






 文章详细介绍了Raft分布式一致性算法的Leader选举过程,包括初始选举、Failover和脑裂情况下的选举策略。此外,还讨论了日志复制机制,如何处理不一致的日志以及确保数据安全的方法,强调了term和index在决策中的关键作用。
文章详细介绍了Raft分布式一致性算法的Leader选举过程,包括初始选举、Failover和脑裂情况下的选举策略。此外,还讨论了日志复制机制,如何处理不一致的日志以及确保数据安全的方法,强调了term和index在决策中的关键作用。
Raft算法Leader选举、脑裂后选举、日志复制、修复不一致日志和数据安全
本文章中的集群默认为5个节点,请知悉。

1.Leader的选举和Failover过程
Follower
Follower是请求的被动更新者,从leader接收更新请求,将日志写入本地文件。
Candidate
Candidate:如果Follower在一定时间内,没有收到Leader的心跳,则判断Leader可能已经发生故障,此时启动Leader Election过程(即选举过程),本节点切换为Candidate,直到选主结束。
Leader
Leader:所有请求的处理者,接收客户端发起的操作请求,写入本地日志后,同步至其它Follower节点。
选举过程
Raft集群启动的时候,所有的节点都是Follower状态,等待选举超时时间超时,超时时间到达之前还没有收到 Leader节点的心跳,就会发起新一轮的leader选举过程,超时后该节点先将自己的term值加1 变为2,然后将自己的状态切换为Candidate状态(即候选人状态)。首先给自己投一票,然后再发起 request vote RPC请求 会向集群中的每个节点都发起拉票的请求,因为目前集群仅存在一个候选人,所以其他节点都会赞成票给该节点,其他节点会把自己的term 加1 与 Candidate节点的term值保持一致,Candidate节点收到赞成票后成为leader节点(赞成票超过半数可以成为leader节点且本节点投自己也算),该节点成为leader节点后,不断发出心跳给其他节点。
Failover过程
其他节点如果在超时时间没有收到leader节点的心跳信息就要开始新一轮的leader选举过程,先超时的节点会把自己的term 加1 首先给自己投一票,然后再发起 request vote RPC请求 会向集群中的每个节点都发起拉票的请求,此时只有三个节点可以向当前节点投票,原leader节点已无法连接,此时当前节点因为三票赞成及自己的一票共4票超过半数 一次该节点成为新的leader节点。
2.脑裂后选举
当一个raft集群存在5个节点,超时时间未能收到leader节点的心跳,新一轮的leader过程中两个节点的超时时间相同,且其余两个节点均给两个Candidate状态的节点投了赞成与反对票。例如 1节点为原leader节点 2,3节点超时时间相同且未收到leader心跳并给自己投了赞成票给对方投了反对票,4,5分别给2,3节点投了赞成与反对票。 此时 2,3节点均为 2票赞成 2票反对。出现脑裂现象。 后续需要等到4/5超时时间到达后,将自己的term值在之前的基础又加了1 ,并向其他的节点发送 request vote RPC请求,此时该节点的term值最大 2,3节点也会赞成票给该节点,因此该节点会成为leader节点。
3.日志复制
1,2节点为健康节点且1节点为leader节点,1节点向本地写入的3条日志,3条日志的写入硬盘还未向自己的状态机提交日志(状态机的状态为未提交状态),此时leader节点会向其他的 Follower节点复制日志,发起复制日志的请求,2节点会接收到请求并向本地写入日志给1节点应答 告知1节点已收到,然后1节点会继续发送日志,2节点获取完1节点的日之后 此时日志信息还是未提交的状态(半数的日志节点写入后leader节点会把日志状态修改为已提交),例如此时3节点恢复了并对1节点告知已收到,1节点会对3节点的日志进行日志检查,检查相同后1节点的第一条日志会变为已提交,1节点会继续向3节点进行复制日志且会携带一个让3节点将检查后日志节点改为已提交的状态,同时也会跟2节点发送更改日志状态的指令,3节点修改后接收到下一条日志也会继续跟1节点告知已收到重复上一个的过程。
4.修复不一致日志
1节点写入2轮日志之后宕机了,此时4节点恢复了就加入到了集群,这个时候会发起新一轮的leader选举,此时可能2节点先超时 变为 Candidate状态,最后成为leader节点。 新的leader节点首先要做的第一件事就是初始化所有的next index(即下一个索引地址),然后在做日志的一致性检查,如果日志不一致就向上一个日志处比对,如目前日志索引为3,先检查的第三个不一致,再去检查第二个,依次检查,若到最后发现都不一致直接将所有日志复制给该节点。类似上文说到的日志复制过程。
2,3,4节点写入第三轮日志时,这时候1节点恢复了那就需要leader节点进行日志的一致性检查,他要去检查日志的索引位置及日志是否一致,1节点日志比2节点日志多且index处的日志与2节点不一致,这个时候raft算法是根据leader节点的强一致性,leader节点会强烈的要求所有节点的日志保持一致,2节点会覆盖1节点索引4处的日志,以使得节点日志保持一致。这就是leader节点修改不一致节点日志的算法,总的来说是leader强一致性算法。

5.数据安全
2节点发送心跳后宕机了,此时5节点回复正常,且此时5节点已经加入了这个集群,所以就会触发新一轮的leader选举,5节点又恰好先超时,变为Candidate状态发起投票 发送了 request vote RPC请求进行拉票,其他节点发现term/index值要比该节点新的话拒绝给该节点投票,认为其不具备成为leader的资格,就是根据这个功能保证了数据的安全性。后续其他节点在超时未收到leader心跳后开启新的选举,且新节点成为leader后才会数据更新。
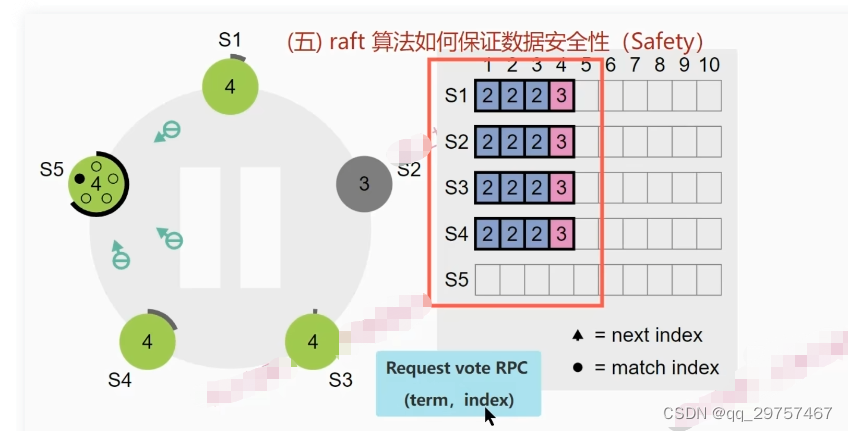
raft数据安全的规则
比较两个节点的term值以及日志的index值大小,来确定日志的新旧。 term不同时,term值大的成为leader,进行更新日志。 term值相等的话,index值大的进行日志更新。 term值优先级最高,term值相同时比较日志的index值。

















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









