







一. 简单命令示例
- Zset有序集合,向集合中添加元素时,可以带一个分数
//1.添加元素和该元素的分数
ZADD key score member[score member...]
//2.按照元素分数大小顺序返回索引从start到stop之间的所有元素
ZRANGE key start stop[WITHSCORES]
//3.获取元素分数
ZSCORE key member
//4.删除元素
ZREM key member[member...]
//5.获取给定分数范围的元素
ZRANGEBYSCORE key min max[WITHSCORES][LIMIT offest count]
//6.增加某个元素的分数
ZINCRBY key increment member
//7.获取集合中元素数量
ZCARD key
//8.获取分数范围内的元素个数
ZCOUNT key min max
//9.按照排名范围删除元素
ZREMRANGEBYRANK key start stop
//10.获取元素的排名
ZRANK key member //从小到大
ZREVEANK key member //从大到小
二. java 操作示例
- 操作 SortedSet 有序集合,不允许重复的成员,每个元素都会关联一个double类型的分数,通过分数来为集合中的成员进行从小到大的排序,zset的成员是唯一的,但分数(score)却可以重复
@Test
public void testSortedSet() {
//1.创建操作sorted set数据的对象
ZSetOperations<String, String> zSetOperations = stringRedisTemplate.opsForZSet();
//2.向redis中添加 sorted set 类型数据,需要将数据封装到 ZSetOperations 中
//传递一个dubbo值指定该数据在sortedSet集合中的排序位置,
ZSetOperations.TypedTuple<String> objectTypedTuple1 = new DefaultTypedTuple<String>("zhangsan", 99D);
ZSetOperations.TypedTuple<String> objectTypedTuple2 = new DefaultTypedTuple<String>("lisi", 96D);
ZSetOperations.TypedTuple<String> objectTypedTuple3 = new DefaultTypedTuple<String>("wangwu", 92D);
ZSetOperations.TypedTuple<String> objectTypedTuple4 = new DefaultTypedTuple<String>("zhaoliu", 100D);
ZSetOperations.TypedTuple<String> objectTypedTuple5 = new DefaultTypedTuple<String>("tianqi", 95D);
Set<ZSetOperations.TypedTuple<String>> tuples = new HashSet<ZSetOperations.TypedTuple<String>>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
tuples.add(objectTypedTuple3);
tuples.add(objectTypedTuple4);
tuples.add(objectTypedTuple5);
//添加数据
zSetOperations.add("score", tuples);
//获取多条数据,左闭右闭,返回Set集合
Set<String> scores = zSetOperations.range("score", 0, 4);
//获取长度
Long total = zSetOperations.size("score");
//删除redis的key为score,value值为 zhangsan和lisi的两个数据
zSetOperations.remove("score", "zhangsan", "lisi");
}
三. 使用场景
- 商品销售排行榜使用Zset, key为"商品排行榜:", 分数为销售数量, value值为商品编号
//1.商品编号为0001销量为9, 商品编号为1002销量为20
zadd goods 9 0001 20 1002
//2.客户又买了2见编号为0001的商品
zincrby goods 2 0001
//3.获取前10名热门商品
zrange goods 0 10 withscores
高并发下使用Zset做统计分页显示(热评榜)
- 思考为什么不用list类型
- list在插入时会将数据push到集合的头部,假设第一次看第一页显示a,b,c,在看刷新到第二页的瞬间又插入了一条新评论,这时候第二页就会显示c,d,e,f会发现第一页,第二页一共显示了两次c
- zset 以时间作为分数插入, 使用 ZRANGE,ZREVRANGE 或 ZRANGEBYSCORE LIMIT 按照分数查询limt分页

四. 底层分析
- 首先确认redis中zset有两种编码格式: skliplist跳跃表 跟ziplist压缩表
- 执行"config get zset* " 命令查看
“zset-max-ziplist-entries” 默认128
“zset-max-ziplist-value” 默认64
- 在存储zset类型时,当有序集合中包含的元素个数小于等于"zset-max-ziplist-entries", 集合中member长度小于等于"zset-max-ziplist-value",使用skliplist跳跃表格式进行编码,如果两个条件中有一个不满足则会使用ziplist作为底层编码格式
- 查看与修改"zset-max-ziplist-entries" "zset-max-ziplist-value"示例

- 存储zset类型数据,查看编码格式示例(此时zset-max-ziplist-entries已经修改为3, zset-max-ziplist-value修改为6)

skiplist 跳跃表
- 先解释一下普通链表中存在的问题: 假设在链表中查找一个数据是时间复杂度是O(N),要一次遍历到指定位置
- 解释什么是跳跃表: skiplist 跳表可以理解为通过空间换取时间的一种数据结构,为了加速查找,跳跃表中包含多层索引,每一层都是一个链表,其中每个节点都是下一层节点的前缀,每一层的节点数量基于一个随机概率 strategically 保留;通常是保留 1/2 或 1/4 的节点,最底层链表包含所有的节点.是一个可以实现二分查找的有序链表,可以理解为借鉴数据库索引思想,提取出链表中关键节点作为索引,多个索引形成上级一个上级链表,提取多层关键节点,也就是多个链表,以关键节点为入口进行查找,其底层是通过"链表+多级索引"实现最终形成跳表结构
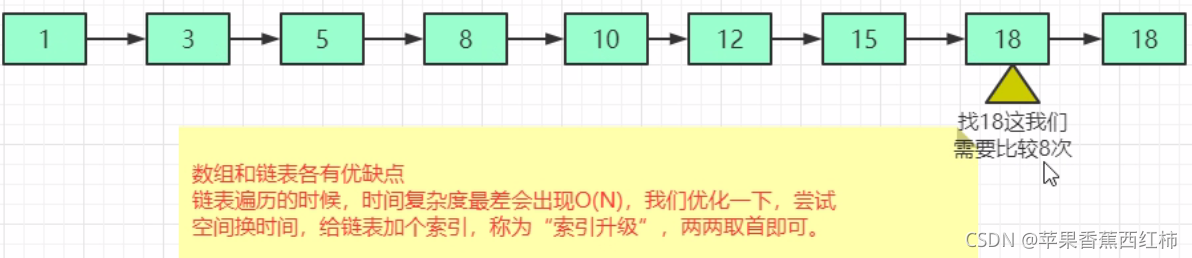
- 那么有序链表是怎么加索引的呢: 每两个节点中的第一个节点提取为索引升纬,上层节点个数是下层节点个数的1/2,最上层两个节点,如果现在再去查找18这个元素的话,首先定位到第一层,比较第一个节点为1,小于查询数据,查找1后面的,进入到第二层(1,10,20),定位到10,比较后找10右边的,定位到第三层(1,5,10,15,20),定位到15,比较后定位右边,找到18,只需要查找4次

- 根据上图总结跳表的时间复杂度

- 跳表的空间复杂度

- 跳表的优缺点: 查询快,跳表是一个典型的空间换时间解决方案,只有在数据较大并且读多,写少的情况下才能体现出优势,所以适用范围有限,新增或删除要把索引重新都更新一遍成本较高,新增删除更新过程中时间复杂度为O(log n)















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









