,对,就是我在前言里面说的各种复制粘贴,QQ传什么的,当然国外不用QQ,可是传着传着就乱套了,你的是什么时候的代码,然后我的又和你发布有什么不同,修改了哪里等等,简直乱成一锅粥,特别是团队的管理者,最不爽就是这种状况,把自己都搞乱了还得了?这时候svn诞生了(当然还有其他的版本控制工具,我这里以svn作为代表),svn是集中式的代码管理,也就是说得有一个中心的svn服务器一直管理着代码,开发者本地是没有这个仓库的,当开发者修改完代码,或者有什么新的代码,就直接提交到中心的svn服务器就好了,非常清楚明确,但是有个很大问题就是,万一中心的svn的服务器挂了呢?或者是我连不上中心的svn服务器?那我岂不是干等着修复问题,而没有办法立即工作?那我打盘阴阳师再回来吧:)
开玩笑的,没有办法立即工作是很不爽的一件事,有什么办法?git,这家伙是分布式的,何为分布式?就是每一个开发者都有一个代码完整的代码仓库,中心服务器就算挂了或者网络无法链接的时候,可以通过其他有仓库的同事克隆一份,而且它可以先提交到本地的仓库,再等中心代码仓库好了或者网络恢复了再一个push命令提交到中心代码仓库,是不是比svn好那么一丢丢?其实基于这个特性,git好的其实不只是一丢丢,不过这个好处得你自己玩玩才能够更加细致地体会了,我就不展开来讲了.
但是svn还是有存在的价值,因为svn的简单易用,而且方便集中式管理,所以企业非常偏爱svn,外加git有一定的学习成本,虽然我倒是不觉得git能有多少学习成本…..- -
Git几点须知
git本身不追踪目录的变化,所以你创建一个空目录,你会发现提交的变更里面并没有这个你创建的空目录,你要问了,如果不追踪目录变化,那为什么我改变了一个目录的名字,而变更又会被包括进去呢?那是因为你这个目录下存在文件,你改变了目录的名字,相当于改变了这个目录下的文件的路径,也就是说改变了文件,所以git要追踪这个变化.
本地的代码仓库由工作区,暂存区和本地分支组成:工作区就是你现在的路径下的文件,而暂存区就是git自己缓存区,把add放在这个区域中,最后就是本地分支,暂存区commit就是commit到本地分支了
工作区<==>暂存区==>本地分支<==>远程仓库分支什么是.gitignore,README.md,LICENCE?
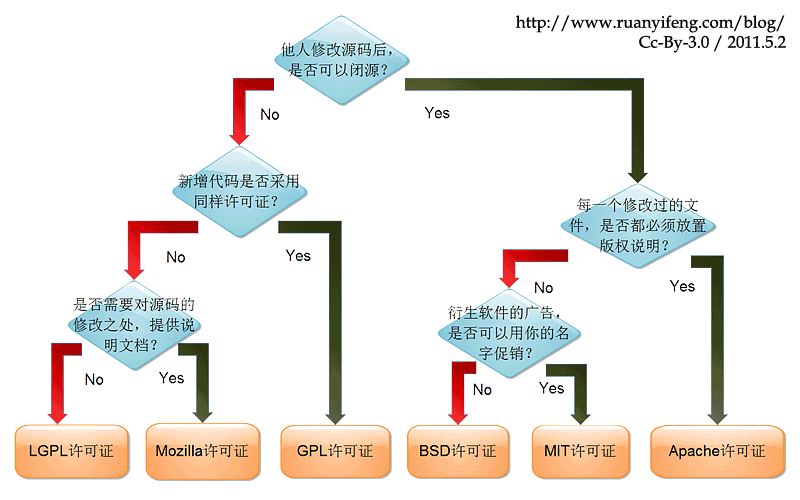
其实我一开始看到github项目里面都会有.gitignore,README.md这两个文件,我也不知道是啥,就懵懵懂懂地往自己的项目加这两个文件,我也是后面才知道,README.md是markdown文件(后面以md作为后缀,markdown写东西体验挺好的,它还有自己的语法,强烈推荐~),里面要写一些你想告诉看你代码的人的话,然后.gitignore的话,我是遇到需要屏蔽一些比如python的pyc文件,不想这些文件放进我的代码仓库,我才知道这个.gitignore有什么用,它就像它字面说的那样ignore一些东西。至于LICENCE的话,主要指的是开源许可,现在主流的就是GPL,BSD,MIT,Apache等等,你可能都有耳闻,它们之间的关系可以这样表达[感谢阮一峰老师做的图解]:这里我稍微梳理下git的常用指令,贴上来供参考
git命令大合集
git init repo #初始化一个叫repo的本地git仓库
#实际上就是创建一个repo的目录,然后目录下放一个.git,.git包含了git的所有记录,判断一个目录是否为git仓库,就看有没有.git目录,有.git目录往下都属于同一个git仓库
#如果你把.git这个目录删除了,你的代码虽然还在,但是你的历史变更记录就全部没有了,所以一般别动这个.git
git add file #往暂存区添加一个叫file的文件
git diff #对比修改内容和git中最新记录的commit的区别,最好在add之前用git diff看一看,避免一些像加了空白键那种无效提交
git add . #往暂存区添加在git status中提示需要add的文件(git status不会提示被.gitignore忽略的文件)
git commit -m "blablabla" #把暂存区的内容正式提交到本地的当前分支,其中那个blablabla就是对本次提交的说明
git commit
# 最近实践发现加了-m,我会尽可能挤成一行来写,但是push到github后,查看commit的时候就发现写的记录信息全部挤在一行,难看死了,有些还被忽略了
# 所以不如直接git commit记录比较全面的信息
# 不过之前得先指定git config --global core.editor /usr/bin/vim,不然貌似默认用的是vi,vi的话就有可能在你保存的时候会崩溃
# 以至于你写的一堆提交信息全没了.
#git commit 还有一个-a的选项,是表示连同未add的文件改动也一同加进来,因为你可能add以后又改动了文件,而一般你前面add了内容就只用-m就可以了,不用-am
git status #查看当前所在git仓库情况
git log #查看提交历史,你会看到你自己之前commit时候的说明,各种blablabla
git reflog #查看操作历史
git clone HTTPS/SSH #克隆一个项目
# 常见的要么就是长成https型的(e.g. https://github.com/tesseract-ocr/tesseract.git)
# 要么就是长成ssh型的(e.g. git@github.com:tesseract-ocr/tesseract.git)
git remote -v #查看远程代 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1837
1837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









