







NeoRL-2: Near Real-World Benchmarks for Offline Reinforcement Learning with Extended Realistic Scenarios 阅读笔记
本篇文章是NEORL的延续工作,NEORL发表于2021 NIPS
arXiv:https://arxiv.org/abs/2503.19267
提交时间 [V1] TUE, 25 MAR 2025 02:01:54 UTC
一、Abstract
离线强化学习(RL)旨在无需(高成本)访问环境的情况下从历史数据中学习。为推动离线 RL 研究,我们先前提出了 NeoRL,其指出现实任务数据集通常保守且有限。通过多年将离线 RL 应用于多领域的经验,我们识别出更多现实挑战:包括已部署控制系统产生的极端保守数据分布、高延迟转换导致的动作延迟效应、源自不可控转换变异的外部因素,以及决策过程中难以评估的全局安全约束。这些挑战在先前基准中代表性不足,却频繁出现在现实任务中。为此,我们构建了扩展版近真实世界离线 RL 基准(NeoRL-2),包含来自7个模拟任务的 7 组数据集及其对应评估模拟器。 当前最先进的离线强化学习方法的基准测试结果表明,现有方法往往难以超越数据收集行为策略的表现,这凸显了对更有效方法的迫切需求。我们希望 NeoRL-2 能加速强化学习算法在现实世界应用中的发展。基准项目页面详见 https://github.com/polixir/NeoRL2。
二、Induction
这里精简一下原文的篇幅
强化学习(RL)通过环境试错学习最优策略,已在游戏、推荐系统乃至托卡马克控制等领域取得显著成果。然而,当缺乏快速低成本的模拟器时,传统RL方法难以实施,这促使了离线RL的发展。现有离线RL基准(如D4RL和RL Unplugged)虽然推动了领域进步,但其基于理想化任务的数据集往往无法反映现实应用的复杂性。
现实场景中存在诸多关键挑战:
-
1)观测与奖励的时间延迟(如工业控制系统中的信号传输延迟);
-
2)不可控的外部干扰(如无人机飞行中的风力影响);
-
3)严格的安全约束(如设备运行参数限制);
-
4)由传统控制方法生成的有限数据集(通常缺乏探索性)。
为弥合这一差距,我们提出NeoRL-2基准,其创新性体现在:
-
1)覆盖机器人、航空器、工业管道等7个领域,系统性地引入延迟、外部干扰和安全约束;
-
2)采用更贴近实际的数据采集方式,包括基于PID控制器的确定性采样;
-
3)实验表明,当前最先进的离线RL算法在多数任务中难以超越行为策略的表现。
NeoRL-2旨在为离线RL研究提供更贴近现实的测试环境,推动算法在延迟容忍、抗干扰能力和安全性等方面的进步。由于实际业务数据的隐私性和获取难度,我们通过专用模拟器构建数据集,这些模拟器虽不追求物理精度,但能有效复现关键的实际挑战。
这个基准想传递的是:RL要真正落地,得先学会在"脏数据、窄空间、慢反应"的现实中生存。
三、Related Work
离线强化学习
离线强化学习(Offline RL)的核心是从预先收集的历史数据中学习策略,而无需与环境实时交互。这一特性使其在医疗健康、工业控制、机器人及自动驾驶等领域具有重要应用价值——这些场景往往存在交互成本高、风险大或难以实时获取数据的问题。
现有方法主要分为两类:
- 无模型方法:直接从数据中学习策略或价值函数(如Q学习、策略梯度),不显式建模环境动态;
- 基于模型的方法:先学习环境动态模型,再通过模拟进行策略优化。
针对离线RL的固有挑战(如分布偏移、稀疏奖励),研究者提出了三类主流解决方案:
- 策略约束方法:限制学习策略与行为策略的差异(如BCQ);
- 不确定性估计方法:利用价值函数或策略的不确定性指导学习(如BEAR);
- 价值函数正则化:通过正则项防止策略偏离数据分布(如CQL)。
离线强化学习基准
现有三大基准针对不同需求设计:
- D4RL:
- 通过多样化策略(人工控制器、人类示范)生成数据;
- 覆盖数据分布偏置、稀疏奖励等现实问题。
- RL Unplugged:
- 基于Atari游戏和运动控制任务;
- 强调离线学习的成本与安全性优势。
- NeoRL:
- 聚焦现实场景的保守数据特性;
- 引入有限数据量和离线策略评估机制
四、The Reality Gap
Motivation of NeoRL-2
此前,NeoRL 基准仅考虑了来自现实任务的基本数据属性,这些数据由带有小噪声的保守策略收集,且数据集规模有限。在发布 NeoRL 后我们的离线强化学习实践中,遇到了更多未被 NeoRL 或其他离线 RL 基准反映的难题。这些场景中面临的问题可归类为时间延迟、外部因素、策略约束、基于传统控制方法收集的数据,以及数据限制(甚至比 NeoRL 中的约束更为严格)。
由于现实世界是开放的且任务极其复杂,NeoRL-2 基准中的 7 个任务场景无法涵盖所有挑战。我们的目标在于总结现实环境中的挑战,并创建能更准确反映这些挑战的模拟器,而非提供高保真度的仿真环境。因此,最实用的策略是在模拟环境中尽可能真实地映射现实问题。此外,这些特性确实增加了任务难度并导致数据不完整。我们希望通过 NeoRL-2 推动学界在将离线强化学习应用于现实任务时,更加关注这些挑战。
NeoRL-2基准的提出源于现有离线强化学习测试环境与现实应用需求之间的显著差距。
该基准针对五个关键现实挑战——系统响应延迟、环境干扰因素、操作安全约束、传统控制数据特征以及数据规模限制,构建了7个具有代表性的测试任务。
不同于追求仿真精度,NeoRL-2更注重在可控环境中还原这些核心挑战的本质特征,为评估算法在实际复杂场景中的适应能力提供了更可靠的测试平台,有助于推动离线强化学习技术从理论到应用的转化。
Environment Properties
先前提出的基准测试在推动离线强化学习技术发展中发挥了重要作用。然而,根据我们的研究,我们发现现实世界任务与这些基准任务之间存在显著差距。现实任务通常更为复杂且具有挑战性。在此,我们阐述了现实任务中常见但现有基准测试常忽视的几项特性:
- 延迟:延迟可能由多种因素引起,包括传感器采样延迟、信号传输延迟及响应延迟。这种现象在不同任务中普遍存在,增加了任务的不确定性和学习难度,导致系统理解中的复杂因果关系。延迟不仅可见于状态转换过程中,也体现在奖励获取环节。
- 外部因素:外部因素是指能够影响当前系统但不受当前内部系统影响的那些因素。这些变量的变化可能改变系统环境的状态分布,从而影响奖励信号和策略的有效性,进一步增加了任务的复杂性和挑战性。
- 约束控制策略:现实世界中的任务常伴随多种约束,这些约束反映了系统的物理限制、安全需求、操作标准或资源限制,而数据集可能仅包含满足约束条件的数据。因此,由于缺乏探索,离线算法只能从满意数据中学习,无法明确知晓当前动作是否会违反约束。
- 传统控制方法的数据:在现实世界,尤其是工业领域,实际运行的控制模型通常采用传统控制方法,如 PID。使用这些传统方法收集的数据往往分布狭窄,难以建模。此外,这些传统方法常依赖反馈控制,可能导致学习到错误的转移关系。
- 数据可用性的限制:在许多现实任务中,获取大量训练数据可能不切实际,导致数据不足的问题。在某些特殊场景下,理想情况下只能收集到少量数据轨迹,这对离线策略的优化构成了重大挑战。我们进一步减少数据集规模以匹配现实场景。
因此,我们提出 NeoRL-2 作为对现有基准的补充和改进。NeoRL-2 中的任务覆盖了更广泛的现实应用场景,包括时滞环境转移、外部影响因素、全局约束、从传统控制方法收集的数据以及有限的数据可用性。
延迟、外部影响、受限控制策略以及源自传统控制方法的数据等因素显著增加了任务复杂性,并导致数据不完整。例如,较大的延迟会使动作效果持续无限长的时间,从而使控制策略变为非马尔可夫性。策略约束通常将数据收集限制在仅安全的状态和动作上,导致空间覆盖不完整。此外,外部因素可能引入变异性,且未必在数据集中明确体现。所有这些因素直接导致观测信息的不完整性,逐渐偏离标准的 MDP/POMDP 假设。由于当前许多离线强化学习算法忽视了这些问题,这些挑战可能带来重大困难。
NeoRL-2给离线强化学习出了五道"现实考题":
1)信号总是"慢半拍"的延迟难题;
2)爱捣乱的外部干扰因素;
3)戴着安全枷锁的约束条件;
4)老派控制器留下的"保守"数据;
5)少得可怜的训练样本。
这些现实特性让标准算法直呼"水土不服",而NeoRL-2就是要打造一个既真实又不失焦的测试场,让算法提前适应现实世界的"不完美"。
五、NeoRL-2 Tasks and Datasets
本节将简要概述 NeoRL-2 中包含的所有任务。每项任务由对应的环境与数据集构成,其中数据集用于策略训练,环境则用于策略测试。
Tasks
接下来,我们将简要介绍 NeoRL-2 中包含的 7 项任务。这些任务包括一个管道流动任务和一个人体血糖浓度模拟器,两者均表现出显著的时间延迟特性。此外,我们还开发了两个额外环境:火箭回收(Rocket Recovery)和随机摩擦单足跳跃器(Random Friction Hopper)。在这些环境中,存在需要作为观测一部分的外部因素。为便于使用 PID 控制方法收集数据,我们构建了双质量弹簧阻尼器(DMSD)环境。再者,安全猎豹(Safety Halfcheetah)是一个施加动作约束以确保行为处于安全范围内的模拟任务。最后是融合环境(Fusion),它代表了现实世界中离线数据收集成本极高的任务类型。在这些任务中,离线数据的采集尤为昂贵,使得融合环境成为此类任务的典型代表。
Pipeline. Pipeline 模拟器模拟了水流以固定速度通过 100 米长管道的过程。控制器的目标是通过调节进水闸门来调控流量。模拟运行 1000 个时间步长,出口处的目标流量受外部策略影响,并从集合[50, 80, 110, 140]中随机选取。每个时间步长有 0.3%的概率改变目标流量,平均每次模拟会发生三次变化。
Simglucose. Simglucose 模拟器精确模拟了糖尿病患者从早上 8 点开始一天内复杂的血糖浓度变化。该综合模拟器包含患者模拟、场景模拟、传感器模拟和胰岛素泵模拟。患者随机进食和服药,其效果随时间逐渐显现。策略的主要目标是安全控制用药方案,确保血糖水平保持在理想范围内,同时考虑药物的延迟效应。这一环境在优化和完善糖尿病治疗策略方面极具价值。
RocketRecovery. 火箭回收模拟器基于Gym中的lunar_lander环境(参见:https://www.gymlibrary.dev/environments/box2d/lunar_lander/)进行改造,新增风力作为外部干扰因素。该任务的目标是让火箭在保证安全角度和速度的前提下,尽可能精准地安全着陆。这一环境呈现了经典的火箭轨迹优化问题。
RandomFrictionHopper. 该模拟器是经典单腿机器人跳跃移动任务的变体,通过控制腿部动作实现运动。每次初始化时,地面摩擦系数会在[1.5, 2.5]范围内随机设定,并作为状态观测的扩展维度。这一变化为任务动力学引入了可变性。
DMSD. 双质量弹簧阻尼器模拟器涉及两个通过弹簧和阻尼器连接的质量块。任务要求施加力以控制和稳定这些质量块至目标位置。值得注意的是,相互连接的弹簧和阻尼器意味着对一个质量块施加力会影响另一个。模拟中的每一步对应于现实世界中的 0.2 秒,且在自动截断前有 100 步的限制。
SafetyHalfCheetah. SafetyHalfCheetah 模拟器是 HalfCheetah 任务的一个变体,强调安全的高速奔跑。在此任务中,机器人必须以最快速度冲刺,同时确保其运动保持在安全限度内,以防止事故和损坏。该任务平衡了速度与安全性,模拟了现实世界中需要高速但安全的机器人移动场景。一旦智能体违反约束条件,环境将终止并给予较大的负分。
Fusion. Fusion 模拟器模拟了用于核聚变的托卡马克装置控制,其目标在于仅依据观测状态来控制托卡马克装置,并尝试在运行过程中将系统稳定于目标位置。然而,现实中开展托卡马克装置实验的成本极高,使得该环境下收集的离线数据尤为珍贵且数据稀疏。鉴于托卡马克装置数值模拟的复杂性及数值模拟与实际装置状态间存在的固有误差,研究采用了 LSTM 神经网络模型基于收集数据对托卡马克装置进行“克隆”。我们将该“克隆”模型视为 Fusion 任务的模拟器。
NeoRL-2基准精心设计了7个典型任务环境,系统性地模拟现实场景中的核心挑战:Pipeline和Simglucose着重刻画时滞特性,分别模拟管道流量控制和糖尿病患者血糖管理这类具有显著延迟效应的控制问题;RocketRecovery和RandomFrictionHopper引入风力、随机摩擦系数等外部干扰因素;DMSD环境专为传统PID控制方法的数据采集而设计;SafetyHalfCheetah突显安全约束下的决策难题;Fusion环境则复现了托卡马克装置控制这类数据获取成本极高的尖端应用场景。这些任务既保留了标准测试环境的可重复性,又通过关键特性的精准建模,为算法评估提供了贴近现实的测试平台。
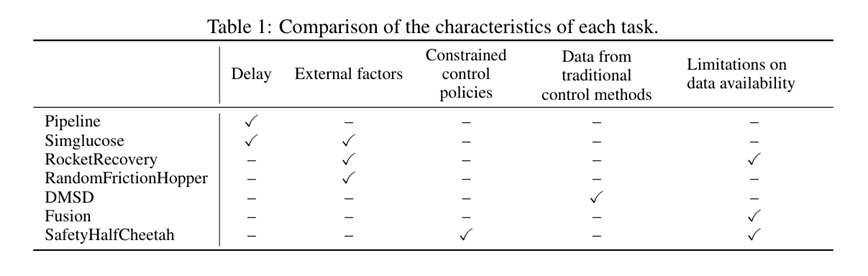
表 1 用五个属性标记了每项任务的特征
Datasets
在实际场景中,数据通常通过保守策略收集。针对大多数环境,我们采用 Soft Actor-Critic(SAC)算法进行在线策略训练以获取高性能策略。训练过程中,每轮结束后记录策略模型,并依据性能排序。考虑到现实方法常为非最优策略,我们随机选取排名位于 20%-75%区间内的策略作为采样策略。在 DMSD 环境中,运用贝叶斯优化参数搜索方法精细调节 PID 控制器的三个关键参数。根据性能对所有 PID 进行排序,并选用性能排名 56%的 PID 作为 DMSD 数据集的离线数据采样策略。
在确定采样策略后,我们通过所有内置环境模拟器收集数据。现实任务中通常仅采用单一策略构建离线数据集,导致多样性不足。因此,NeoRL-2 特别强调所有策略在与环境交互收集数据时均为确定性策略。收集的数据随后划分为训练集与验证集,每个环境包含 10 万条训练样本和 2 万条验证样本。值得注意的是,由于受控核聚变实验的高成本特性,Fusion 环境采用独特的数据采样流程——我们将实验轨迹数量限制为 2000 条训练样本和 500 条验证样本。类似的数据限制也存在于 Rocket Recovery 和 Safety Halfcheetah 环境中,具体参数详见附录 B 表 4(感兴趣的去原文查看)。
NeoRL-2数据集采用两种方式构建:多数环境使用中等性能的SAC策略(20%-75%分位)采集数据,DMSD环境则采用调参后的PID控制器(56%分位)。所有数据均由确定性策略生成,保持10万/2万的训练验证规模,但对Fusion等高成本环境缩减至2000/500条,真实模拟数据稀缺场景。
六、Experiments 实验
Comparing Methods
Baseline
专家策略:使用SAC算法对NeoRL-2中的每个环境进行在线策略优化,并保存得分最高的模型。需要强调的是,SAC获得的最高分策略代表了优秀的策略,但并不一定是最优解。在数据得分归一化处理(0-100分)中,专家策略提供的分数作为上限基准。
随机策略:通过均匀随机采样在每个环境的动作空间内生成动作。随机策略通常表现较差,常作为数据分数归一化(0-100)的最低基准线。
行为策略:此方法保留了SAC训练过程中产生的次优策略。现实中,大多数离线数据集不能达到最优策略性能,因此形成了离线数据集。若某些环境已具备最优策略,则无需使用强化学习进行优化。我们汇编了SAC训练期间保存的策略数据集,并记录了这些数据集中的轨迹平均回报值。需要注意,DMSD的数据集是通过PID策略收集的。
Model-Free Methods
为建立全面的基准,我们纳入了若干代表性算法用于离线策略改进。其中包括行为克隆(BC)方法,该方法通过监督学习从数据中复制策略。我们还实现了离线强化学习方法,如 CQL、EDAC、MCQ和 TD3BC。所有方法的实现可访问 https://github.com/polixir/OfflineRL 查看。
CQL。保守 Q 学习(CQL)方法通过特别惩罚分布外(OOD)数据点,防止对状态-动作价值函数 Q 的高估。通过获得一个保守的 Q 函数,CQL 在训练策略时最大化 Q 函数的同时,最小化当前 Q 值与数据中真实值之间的差异。这一方法应用于 SAC 框架内,有效缓解了 Q 值高估问题,从而形成更可靠的离线策略改进算法。
CQL(保守Q学习)
核心思想:通过惩罚分布外(OOD)数据来防止Q值高估
实现方式:在SAC框架内引入保守性约束
优势:有效缓解离线RL中的价值高估问题
EDAC。集成多样化行动者-评论家(EDAC)方法基于 SAC 算法,通过采用在线强化学习中常用的裁剪 Q 学习方法,有效惩罚 OOD 数据点。该方法通过选取 Q 值中的最小值来计算悲观估计。此外,EDAC 通过增加 Q 网络数量显著提升了算法效能,这一改进也被证明在多种行动者-评论家算法中具有益处。通过引入集成梯度多样化技术,EDAC 在保持甚至超越现有最先进(SOTA)算法效果的同时,有效减少了所需的 Q 网络数量。
EDAC(集成多样化行动者-评论家)
核心改进:基于SAC框架引入集成Q网络
关键技术:采用裁剪Q学习和梯度多样化
优势:在保持性能的同时减少所需Q网络数量
MCQ。温和保守 Q 学习(MCQ)方法旨在减少对 Q 函数的高估,特别是通过对 OOD 动作保持保守性。在添加 OOD 数据惩罚项时,该惩罚值的设定基于在构建的 Q 网络内为 OOD 数据分配适当分数,而非简单增加惩罚强度。实验结果表明,这种保守方法未在 Q 网络中显著引发高估,并取得了值得称赞的性能表现。
MCQ(温和保守Q学习)
创新点:为OOD数据设计自适应的保守惩罚
特点:避免过度惩罚导致的性能下降
效果:在保守性和性能间取得更好平衡
TD3BC。TD3BC 对现有强化学习算法进行了细微调整,却实现了显著的性能提升。该方法改进了双延迟深度确定性策略梯度(TD3)算法中的策略梯度部分。在目标函数设计上,通过从状态-动作价值函数结果中减去当前策略网络输出与数据集中动作之间的均方误差(MSE)。本质上,TD3BC 在标准 TD3 策略更新基础上增加了一个行为克隆(BC)正则化项,以促使策略更倾向于选择训练数据集中存在的动作。
TD3BC
基本思路:在TD3算法中加入行为克隆正则项
实现方式:用MSE约束策略输出接近数据集动作
优势:简单有效,适合数据分布较窄的场景
Model-Based Methods
基于模型的离线强化学习相较于无模型方法的优势包括更高的数据利用效率、更快的收敛速度以及出色的可解释性。通过利用离线数据进行环境模型训练,基于模型的方法能有效利用现有数据。我们采用了多种基于模型的强化学习方法,包括 MOPO、COMBO、RAMBO和 Mobile。这些方法从数据中构建动态模型,并利用该模型优化策略。
MOPO。基于模型的离线策略优化专注于解决基于模型强化学习中训练动态模型与真实环境间的分布偏移问题。为缓解此问题,在后续策略学习过程中,策略网络与模型交互获得的奖励会附加一个惩罚项,该惩罚项反映了模型与真实数据间的差异。这确保策略在选择动作时,会考虑与真实环境转移的偏离程度。通过使策略尽可能贴合数据中的转移动态,MOPO 旨在高效优化策略。
MOPO(基于模型的离线策略优化)
该方法通过引入模型预测误差作为奖励函数的惩罚项,有效解决了模型预测与真实环境之间的分布偏移问题。其核心创新在于利用预测不确定性来指导策略优化,使学习到的策略更加保守可靠。
COMBO。保守离线模型基策略优化(Conservative Offline Model-Based Policy Optimization)在 MOPO 基础上进一步解决了模型与真实数据间差异计算可能存在的误差问题,以及某些场景下性能不佳的缺陷。在价值网络训练过程中,COMBO 同时融合离线数据集和模型生成数据,并对生成的支持外状态-动作对引入额外正则化项。该方法无需直接测量生成数据与离线数据间的误差即可实现价值函数的保守估计,从而提升算法的鲁棒性和性能表现。
COMBO(保守离线模型基策略优化)
作为MOPO的改进版本,COMBO提出了双重保守机制:一方面在价值函数训练中同时使用真实数据和模型生成数据;另一方面对分布外状态-动作对施加正则化约束。这种方法在保持数据效率的同时,显著提升了算法的稳定性。
RAMBO。鲁棒对抗模型离线强化学习(Robust Adversarial Model-Based Offline RL)采用行为克隆(BC)方法构建动态模型。在此基础上,RAMBO 主要利用 SAC 算法框架执行基于模型的策略改进。值得注意的是,RAMBO 从结合了训练数据与模型生成轨迹数据的缓冲区中进行采样。在每次更新周期中,模型也会同步更新。通过采用最大似然估计来调整模型,RAMBO 能够影响损失函数的设计。这一方法确保了在策略训练过程中,模型能持续逼近训练数据中存在的环境状态转移。
RAMBO(鲁棒对抗模型离线强化学习)
RAMBO采用迭代式模型学习框架,将行为克隆与策略优化相结合。其独特之处在于维护一个混合缓冲区,同时包含真实轨迹和模型生成轨迹,通过最大似然估计持续优化动态模型,实现模型与策略的协同进化。
Mobile。为确保使用上的保守性,Mobile 采用模型贝尔曼不一致性作为衡量不确定性的指标,以评估生成数据与离线数据之间的差异。该指标允许对动态模型集合产生的贝尔曼估计的不一致性进行定量分析。在离线数据丰富的区域,贝尔曼估计通常表现出较小的误差和估计间的低差异;而在数据稀缺的区域,贝尔曼估计间存在更高的不一致性。Mobile 通过对贝尔曼估计一致性较差的动作施加更大惩罚,进一步确保策略在此类区域规避高风险动作。
Mobile(基于模型不确定性的离线学习)
Mobile提出了创新的模型贝尔曼不一致性指标,用于量化不同动态模型预测结果之间的差异。该方法根据不一致性程度自适应地调整惩罚强度,在数据丰富区域保持策略灵活性,在数据稀缺区域则实施严格约束。
Benchmarking Results
由于目前缺乏非常稳定且一致的离线策略评估方法[46, 12],本文仅进行在线策略评估。每种超参数配置均运行 3 个随机种子,并选取训练最终阶段的策略进行在线测试。本文报告 3 个种子中最佳超参数的结果,且所有算法使用的 3 个种子保持一致。
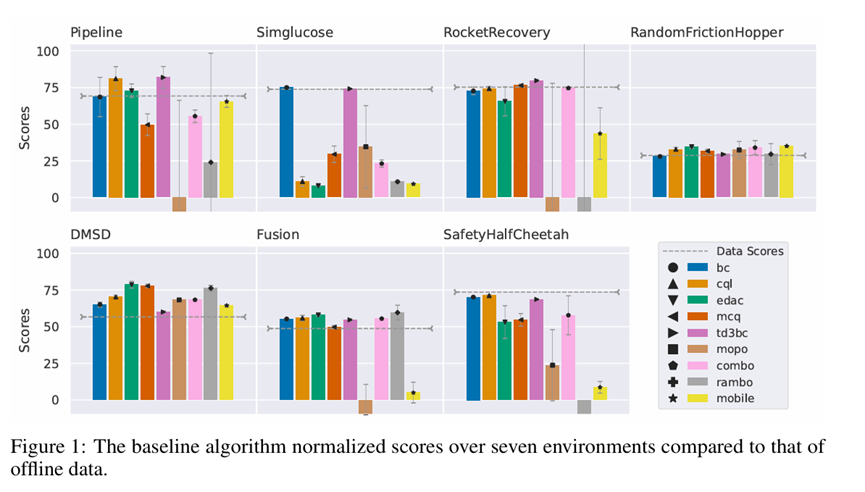
图 1 展示了基线算法获得的标准化分数,图例中不同颜色与符号代表不同基线算法。该可视化结果基于表 2 数据,直观呈现了当前算法中能产生最高平均分数的调优超参数性能。各算法在特定任务上的表现通过三个随机种子计算得出,其标准误差以误差条形式显示。从环境维度看,在 RandomFrictionHopper 和 DMSD 环境中,几乎所有基线算法的表现均优于离线数据中的分数。 基于模型的算法相较于无模型算法展现出较低的稳定性,这一点在 RocketRecovery、Fusion 和 SafetyHalfCheetah 任务中尤为明显,MOPO 与 RAMBO 算法显示出更大的误差范围。这凸显了 MOPO 和 RAMBO 算法在这些任务中对随机种子选择的高度敏感性,而其他算法则表现出较小的误差条,意味着更好的稳定性。就得分而言,没有任何算法在任何任务中超过 95 分1。TD3BC 算法在 Pipeline 任务中取得了 81.95 分的最高成绩,但仍未达到 95 分。因此,我们尚未发现任何能够成功解决 NeoRL-2 中任务的算法,且相较于数据集中的成绩,得分并无显著提升。
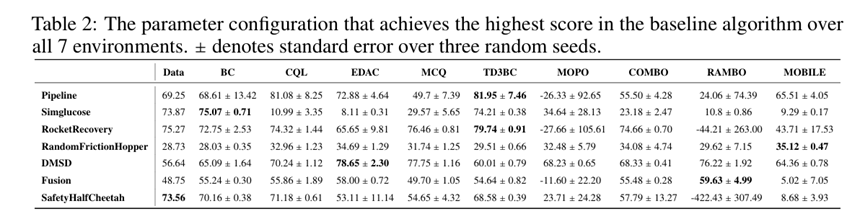
表 2 展示了 NeoRL-2 任务中所有基线算法在调整超参数后的最高得分,以及基于三个随机种子计算的标准误差。从表 2 可以明显看出,在 SafetyHalfCheetah 任务中,没有任何算法超过离线数据中的得分,其中 RAMBO 表现出极高的标准误差,意味着其性能极不稳定。得分提升最为显著的是 DMSD 任务,EDAC 算法的性能提升至 78.56 分,实现了约 22 分的进步。
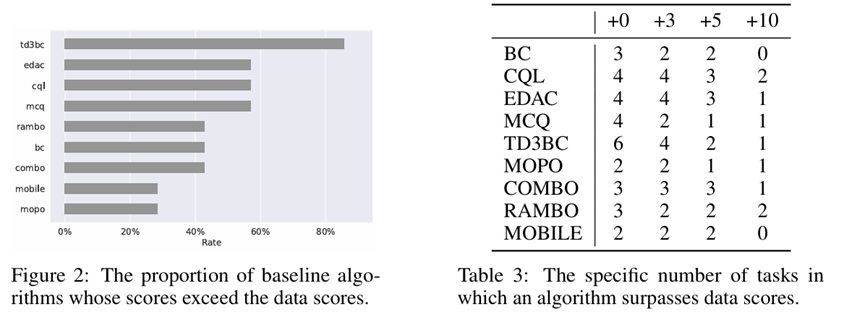
图 2 对比了七项任务中基线算法超越数据分数的比例。结果显示,TD3BC 算法在超过 80%的任务中实现了对数据分数的超越。此外,与基于模型的算法相比,无模型算法的成功率更高。值得一提的是,此处计算的比例基于表 2 的结果,即任何算法得分超过数据分数即视为成功改进。这种方法可能导致分数接近但改进不显著的情况。
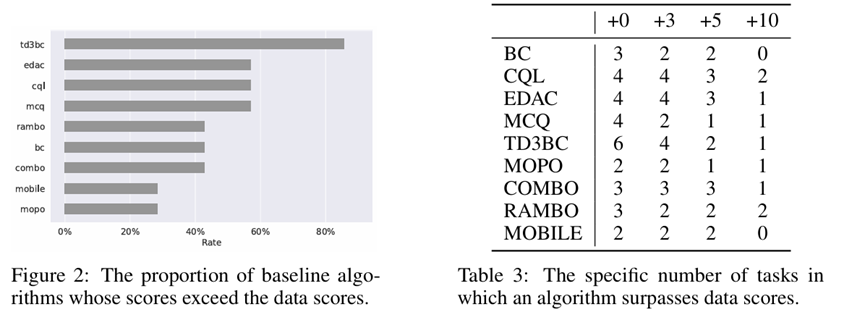
表 3 具体列出了各基线算法在数据中得分超越的次数。此处,+0、+3、+5 和+10 代表超越数据得分的阈值。例如,+10 意味着该算法得分超过数据得分 10 分以上。通过这些结果,我们能更直观地了解各算法的提升程度。结果显示,RAMBO 和 CQL 在七项任务中有两项实现了 10 分的提升。然而,没有算法能在超过半数的任务中达到 5 分的提升。这些发现表明,当前基线算法在 NeoRL-2 任务中并未显著提升性能。尽管某些任务可能有所改进,但我们尚未观察到有任何算法能在多数任务中实现 5 分的提升。这间接说明,在这些 SOTA 算法取得显著性能提升的任务中,任务本身相对简单。一旦这些任务被更接近现实世界的 NeoRL-2 任务替代,这些算法的表现便远不及其所宣称的水平。
七、Conclusion
离线强化学习(Offline RL)旨在从历史数据中学习,从而避免在现实环境中收集新数据的需求。为评估离线强化学习算法的有效性,已有多种基准测试套件被提出。然而,现有基准往往未能充分捕捉现实任务的关键特征。为此,我们推出了 NeoRL-2 基准套件,涵盖机器人、飞行器、工业管道、核聚变及医疗领域的任务。这些任务融入了延迟、外部因素和约束等特性,使 NeoRL-2 更能代表现实场景。我们采用确定性采样方法并限制样本数量,以符合实际任务设定。此外,在某些特定场景中,我们引入经典 PID 控制器作为数据采样手段。通过 NeoRL-2 测试了当前最优(SOTA)离线强化学习算法并分析结果。实验数据显示,在多数任务中,这些算法的表现并未显著超越用于数据收集的原始策略。 通过这项工作,我们旨在推动离线强化学习算法研究与实际应用的更紧密结合,促进强化学习在现实场景中的实际应用。
NeoRL-2 旨在为评估离线强化学习算法提供一系列易于使用的仿真环境,然而,当前离线 RL 算法的基准测试结果与实际性能之间仍存在差距。仿真环境尚无法完全复现现实世界任务的复杂性,尤其是当某些现实任务的转换机制不明确时。这也是离线 RL 领域普遍面临的挑战,我们相信 NeoRL-2 将推动未来基准任务与离线算法的共同发展。
离线强化学习旨在让AI"吃老本"——仅靠历史数据就能学有所成。但现有测试基准就像"温室考场",难以反映真实世界的风雨。为此,我们打造了NeoRL-2这个"训练场":
- 真实痛点全覆盖
囊括工业控制、医疗决策等7大现实场景 内置信号延迟、突发干扰、安全约束等"现实特效" 数据采集模拟真实条件:样本少、策略保守- 测试结果发人深省
当前顶尖算法在这里大多"水土不服",表现仅与传统的PID控制器相当。这说明: 实验室的漂亮指标≠实际应用能力 现实场景需要新一代更鲁棒的算法- 价值与展望
NeoRL-2就像一面照妖镜,让算法提前暴露在现实挑战前。虽然仿真永远无法完全复现真实世界的复杂性,但这个基准为学界指明了更具实践价值的研究方向——让强化学习真正走出实验室,走进工厂、医院等现实场景。
标准化得分达到 95 分可视为任务已解决。 ↩︎


















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











