






数据库和文件系统的关系
InnoDB和MyisAM都是将表存储在文件系统上
MySQL数据目录
数据的位置由系统变量datadir指定,查看方式如下
SHOW VARIABLES LIKE 'datadir';
数据库的目录结构
每一个数据库都对应着一个文件夹,每当新建一个数据库的时候,Mysql将做以下两件事
- 创建一个与数据库同名的文件夹
- 在该文件夹下创建一个db.opt文件,该文件包含了该数据库的各种属性
除了information_schema这个系统数据库之外,其他数据库在数据目录下都有子目录
每个表会在对应的数据库目录下创建一个同名的.idb文件,这个文件用于专门描述表结构
文件系统对数据库的影响
MySQL 的数据都是存在文件系统中的,就不得不受到文件系统的一些制约
- 数据库名称和表名称不得超过文件系统所允许的最大长度 每个数据库都对应 数据目录 的一个子目录,数据库名称就是这个子目录的名称;每个表都会在数据库子目录下产生一个和表名同名的 .idb文件
- 特殊字符的问题为了避免因为数据库名和表名出现某些特殊字符而造成文件系统不支持的情况, MySQL 会把数据库名和表名
中所有除数字和拉丁字母以外的所有字符在文件名里都映射成 @+编码值 的形式作为文件名。比方说我们创建的表的名称为 ‘test?’ ,由于 ? 不属于数字或者拉丁字母,所以会被映射成编码值,所以这个表对应的 .idb 文件的名称就变成了 test@003f.frm - 文件长度受文件系统最大长度限制它们的大小受限于文件系统支持的最大文件大小。
InnoDB表空间
表空间结构
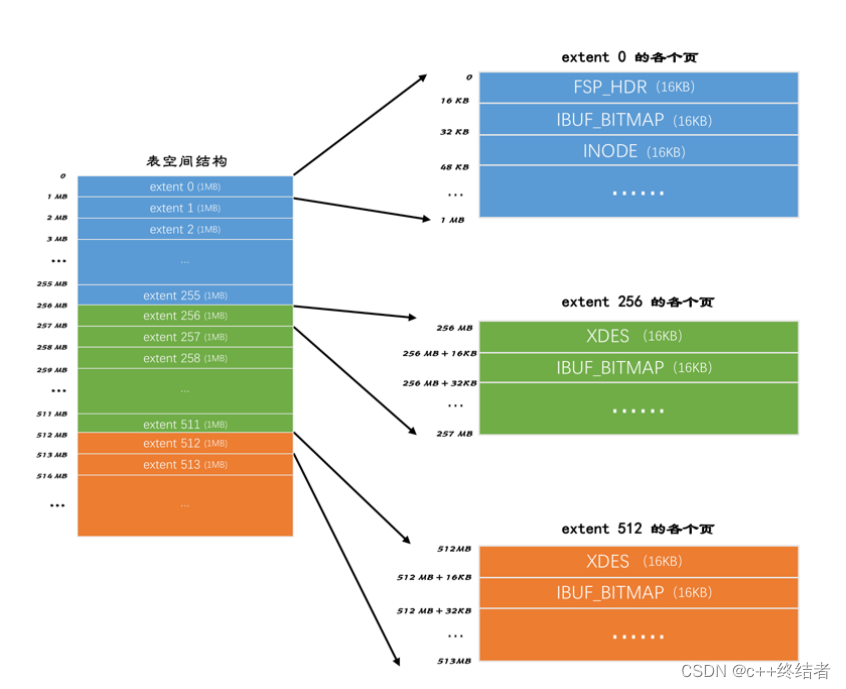
区的概念
目的:为了更好的管理页,Mysql将连续的64个页划分为区(每个区16KB*64 = 1MB),256个区被划分成一组(256MB),尽量让相邻的记录在物理上也是相邻的(减少随机访问,提高效率)
段的概念
为了提升范围查询的效率,InnoDB会尽量将叶子节点存储在相邻的区上(被称为段),非叶子节点和叶子节点(存放真实数据的节点)是分为两个段存储
如果每个段的大小最小是一个区的大小(1M),那么一个索引将最少占用2MB,为了解决这个问题,提出了碎片区的概念,碎片区中的页可以服务于多个段
综上默认策略如下
- 当低于32个页面的数据的时候,在碎片区以页面为单位分配存储空间
- 某个段占用了32个碎片区页面后,将会以完整的区来分配空间
区的分类
区可以分为如下几类
- 空闲的区:现在还没有用到这个区中的任何页面。
- 有剩余空间的碎片区:表示碎片区中还有可用的页面。
- 没有剩余空间的碎片区:表示碎片区中的所有页面都被使用,没有空闲页面。
- 附属于某个段的区。每一个索引都可以分为叶子节点段和非叶子节点段,除此之外InnoDB还会另外定义一些特殊作用的段,在这些段中的数据量很大时将使用区来作为基本的分配单位。
区的管理-XDES Entry结构
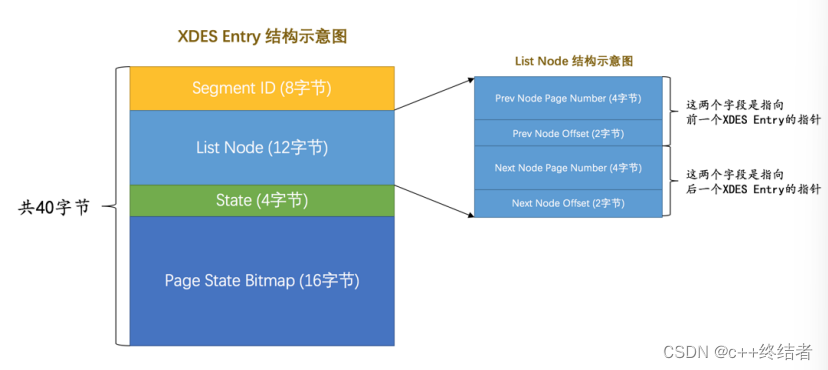
其中**Segment ID指示该Entry属于哪个段,**若不属于任何段则无作用,ListNode用于构成双向链表,State表示区的状态,分别是FREE(空闲区),FREE_FRAG(空闲的碎片区),FULL_FRAG(满的碎片区),FSEG(隶属于某个段的区),Page State Bitmap指示区中的页的使用情况
段中的三个链表
Free 链表: 未使用的区组成的链表
Free_Frag链表:未使用完全的碎片区的链表
Full_Frag链表:使用完全(没有空闲)的碎片区链表
用如下的结构体表示

其实就是上文XDES Entry中的ListNode加上一个表示链表长度的字段
段的结构
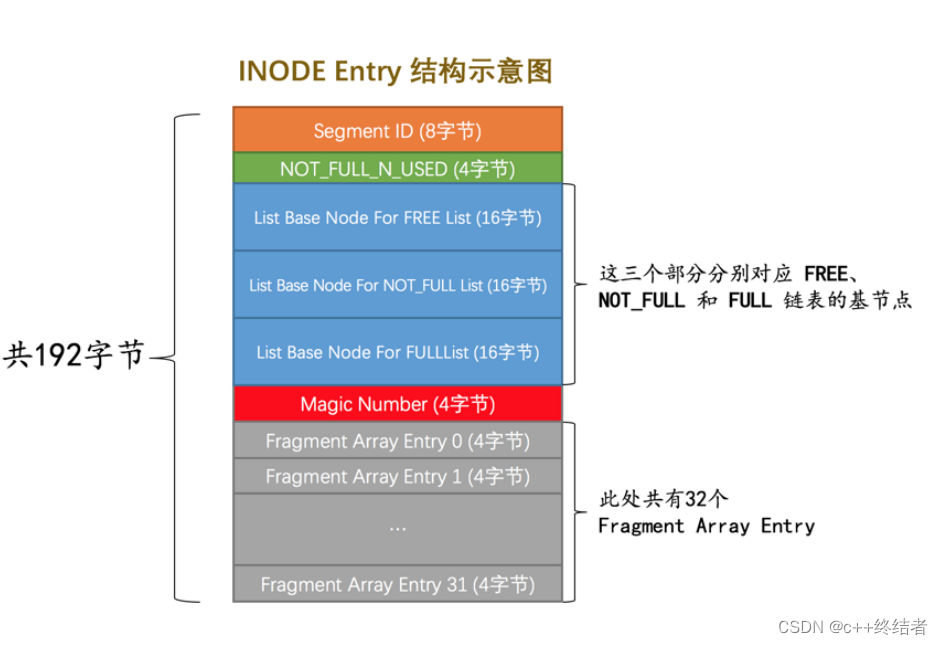
SegmentID:段编号.NOT_FULL_N_USED:指示非满的碎片区的页面使用量,下次的插入直接寻找这个就好了
MagicNumber指示该Inode是否被初始化了
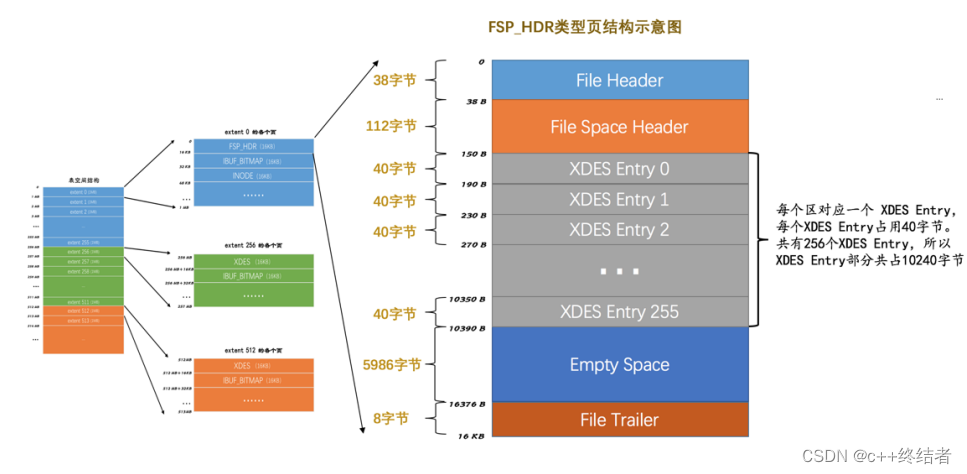
各类型页面的详细情况
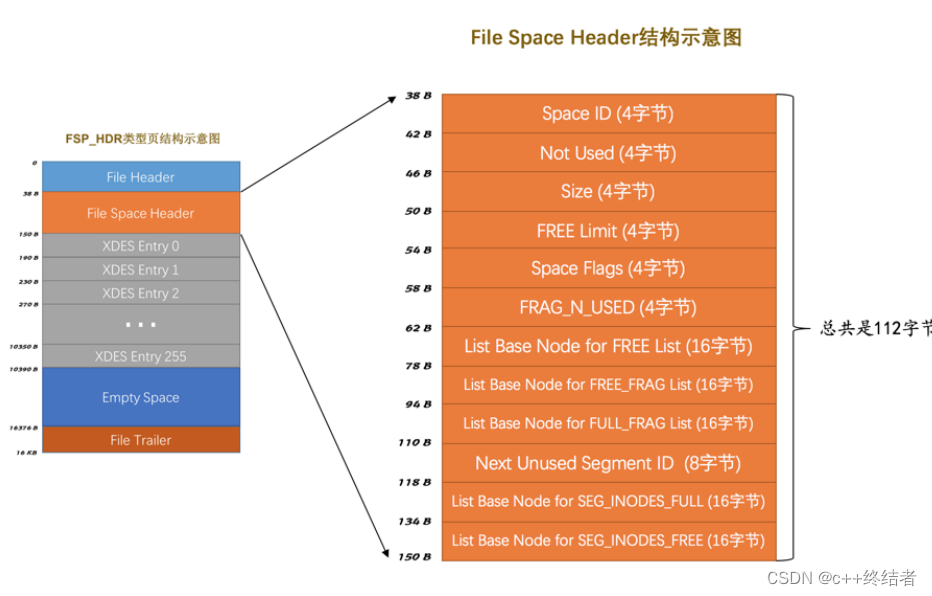
FSP_HDR类型















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









