






一,分类与回归
分类(classification)与回归(regression)本质上是相同的,直观的不同之处在于输出结果是否连续。
引用Andrew Ng的Machine Learning课程给出的定义:
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
(监督学习问题分为“回归”和“分类”问题。 在回归问题中,我们试图预测连续输出中的结果,这意味着我们试图将输入变量映射到某个连续函数。 在分类问题中,我们试图预测离散输出的结果。 换句话说,我们试图将输入变量映射到离散类别。)
Example(例子):
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.(给定有关房地产市场上房屋大小的数据,尝试预测其价格。 作为尺寸函数的价格是连续的输出,所以这是一个回归问题。)
We could turn this example into a classification problem by instead making our output about whether the house "sells for more or less than the asking price." Here we are classifying the houses based on price into two discrete categories.(我们可以把这个例子变成一个分类问题,而不是让我们的输出关于这个房子是“卖出的价格多于还是低于要价”。 在这里,我们将基于价格的房屋分为两类。)
二,决策树(decision tree)与回归树(regression tree)
决策树基于树结构进行决策。
“母亲:给你介绍个对象。
女儿:年纪多大了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。”
这样一个过程可以视为决策树的通俗理解。
则回归树可以理解为输出结果为连续值的决策树。
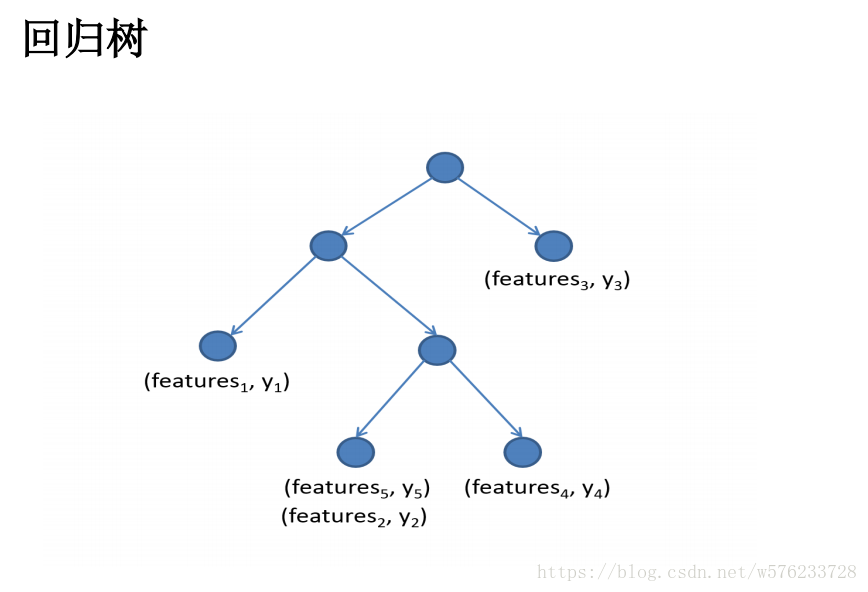
三,GBDT(梯度提升决策树)
GBDT(Gradient Boosting Decison Tree)由多棵回归树组合而成,属于集成学习(ensemble learning)。集成学习又主要包括两种方法Bagging和Boosting(提升)。Boosting方法先训练出一个基学习器,然后根据其表现,进行调整,得到下一个基学习器,最终将t个基学习器加权结合。如下两图:
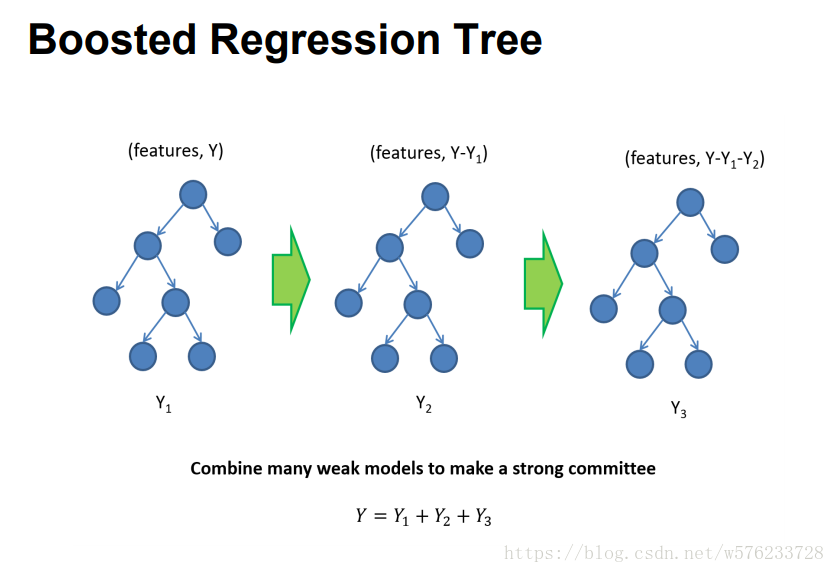
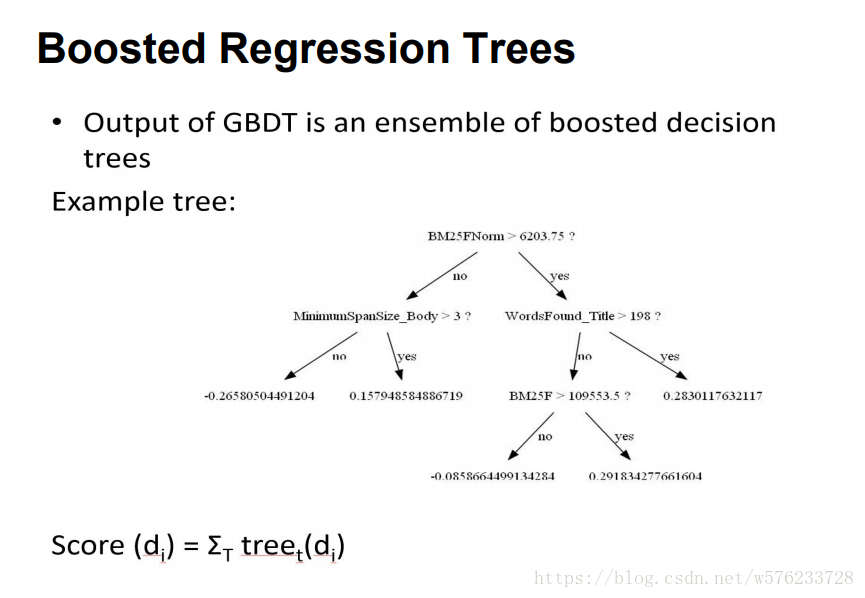
其中,最著名的代表是AdaBoost,是对基学习器的线性组合。
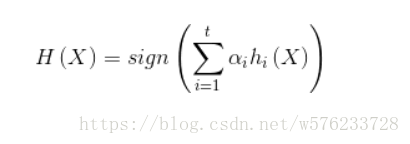
首先GBDT是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
GBDT通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。(偏差:描述的是预测值(估计值)的期望与真实值之间的差距。方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。)因为训练的过程是通过降低偏差来不断提高最终分类器的精度。
GBDT可以表示为:
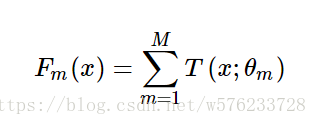
模型一共训练M轮,每轮产生一个弱分类器 T(x;θm)。弱分类器的损失函数:
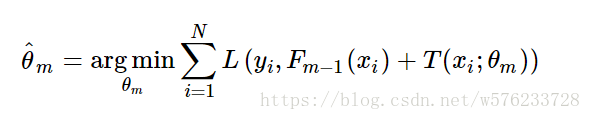
Fm−1(x) 为当前的模型,gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
至此,我们对GBDT有了一个大致的认识,关于GBDT如何选择特征等细节,可以参见ModifyBlog的博文(点击打开链接):https://www.cnblogs.com/ModifyRong/p/7744987.html

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









