







 本文介绍了一个使用Python的re、requests和BeautifulSoup库爬取汽车之家所有车型及配置的教程。通过分析网络请求,获取车型库链接,并逐步解析品牌、型号和配置信息,但遇到一些问题,如空列表和配置数据不完整等。作者分享了整个爬取过程,包括旧版和新版配置库的区别,并提供了部分代码示例。
本文介绍了一个使用Python的re、requests和BeautifulSoup库爬取汽车之家所有车型及配置的教程。通过分析网络请求,获取车型库链接,并逐步解析品牌、型号和配置信息,但遇到一些问题,如空列表和配置数据不完整等。作者分享了整个爬取过程,包括旧版和新版配置库的区别,并提供了部分代码示例。
爬虫项目讲解
我做的是爬取汽车之家全部车型以及配置表的爬虫代码
我们要爬取的就是这个网站 https://www.autohome.com.cn
这边我已经爬取完毕,但是有一些错误,后续说
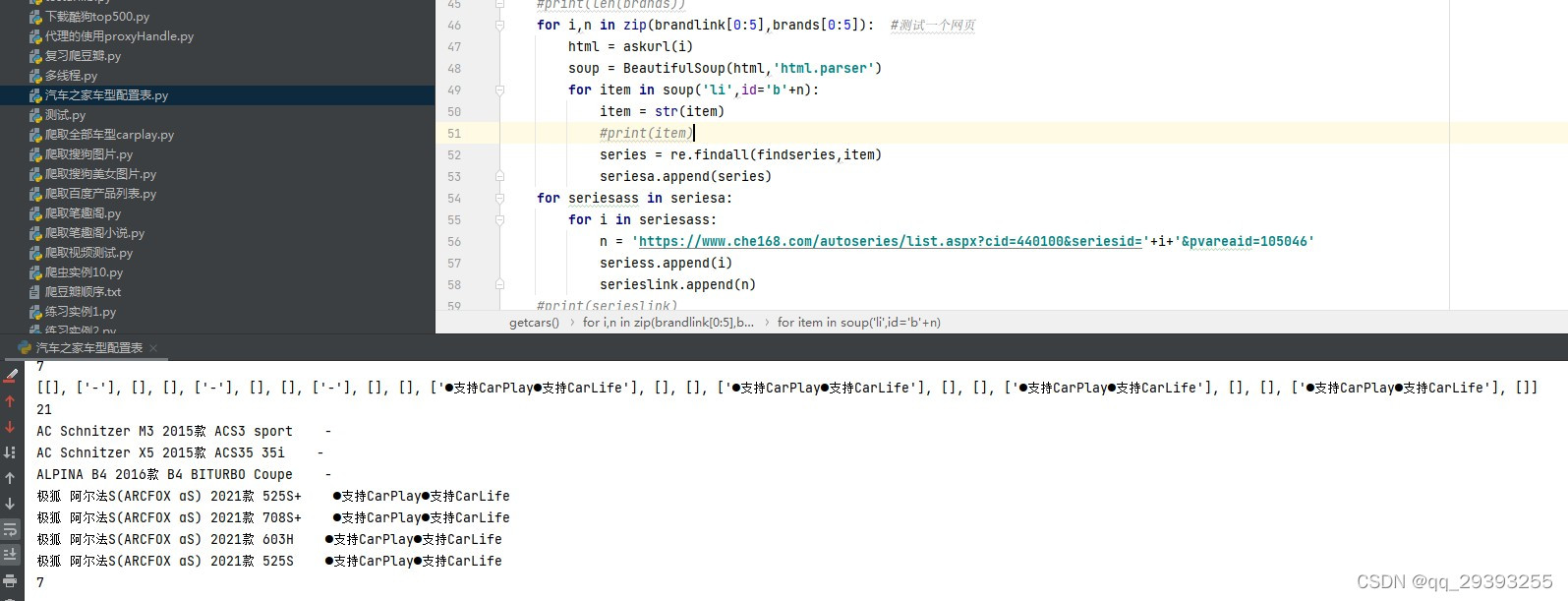
第一步先找到汽车之家全部的车型
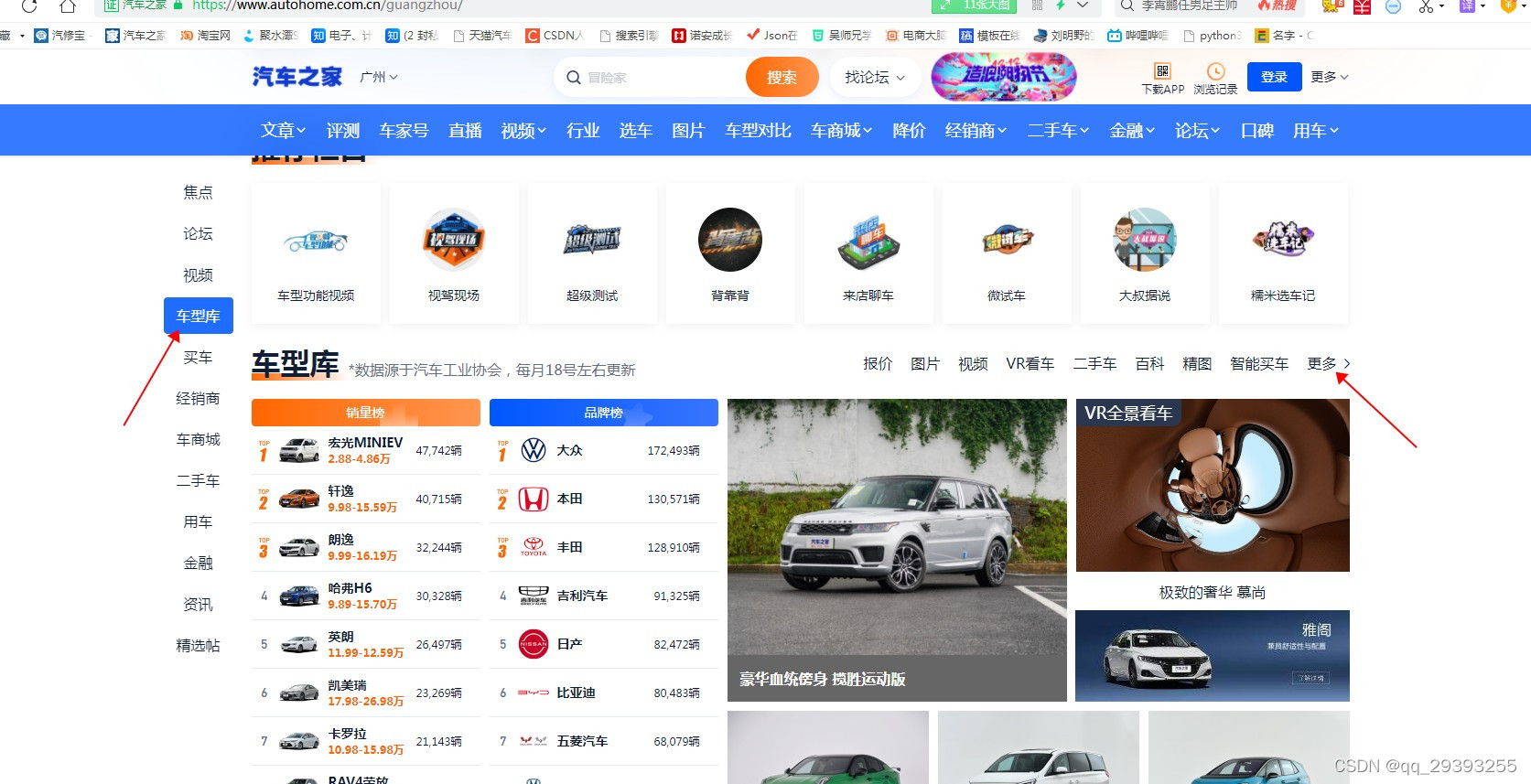
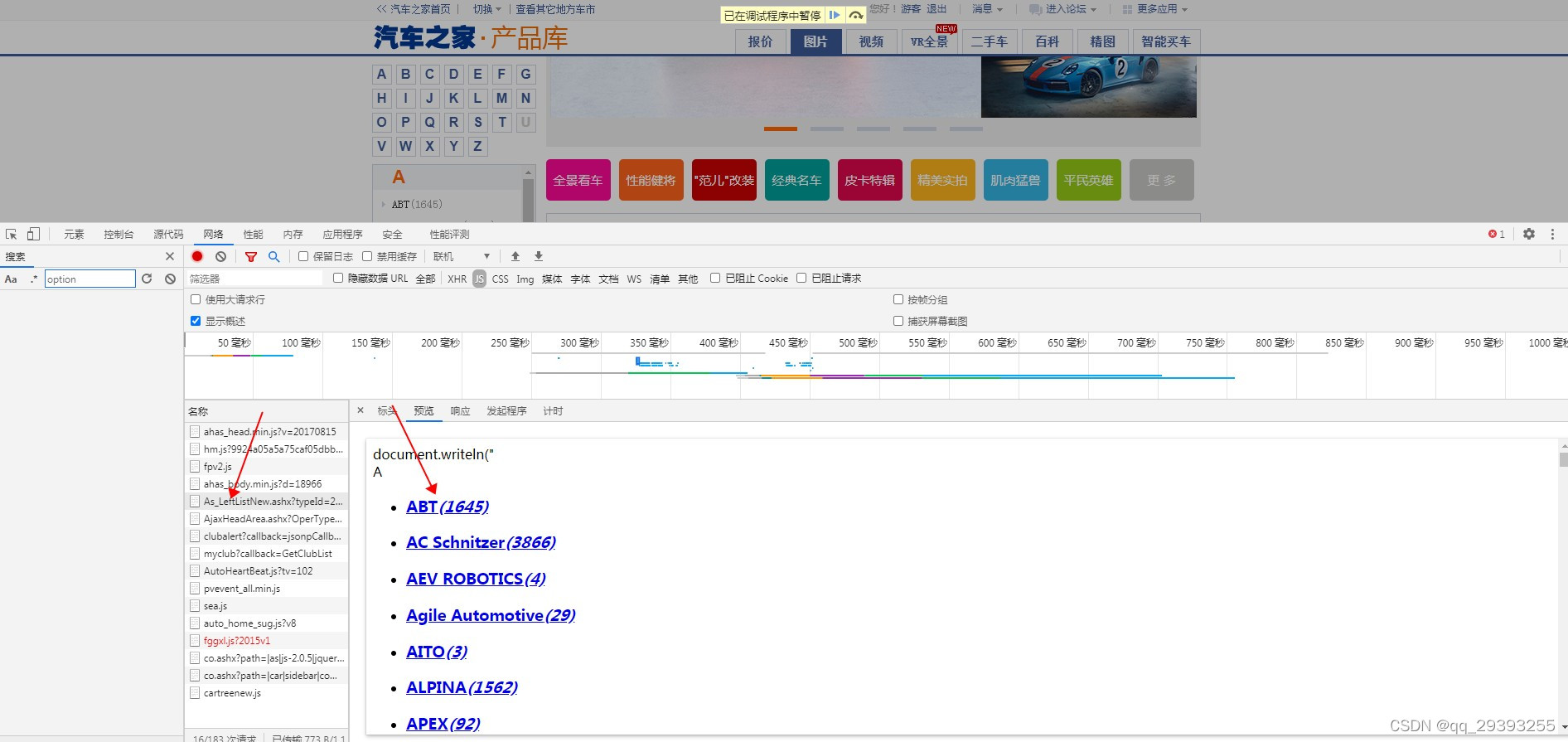
通过刷新网络然后就可以找到了车型库的链接了
原本的车型库地址是上面这个,但是后来搞糊涂了,typeid的值让我换成了1,就将错就错的一直写下去了,不过思路都是一样的(其实是原本的地址车型太多了,更容易出错)
我写的车型库地址是下面这个
找到了车型库的地址那我们就要把全部的车型都给爬出来先
第一步代码如下
#先引入几个爬虫常用的库,都是新手级别的,我也是刚学python几天,没事摸摸鱼练练手
import requests
import re
from bs4 import BeautifulSoup
#1.创建一个访问网页的函数
def askurl(url):
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 QIHU 360SE"
}
html = requests.get(url,headers=headers)
return html.text
#2.先获取到车型库的车型
def getcars():
html = askurl('https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?typeId=1%20&brandId=134%20&fctId=0%20&seriesId=0')
print(html)
#3.运行代码
def main():
getcars()
#4.主程序
if __name__ == '__main__':
main()
运行得到以下的数据,通过观察,可以看到每个厂家都有固定的brand值,那这个brand值的作用就是可以从刚刚的车型库链接获取到车厂所有的车型,例如本田的可以获取到雅阁这个车型的某些值

我们把第一个brand的值替换掉车型库链接的brandid的值,就可以展开车厂所拥有的车型链接了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









