







目录
一. MySQL 的成本计算
- mysql在查询数据时考虑比较重要的两个成本: io成本与cup成本
- 将数据由磁盘加载到内存的过程称为io成本,读取一页的数据到内存io成本为1.0
- 数据加载到内存后,mysql在内存对数据的读取,解析,计算过滤,排序等相关处理称为cup成本,当通过内存检测一次数据满足执行sql的条件cpu成本为0.2
- 全表扫描时的执行过程: 实际就是将聚簇索引加载到内存(也就是实际数据),然后检查是否满足条件,然后将满足过滤条件的数据加入到结果集, 那么全表扫描时mysql所需要的io成本, cup成本怎么计算
- io成本: 聚簇索引占用页数1.0+1.1(微调数), cpu成本: 数据条数0.2+1.0(微调数)
2.mysql中提供了专门的命令查看表的统计信息: 查看所有表"show table status;" 查看指定表"show table status like ‘表名’ ", 返回数据中rows表示数据行数(估计值), Data_length表示当前表数据占用的字节数, 聚簇索引一页16k, Data_length/16/1024获取到当前数据占用的页数
- 通过explain 查看执行成本
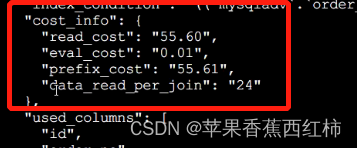
“explain format=json 实际执行的sql语句” 该方式比普通explain会多返回一些数据,其中query_cost的值就是执行当前sql所需要io成本+cpu成本,继续寻找会发现一个const_info内部保存了详细的执行成本
二. 执行优化相关
配置开启"优化追踪命令"
- mysql在5.6版本后提供了"优化追踪命令",可以更直观的看到mysql优化后执行的sql, 但是需要配置开启
- "show variables like ‘optimizer_trace’ " : 查看mysql是否开启优化追踪
- "set optimizer_trace=“enabled=on” ": 开启优化追踪
- 执行实际的业务sql, 当业务sql执行完毕后,mysql会将该sql的分析结果存储到一张系统表中,其中就包括优化步骤
- “select * from information_schema.optimizer_trace” 查看mysql对业务sql执行计划分析的全过程,返回数据解释:
QUERY: 实际执行的sql
TRACE: 整个执行计划优化分析生成的json文本, 在TRACE中包含执行sql时的三个阶段: “join_preparation 准备阶段”, “join_optimization 优化阶段”, “join_execution 执行阶段”
其中重点关注TRACE下的"join_optimization 优化阶段"
MySQL 执行优化器的优化步骤
- mysql在执行前会通过执行计划计算执行成本,选择一个性能最优的路径执行,这也就是执行优化器优化的步骤
- 根据搜索条件,找出所有可能使用的索引
- 计算全表扫描的执行成本
- 计算通过不同索引执行的执行成本
- 对比各种执行方案,选择最优执行路径.
- 通过TRACE下的"join_optimization 优化阶段",了解到优化阶段通常经过一些几个步骤
- 第一步: condition_processing: 处理搜索条件, 可以简单理解为处理where后的一系列条件
- 第二步: substitute_generated_columns: 替换虚拟生成列,注意该步骤是5.7以后出现的新特性
- 第三步: table_dependencies: 分析表的依赖信息
- 第四步:重点 rows_estimation: 分析业务sql的不同执行路径,执行成本, 选择最优路径
1. condition_processing 处理搜索条件优化阶段
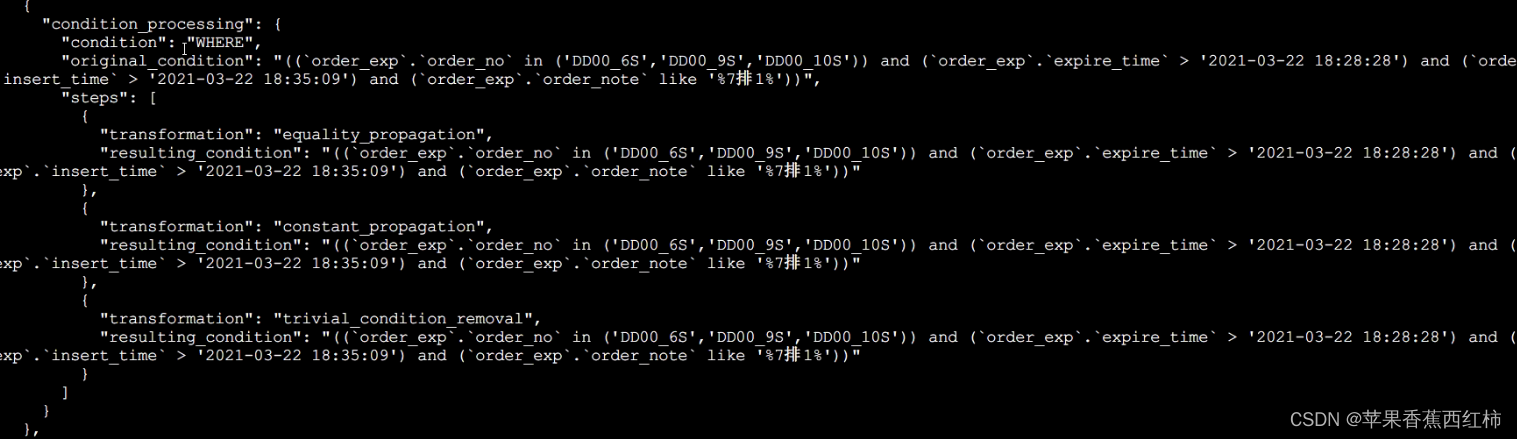
- condition_processing: 处理搜索条件, 下的详细步骤解释: (condition_processing下存在"original_condition"该key中记录了执行的业务sql,where后的原始条件, 对于原始条件mysql会进行一定的优化,通常情况下可能出现以下几个步骤)
- equality_propagation等值传递转换: 例如"where a=1+5" 经过该步骤后会优化为"where a=6"
- constant_propagation常量传递转换:
- trivial_condition_removal去除没用的条件: 例如 “where 1=1” 永远为true, 经过mysql分析后可能就把这个条件给去掉了
2. rows_estimation 分析业务SQL优化阶段
- rows_estimation: 分析业务sql的不同执行路径,执行成本,选择最优路径
- 第一步: table_scan分析全表扫描,记录如果业务sql通过全部扫描方式查询数据时,需要扫描的行数rows, 消耗的总成本cost
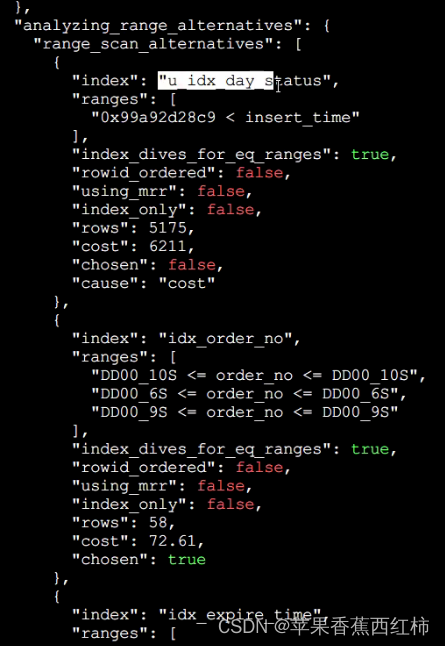
- 第二步: potential_range_indexes分析sql能否命中索引,获取到能够命中的索引,内部又细分为主键索引, 普通索引,联合索引,如果命中索引index下存储的是命中的索引名,usable返回true,
- 第三步: range_alternatives 上一步骤拿到了能够命中的索引,当前步骤针对每个能够命中的索引,分析业务sql如果使用该索引获取数据时需要扫描的行数,消耗的总成本,能否使用index_dive索引精确模式扫描数据,mrr访问磁盘时能否顺序访问(不使用随机访问),其中"chosen"中保存了实际有没有实际该索引,false表示没有使用,"cause"中保存了没有使用的原因,如果存储了"cost"表示成本原因所以没采用
- 第四步: analyzing_roworder_intersect 分析是否使用了索引合并,usable为false表示没有,cause中存储了没有使用的原因
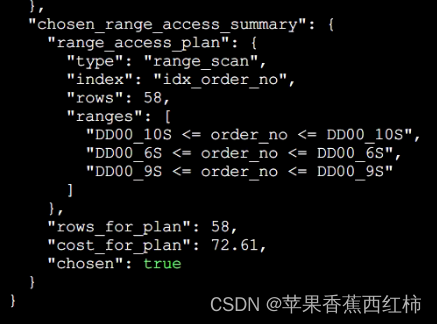
- 第五步: chosen_range_access_summary针对以上索引分析进行统计汇总: 上一步骤中对所有能够命中的索引分析了一遍,当前步骤会选择一个最优的,"index"中存储了应该使用哪个索引, "type"扫描类型,"rows"影响的函数, "ranges"扫描范围,"rows_for_plan"扫描行数,"cost_for_plan"消耗总成本,"chosen"是否选择该索引,true选择
- 第六步: considered_execution_plans 选择执行计划,如果是多表连接查询,该步骤会对多表连接的组合成本进行分析计算
- 第七步: attaching_conditions_to_tables 尝试给执行的业务sql添加其它执行条件,判断是否能使用ICP,也就是索引下推
- 第八步: refine_plan 最终完善优化
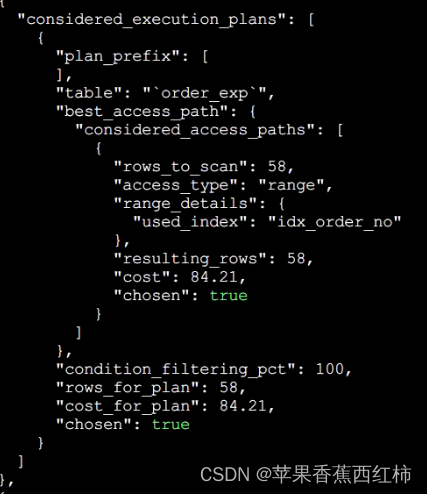


- 以上的分析可以理解为都只针对单表的
- 连表查询的成本计算是单次查询驱动表+多次查询被驱动表成本的和















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









