









一、基本信息
标题:Feature Pyramid Networks for Object Detection
时间:2017
引用格式:Lin, Tsung-Yi, et al. “Feature pyramid networks for object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
二、研究背景
为了检测小物体,最常用的做法是构建金字塔,比如SIFT算子需要的用高斯金字塔来实现尺度不变性,而在物体检测方面,就是对图片构建金字塔,然后每层输入到网络中。在深度网络这样做就存在内存和CPU计算开销过大问题。所以本文提出基于卷积层连接的FPN。
三、创新点

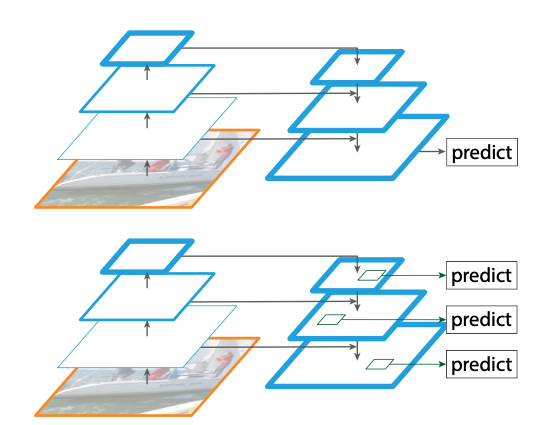
橙色框代表图片,一般由resize/下采样操作产生;蓝色框代表特征图,通过卷积产生,越粗的框代表语义越深。
( a ) 多维度图片输入,多维度特征图预测:图像金字塔,不同尺寸的图输入到网络,底层分辨率高,可以检测细节,高层分辨率低,可以检测轮廓
( b ) 单维度图片输入,单维度特征图预测:拿单层(这里是最后一层)的特征图进行预测,Fast/er R-CNN R-CNN,YOLO v1v2都是这种
( c ) 单维度图片输入,多维度特征图预测:和b相比除了拿最后一层外,还会从后往前多拿几层预测,SSD使用这种方式(但是SSD使用低层的feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。)
( d )单维度图片输入,多维度特征图预测:和c相比可以看到,本层会连接高层的语义,这样做的目的是使每一层不同尺度的特征图都具有较强的语义信息Mask RCNN、YOLO v3使用了这种方式
可不可以用FPN的自顶向下的最下面一层,其高分辨率又具有较强的语义信息?
文献1中就提到用最下面一层,也就是所谓最好的一层。但是本文,它是在以特征金字塔为基础结构上,对每一层级的特征图分别进行预测。效果更好?
FPN
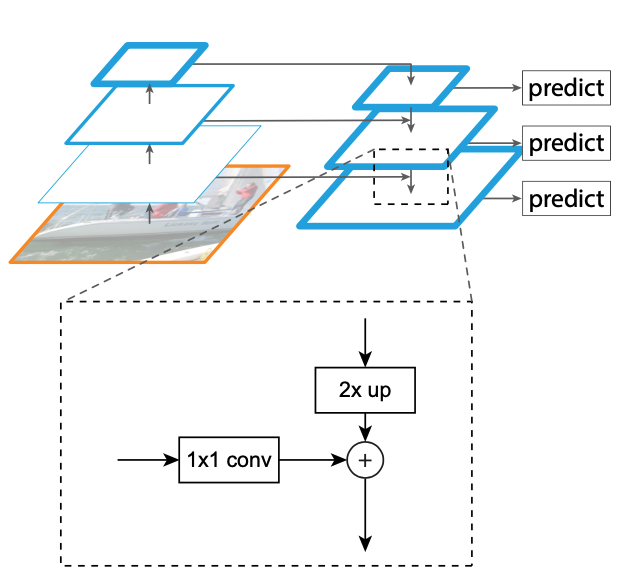
左边就是熟悉的卷积-池化过程,通过卷积池化尺寸变小,维度变高,语义变深这一过程称为自底向上(bottom-up)网络
右边就是FPN的核心思想,是一个从高层语义向底层语义相加的过程,通过最近邻插值,尺寸变大,维度不变,固定通道数了,语义应该也是变浅的过程,但是可以保持高层语义,(换句话说就是FPN可以传递深层语义到高分辨率上),这一过程称为自顶向下(top-down)网络。
既然要相加,就得保持尺寸和维度一样
- 上面提到自顶向下过程中维度不变,怎么保持维度不变?
侧连接那边先经过1 x 1卷积,改变特征图的通道数(文章中设置d=256,与Faster R-CNN中RPN层的维数相同便于分类与回归),所以维度始终是给定的d
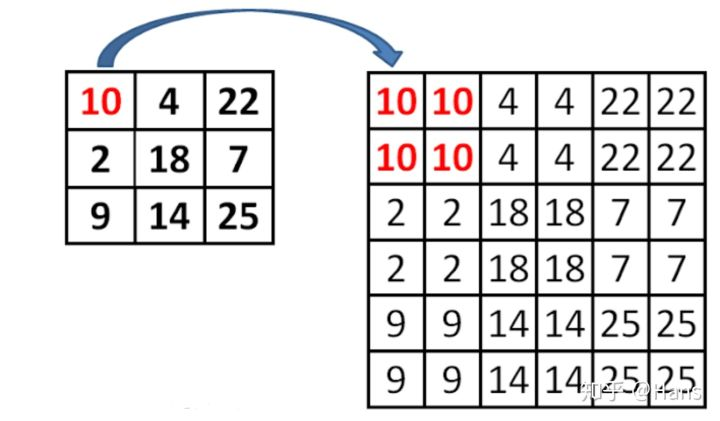
- 上面提到自顶向下过程中尺寸变大,怎么保存相加时尺寸一样?
高层到到底层用的是最近邻插值法,而对应的侧连接尺寸对应也变大
最近邻插值法:
自底向上(左)和自顶向下(右)
细节
注意到,侧连接后还进行了 3 * 3 卷积,这么做的目的可以看最近邻带来的影响,周围都一样了,所以,3 * 3 卷积的目的就是减轻最近邻近插值带来的混叠影响。
图片来自FPN详解,漏了部分没画:p4 p3 p2后面要接3 * 3卷积再接2支路(cls + reg)的1 * 1卷积
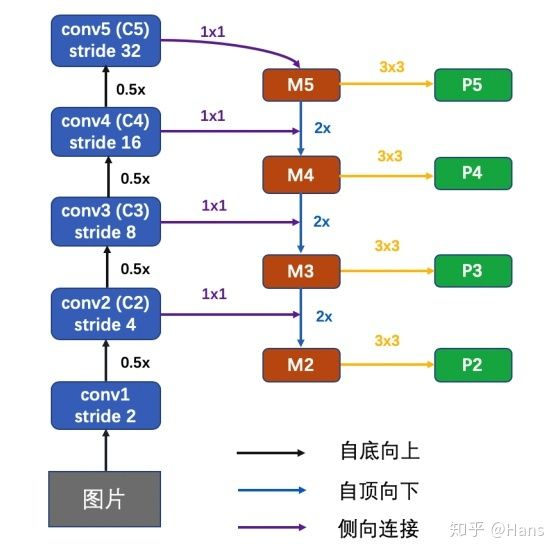
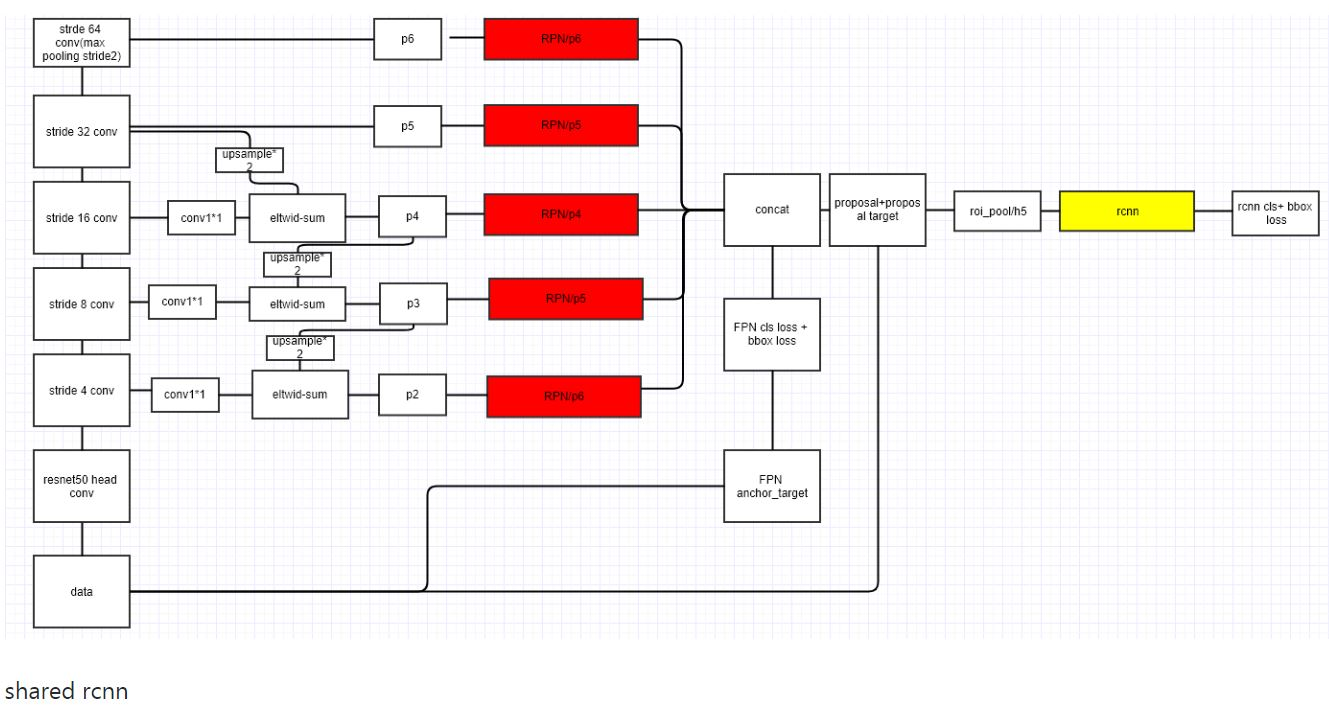
看上面图有个P6,目的是?
FPN针对RPN的改进是将网络头部应用到每一个P层。由于每个P层相对于原始图片具有不同的尺度信息,因此作者将原始RPN中的尺度信息分离,让每个P层只处理单一的尺度信息。具体的,对{32、64、128、256、512}这五种尺度的anchor,分别对应到{P2、P3、P4、P5、P6}这五个特征层上。每个特征层都处理1:1、1:2、2:1三种长宽比例的候选框。P6是专门为了RPN网络而设计的,用来处理512大小的候选框。它由P5经过下采样得到。
FPN产生了特征金字塔 [P2、P3、P4、P5、P6] ,而并非只是一个feature map。金字塔经过RPN之后会产生很多region proposal。这些region proposal是分别由 [P2、P3、P4、P5、P6] 经过RPN产生的,但用于输入到Fast RCNN中的是 [P2、P3、P4、P5] ,也就是说要在 [P2、P3、P4、P5] 中根据region proposal切出ROI进行后续的分类和回归预测。问题来了,我们要选择哪个feature map来切出这些ROI区域呢?实际上,我们会选择最合适的尺度的feature map来切ROI。具体来说,我们通过一个公式来决定宽w和高h的ROI到底要从哪个
P
k
P_k
Pk 来切:
k
=
⌊
k
0
+
log
2
(
w
h
/
224
)
⌋
k=\left\lfloor k_{0}+\log _{2}(\sqrt{w h} / 224)\right\rfloor
k=⌊k0+log2(wh/224)⌋
这里224表示用于预训练的ImageNet图片的大小。
k
0
k_{0}
k0 表示面积为
w
×
h
=
224
×
224
w \times h=224 \times 224
w×h=224×224 的ROI所应 该在的层级。作者将
k
0
k_{0}
k0 设置为4,也就是说
w
×
h
=
224
×
224
w \times h=224 \times 224
w×h=224×224 的ROI应该从
P
4
P_4
P4 中切出来。假设ROI的scale小于224(比如说是112
∗
^{*}
∗ 112) ,
k
=
k
0
−
1
=
4
−
1
=
3
\quad k=k_{0}-1=4-1=3
k=k0−1=4−1=3 ,就意味着要从更高分辨 率的
P
3
P_{3}
P3 中产生。另外,
k
k
k 值会做取整处理,防止结果不是整数。
这种做法很合理,大尺度的ROI要从低分辨率的feature map上切,有利于检测大目标,小尺度的 ROI要从高分辨率的feature map上切,有利于检测小目标。
转自 https://zhuanlan.zhihu.com/p/37998710
四、实验结果
五、结论与思考
作者结论
总结
思考
参考
FPN —— 特征金字塔
FPN详解
[1]P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dolla ́r. Learn- ing to refine object segments. In ECCV, 2016.

















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









