









如果说地球上有哪个市场急需激烈竞争,那就是推动人工智能革命的数据中心 GPU 市场。Nvidia 几乎拥有它。
但随着时间的推移,AMD 的 Instinct GPU 加速器变得越来越有竞争力,随着今天推出的 Instinct MI325X 和 MI355X,AMD 可以在 GPU 级别与 Nvidia 的“Hopper” H200 和“Blackwell” B100 相媲美。
但 AMD 非常清楚,人们购买系统时,会配备互连、系统软件、AI 框架以及 GPU 加速器,而在这方面,Nvidia 在许多方面仍然具有决定性的优势。但话又说回来,如果你无法获得 Nvidia GPU(许多公司都无法获得),那么 AMD GPU 的表现会比在 GenAI 热潮中袖手旁观要好得多。
此外,AMD 正在利用其 ROCm 堆栈追赶 CUDA,并计划与其UALink 合作伙伴共同开发一种一致的内存互连,以与 Nvidia 专有的 NVLink 和 NVSwitch 结构相竞争,从而实现机架规模甚至行规模系统。
但在旧金山举行的 Advancing AI 活动上,有关 MI325X 和 MI355X 的更多细节的揭晓以及未来 MI400 的暗示可能是讨论的最重要的事情。每个人都想要具有更广泛混合精度和更多 HBM 内存容量和带宽的 GPU 加速器。
让我们从 MI325X 开始吧,它的速度和进给与我们在 6 月份 Computex 贸易展上看到的产品略有不同。
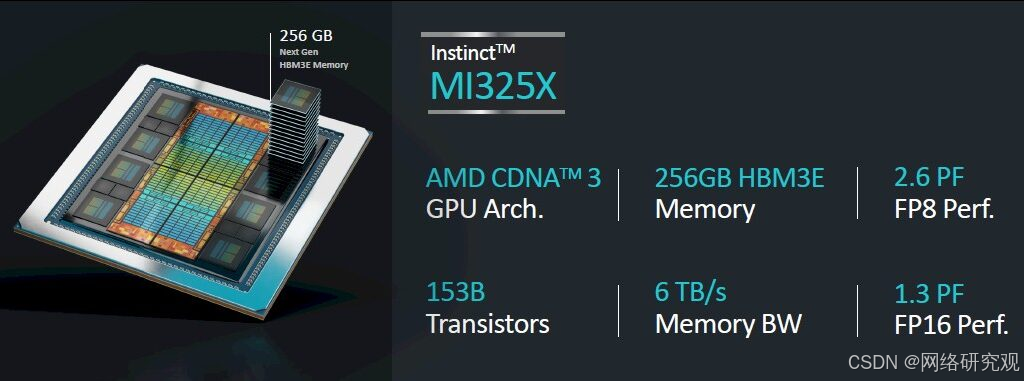
上面显示的速度图表显示,MI325X 复合体有 1530 亿个晶体管,这是一个巨大的封装晶体管数量。浮点数学性能为 FP16 半精度 1,307.4 teraflops,FP8 四分之一精度 2,614.9 petaflops,与四个月前宣传的完全一致。
但是,MI325X 的内存容量有点不足。最初,AMD 表示预计这八个 HBM3E 内存堆栈将有 288 GB,但由于某种原因(可能与十二高 3 GB 内存堆栈的产量有关),它只有 256 GB。内存带宽与 6 月份宣布的相同,即这八个 HBM3E 堆栈的 6 TB/秒。
MI325X 具有与现有的“Antares”MI300X GPU 相同的性能,事实上,MI325 是相同的计算复合体,采用中国台湾半导体制造公司相同的 4 纳米工艺蚀刻,其功率从 750 瓦提升至 1,000 瓦,以便能够驱动更大的 HBM 内存容量和更高的带宽。
MI300X 拥有 192 GB 稍慢的 HBM3 内存,其封装总带宽为 5.3 TB/秒。据我们所知,位于 GPU 块和 HBM3 或 HBM3E 内存之间的 256 MB Infinity Cache 是相同的。
MI325X 可以接入与 MI300X 相同的插槽和 Open Compute 通用基板服务器平台,因此无需创建新的服务器设计来容纳这些 MI325X。当然,您必须具有足够的热容量来冷却它们。
以下是使用 MI325X 的八路 GPU 节点的馈送和速度:
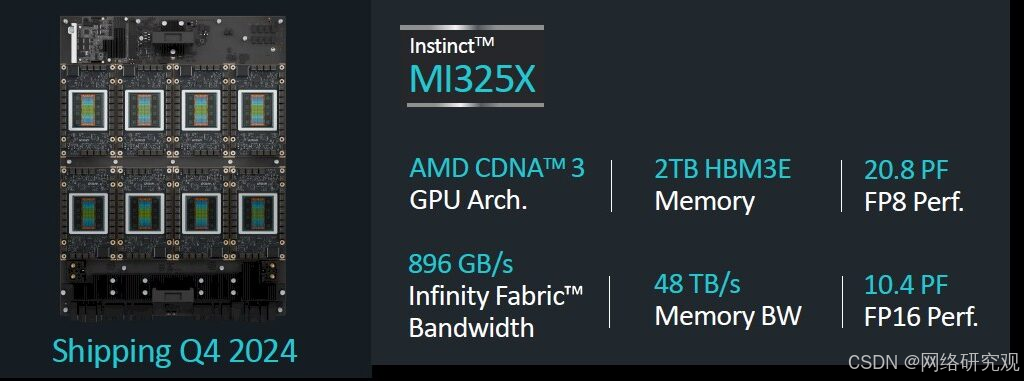
每个 MI300 系列 GPU 都有七个 128 GB/秒的 Infinity Fabric 链路,这使得它们能够在节点内部以全对全、共享内存配置连接。
AMD 首席执行官 Lisa Su 在发布会上表示,MI325X 将在本季度末开始出货,并将于明年第一季度在合作伙伴产品中投入使用。这差不多也是 Nvidia 推出 Blackwell B100 GPU 的时间。
但目前,AMD 满足于将 MI325X 与大内存 Hopper H200 GPU 进行比较,后者在其六个堆栈中配备 141 GB 的 HBM3E 内存和 4.8 TB/秒的带宽。在这里,AMD 在 GPU 内存容量方面具有 1.8 倍的优势,这意味着加载特定模型的参数所需的 GPU 数量减少了 1.8 倍,在带宽方面具有 1.25 倍的优势,这意味着将这些参数提供给 GPU 所需的时间更少。(考虑内存容量与带宽对 AI 训练性能的影响很有趣,但我们现在没有时间这样做……)
以下是苏姿丰在此次活动中展示的 Mi325X 与 H200 的基准测试结果:
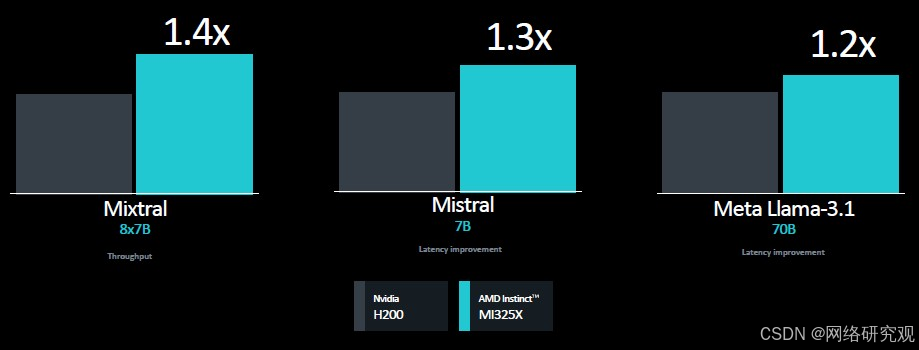
在这三项推理测试中,性能似乎主要由 MI325X 和 H200 之间的带宽差异决定,其中有些波动。上图左侧显示的 Mixtral 基准测试测量的是推理吞吐量,其中内存容量可能更重要,而 Mistral 和 Llama 3.1 测试测量的是推理延迟,这似乎是由 HBM 带宽决定的。
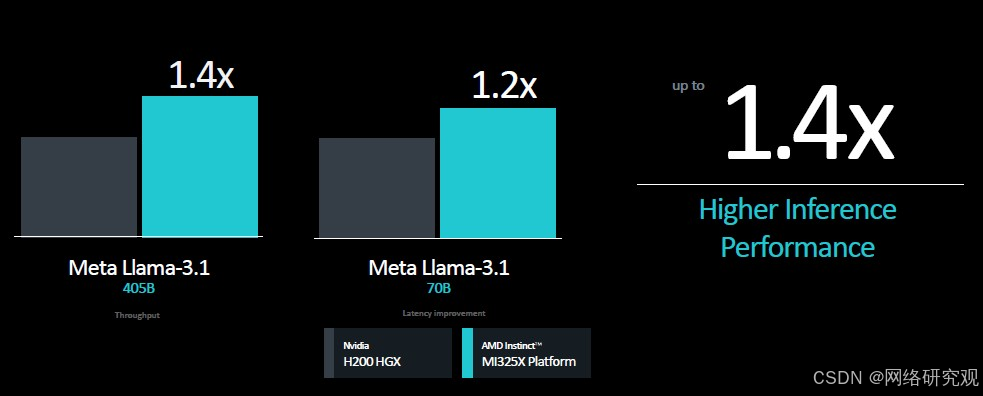
有了八个 GPU 平台,所有这些优势都会按比例扩大:

以下是 Llama 3.1 基准测试的一些性能规格,其中 700 亿和 4050 亿个参数证明了这一点:
我们一直在等待看到一些 AI 训练的基准,AMD 终于为我们提供了两个数据点,使用 Meta Platforms 的旧款 Llama 2 模型:

对我们来说,有趣的是,当使用单个设备时,MI325X 的性能比 H200 高出 10%,但当移动到八路 GPU 节点时,这种优势就消失了。我们猜测,与 Nvidia HGX 机器中使用的 NVSwitch 互连相比,Infinity Fabric 的速度不够快,这很有帮助。
但在性能同等的情况下,也许 NVSwitch 和 H200 HGX 综合体中那些巨大的 900 GB/秒 NVLink 管道并没有我们想象的那么有帮助。至少对于 Llama 2 推理来说是这样。
AMD,Llama 3.1 训练数据在哪里?这才是现在最重要的。
接下来,我们将关注 Instinct MI350 系列 GPU,这将是一个产品系列,而我们今天了解到,其中第一款产品将是 MI355X。
MI350 系列将采用 CDNA 4 架构,该架构可能借鉴了预计于 2026 年推出的 MI400 系列数据中心 GPU。MI350 系列将采用台积电的 3 纳米工艺蚀刻,并且可能在一个插槽中安装八个芯片。(除非您将芯片矩形放在侧面,否则十个芯片太高太瘦了。)
正如 6 月份透露的那样,MI350 系列将是 AMD 首款支持 FP4 和 FP6 浮点数据格式的 GPU,它们将配备 288 GB 的 HBM3E 内存,采用 3 GB 的 12 高堆栈。HBM3E 内存的带宽为 8 TB/秒,大概是 8 个堆栈。
无论 CDNA 4 架构如何,MI355X 插槽都将提供 1.8 倍于 MI325X 的性能,即在 FP16 精度下为 2.3 千万亿次浮点运算,在 FP8 精度下为 4.6 千万亿次浮点运算,在 FP6 或 FP4 精度下为 9.2 千万亿次浮点运算。(这不包括稀疏矩阵支持,如果您没有进行数学运算的密集矩阵,这会使吞吐量提高两倍。)
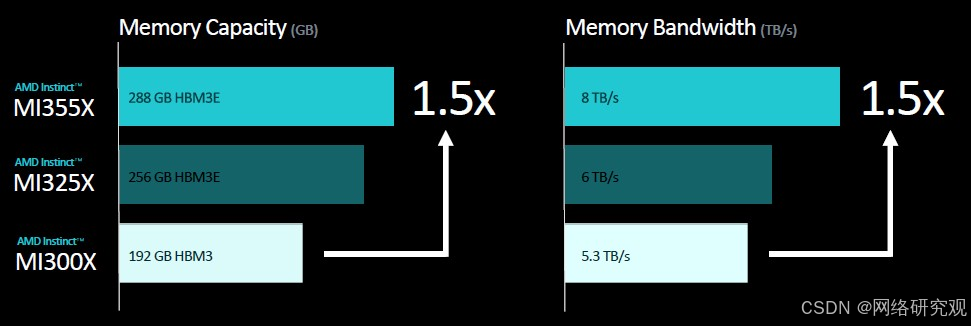
这就引出了一个问题:MI355X 相对于 MI325X 而言是否内存不足。如果 MI325X 的计算与内存比率在 288 GB 和 6 TB/秒之间保持平衡,那么我们预计 MI355X 将拥有 512 GB 的 HBM3E 内存容量和 14.4 TB/秒的内存带宽。我想我们都同意,这将是一台非常棒的设备。
无论如何,以下是八路 MI355X 系统板的进给和速度:

这显示了 MI300X、MI325X 和 MI355X 上的八路系统板如何跨越性能范围和参数大小:
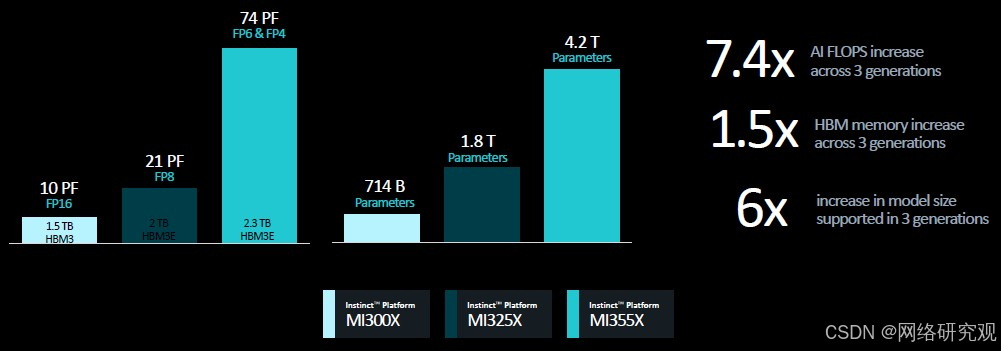
还记得 5000 亿个参数听起来很多吗?现在,几十万亿似乎没什么大不了的。
看看 MI400 系列中使用的 CDNA-Next 架构是什么样子,以及 AMD 使用什么样的疯狂封装来将更多东西塞进插槽,这将会很有趣。我们也很乐意看到 AMD 正在进行的产能规划,以试图从 Big Green 手中抢走更多业务。一切都取决于 HBM 的可用性。


















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











