







GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。
GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。
一:回归树
我们先来回顾下那个回归树,这个其实我们在CART的学习中学过了的,
回归树算法如下图(截图来自《统计学习方法》5.5.1 CART生成):

最优切分变量x_j,就是切分选择的那个属性A,这里只是帮回顾下曾经学的,j和s是按照最小化和方差来作为评判标准,最后一共有M个区域,也就是M个叶子节点,每一个区域都选择该区域样本预测值的平均值来作为该区域的代表值。
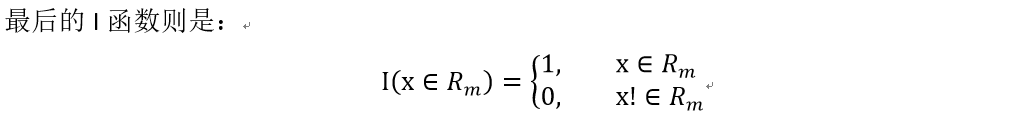
其实就是取对应叶子节点的区域的平均值作为输出。
二:提升树
提升树是迭代多棵回归树来共同决策。当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式:残差 = 真实值y - 预测值f(x) 。提升树即是整个迭代过程生成的回归树的累加。
举个例子,下面这例子较直观地展现出多棵决策树线性求和过程以及残差的意义。
训练一个提升树模型来预测年龄:
训练集是4个人,A,B,C,D年龄分别是14,16,24,26。样本中有购物金额、上网时长、经常到百度知道提问等特征。提升树的过程如下:

该例子很直观的能看到,预测值等于所有树值得累加,如A的预测值 = 树1左节点 值 15 + 树2左节点 -1 = 14。
因此,给定当前模型 fm-1(x),只需要简单的拟合当前模型的残差。现将回归问题的提升树算法叙述如下:

这里的f函数是多个弱回归树T加起来的。且最后一次迭代的那个f_M函数是最强的,也是包含了所有的回归树T。
三:GBDT

1:算法





2:GBDT的损失函数以及相应的负梯度
一共有四个,表达式和负梯度分别是:



3:和提升树的区别
提升树模型每一次的提升都是靠上次的预测结果与训练数据的label值差值作为新的训练数据进行重新训练,
GDBT则是将残差计算替换成了损失函数的梯度方向,将上一次的预测结果带入梯度中求出本轮的训练数据,也就是说这两种模型在生成新的训练数据时采用了不同的方法。在使用平方误差损失函数和指数损失函数时,提升树的残差求解比较简单,但是在使用一般的损失误差函数时,残差求解起来不是那么容易,所以就使用损失函数的负梯度在当前模型的值作为回归问题中残差的近似值。















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









