







 本文介绍了CUDA编程的基础,包括GPU的硬件结构从CPU演化的历程,异构计算的概念,以及在CUDA中线程的层次结构,如线程、线程块和线程网格。文章详细阐述了线程的执行流程,如何通过线程索引确定执行数据,并通过实例展示了如何合理分配线程块和网格大小。此外,还提到了GPU的参数限制,如每个Block的最大线程数和线程束的概念。
本文介绍了CUDA编程的基础,包括GPU的硬件结构从CPU演化的历程,异构计算的概念,以及在CUDA中线程的层次结构,如线程、线程块和线程网格。文章详细阐述了线程的执行流程,如何通过线程索引确定执行数据,并通过实例展示了如何合理分配线程块和网格大小。此外,还提到了GPU的参数限制,如每个Block的最大线程数和线程束的概念。
一、预备知识
学习前准备:本文中的编译环境为:win11 + Microsoft Visual Studio 2022 + CUDA 11.7
相关准备工作可参考:https://blog.csdn.net/ashiners/article/details/128201406
1.硬件结构
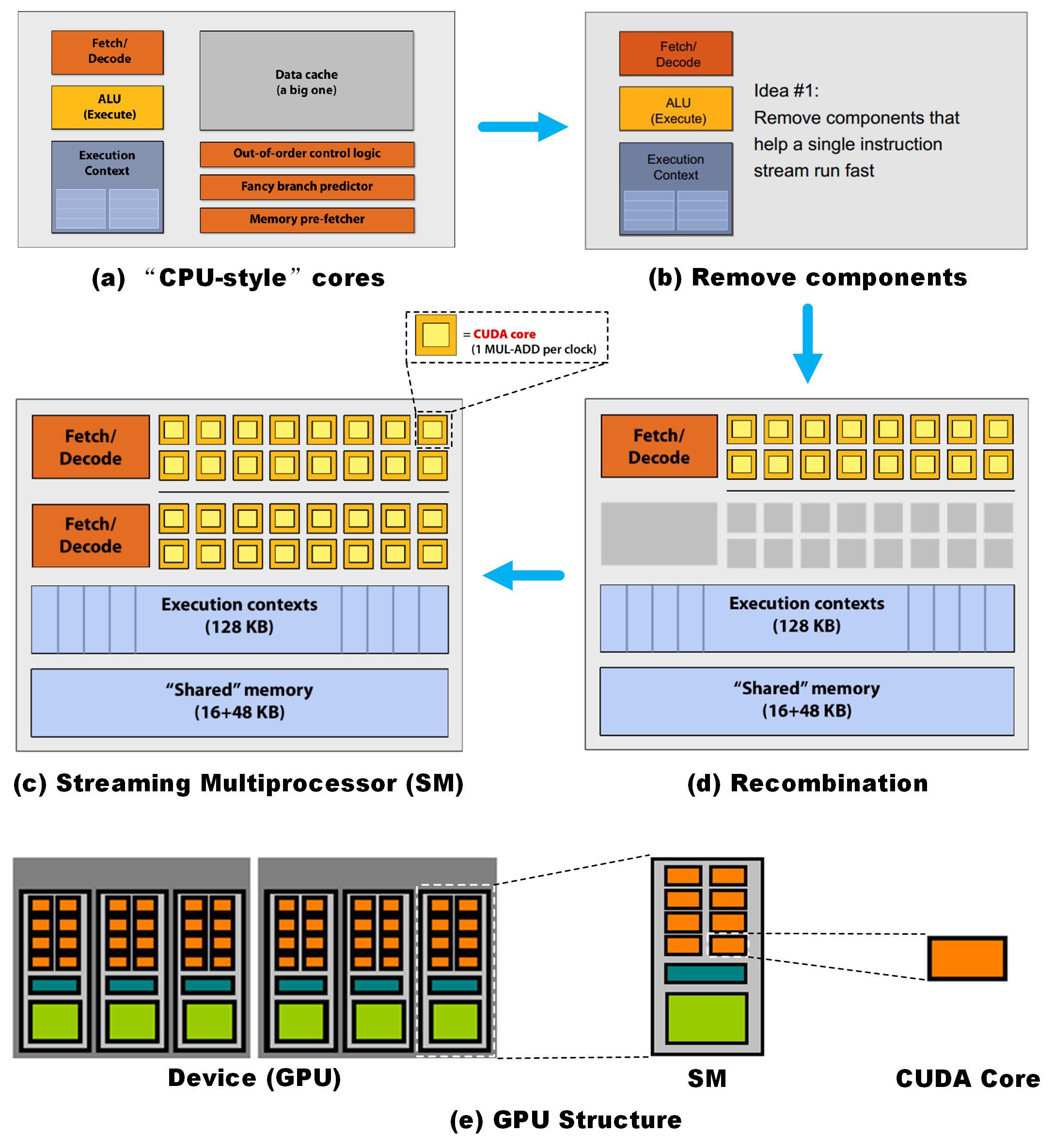
图1. 从CPU演化到GPU过程
如图1(a)所示,CPU需要有指令解码单元、计算执行单元、执行上下文单元、缓存、乱序控制逻辑、分支预测和断定以及存储单元获取等。若只留下核心计算的部分如图1(b),对这一部分进一步重组增加ALU加入一部分共享内存即为图1(d)。为了再提高单元的计算能力,再次加入一组计算单元如图1(c),则变成早期的GPU架构。最小的计算单元为CUDA核,图1(c)为一个流多处理器。如图1(e)所示GPU主要由多个SM构成,GPU中还有L2缓存和内存控制器等,这里不过多讨论。
2.首先要了解的一点是什么是异构计算,为什么要用异构计算?
计算机系统一般都配置了CPU 和GPU,GPU传统上只负责图形渲染,大部分的任务都由CPU 来完成。随着图形渲染的数据量越来越大、计算也越来越复杂,GPU的可编程性和并行性也随之增强。 目前,主流GPU 的计算能力、存储带宽、性价比与同期的CPU相比更具竞争力。
异构计算主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。如图2所示,通常来说把计算比较占用时间的一些代码在GPU运行,在CPU中主要运行逻辑控制代码,减少CPU的运算,可以同时发挥出CPU和GPU两个设备的优势。

图2. 异构计算示意图
应用程序的一部分可以并行计算的代码通过kernelfunction形式在GPU 完成运算,剩下的顺序执行代码由CPU完成运行。
二、线程层次
1.线程层次理解
在GPU的CUDA编程语言模型中重要的术语:
Host 通常指的是主机设备,即CPU和内存(hostmemory)
Device 通常指的是GPU设备,即GPU和显存(device memory)

图3.线程层次示意图
从下向上看,图3中最下方的红色方格代表一个线程(Thread)为执行指令运算的最小单位,线程块(Thread Block)可以包含多个线程,在图3中包含了一个二维的3行5列线程,即15个线程。再向上看,线程块被包含于线程网格(Thread Grid)中,图3中黄色部分代表一个线程网格包含了一个二维的2行3列线程块。
他们的层级关系可以按照ken老师讲的比喻来理解,Thread相当于个人,Thread Block表示班级,Thread Grid 表示年级。

图4. 线程层次与GPU硬件对应关系
如图4所示,线程在CUDA核中执行;线程块在流多处理器(SM)中执行;一个kernel 以一个线程块网格的形式启动。
以下是每个层级解释和特点:
Thread: sequential execution unit
所有线程执行相同的核核函数
并行执行
Thread Block: a group of threads
执行在一个Streaming Multiprocessor (SM)中
同一个Block中的线程可以写作
Thread Grid: a collection of thread blocks
一个Grid当中的Block可以在多个SM中执行
结合代码来看(代码一)
#include <stdio.h>
__global__ void hello_from_gpu()
{
printf("Hello World from the GPU!\n");
}
int main(void)
{
hello_from_gpu<<<2, 4>>>();
cudaDeviceSynchronize();
return 0;
}hello_from_gpu中后面<<<2, 4>>>分别对应的<<<grid_size, block_size>>>。grid_size代表申请多少个block; block_size代表每个block申请多少个线程。grid_size和block_size这两个值保存在两个内建变量(build-in variable)中。在案例中申请了2个block,每个block申请了4个线程。因为每个线程都会执行hello_from_gpu功能块,所以会有打印8次Hello World from the GPU!
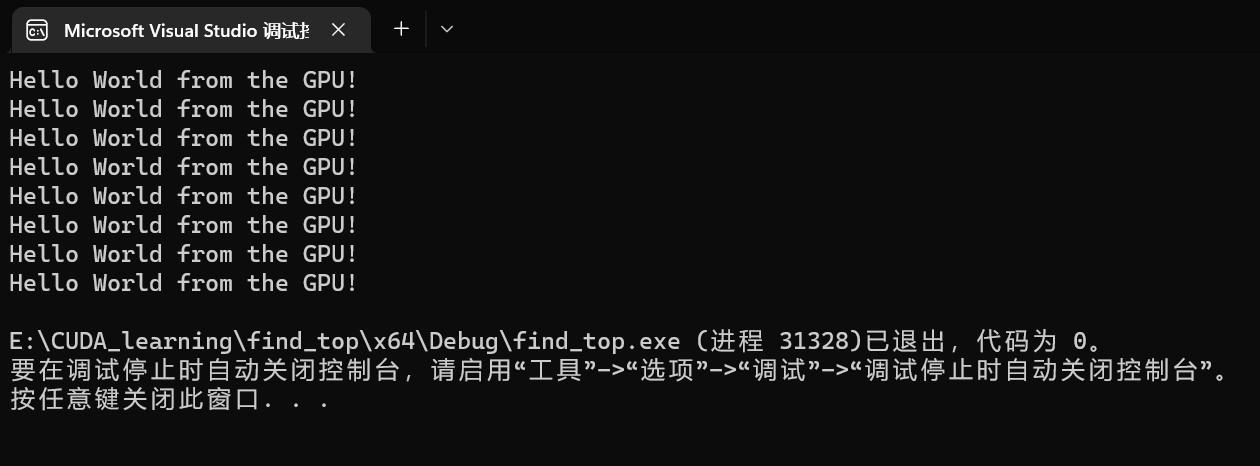
图5. 代码一执行后的结果
在执行配置参数中使用gridDim.x 、blockDim.x来表示线程层次相关维度,后续可以用来计算线程的起始位置。gridDim和blockDim是类型为dim3的结构体类型变量,具有x、y、z这三个成员。
gridDim.x: 该变量的数值等于执行配置中变量grid_size的数值。
blockDim.x: 该变量的数值等于执行配置中变量block_size的数值。
我们在来个例子(代码二)
#include <stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("Hello World from block %d and thread %d!\n", bid, tid);
}
int main(void)
{
hello_from_gpu<<<2, 4>>>();
cudaDeviceSynchronize();
return 0;
}
相应的如果想设置对应线程,则通过相应的ID来进行设置查找。
blockIdx.x : 该变量指定一个线程在一个网络中的线程块指标,其取值范围是从0~ gridDim.x -1;
threadIdx.x : 该变量指定一个线程在一个线程块中的线程块指标,其取值范围是从0~ blockDim.x -1;
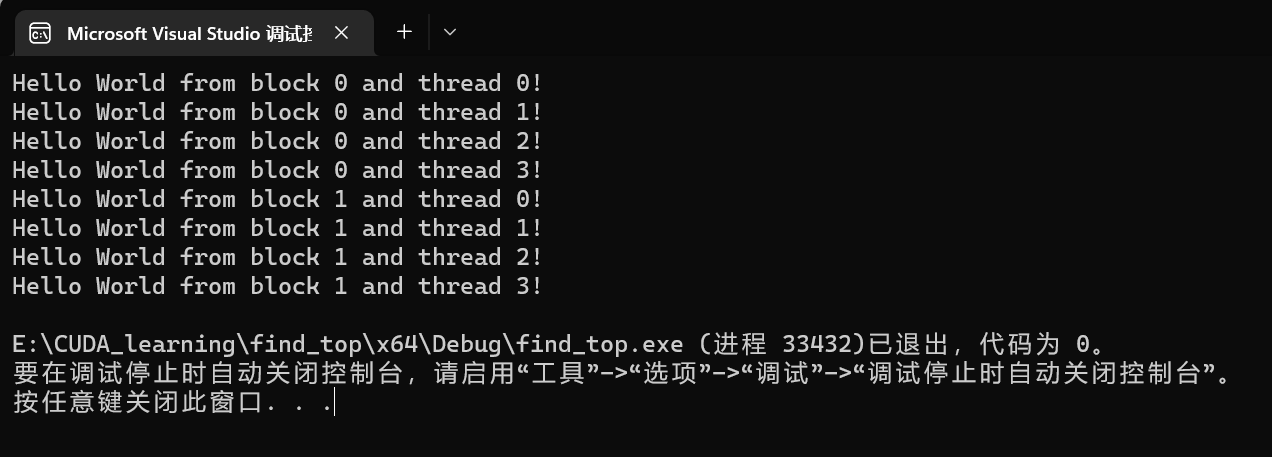
图6. 代码二执行后的结果
在线程分配中,可以是一维、二维甚至三维。但是如何合理利用分配线程,则引入了类型为uint3的threadIdx和blockIdx这两个变量。uint3是一个结构体类型,具有x、y、z这三个成员。
threadIdx.[x y z]:是执行当前kernel函数的线程在block中的索引值。
blockIdx.[x y z ]:是执行当前kernel函数所在的block,在grid中的索引值。
blockDim.[x y z]:表示一个block中包含多少个线程。
gridDim.[x y z]:表示一个grid中包含多少个block。
2. CUDA的执行流程
加载核函数。
将Grid分配一个Device。
根据<<<. .>>>内的执行设置的第一个参数, Giga threads engine将block分配到SM中。一个Block内的线程一定会在同一个SM内,一个SM可以有很多个Block。
根据<<<. .>>>内的执行设置的第二个参数,Warp调度器会将调用线程。
Warp调度器为了提高运行效率,会将每32个线程分为一组,称作一个Warp。
每个Warp会被分配到32个core上运行。
三、线程索引
如何确定线程的执行数据?
这时就需要用到前面提到的线程空间索引了,即threadIdx、blockIdx、blockDim和gridDim了。

图7. 寻找线程索引示意图
如图7(a)所示,如果没有线程索引的情况下,需要通过计数方式才能找到线程对应位置。如图7(b)所示,通过线程空间索引可以快速定位线程位置。如果对线程进行分块,则管理更加灵活。下面我们研究如何寻找指定线程。

图8. 线程索引计算过程
如图7(b) 所示,图中有4个block(分别由四种颜色表示),每个block中有8个线程(分别由相同颜色不同数字表示)。那么因为每个block中有8个线程,所以blockDim.x = 8;红色方块线程对应的block索引是2,所以blockIdx.x = 2;红色线程在索引为2的block中,线程的索引为5,因此threadIdx.x = 5; 最后得到红色线程最后的索引index = threadIdx.x + blockIdx.x * blockDim.x = 5 + 2 * 8 = 21。我们发现和7(a) 的索引是一致的。
下面我们看个加法的例子(代码三):
#include <math.h>
#include <stdio.h>
void __global__ add(const double *x, const double *y, double *z, int count)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if( n < count)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
error = true;
}
}
printf("%s\n", error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 1000;
const int M = sizeof(double) * N;
double *h_x = (double*) malloc(M);
double *h_y = (double*) malloc(M);
double *h_z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1;
h_y[n] = 2;
}
double *d_x, *d_y, *d_z;
cudaMalloc((void **)&d_x, M);
cudaMalloc((void **)&d_y, M);
cudaMalloc((void **)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
const int block_size = 128;
const int grid_size = (N + block_size - 1) / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
check(h_z, N);
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}执行的结果:

图9. 代码三执行后的结果
2.如何合理分配CUDA Kernel 中的Gird size 和Block size?
课中何老师讲述grid size 和 block size 并没有非常固定最好的值,需要根据实际的情况出发。
在一维的情况下以代码三为例,block_size 初步设定为 128;若将所有数据尽可能被分配到线程上,又不浪费过多线程可以尝试将grid_size = ( N + block_size - 1 )/block_size,这样grid_size刚好满足矩阵N的需求,可能刚好也可能比N稍微大一点点。
3. 每个Block 可以申请多少个线程?
查看GPU各项参数可以用Nvidia 提供官方demo程序deviceQuery.exe

图10. GPU 参数
在图10的 每一个block 最大线程个数(Maximum number of threads per block): 1024,Max dimension size of thread block (x, y, z): (1024, 1024, 64),虽然上述x , y, z三个维度分别为1024,1024,64是参数可以填入的最大数值,但是实际需要遵循三个维度的乘积x * y * z<=1024。
4. CUDA如何分配线程?
一个线程块中的线程还可以细分为不同的线程束(thread warp)。一个线程束就是连续的32个线程。具体地说,一个线程块中第0~31个线程属于第0个线程束,第32~63个线程属于第1个线程束,以此类推。如图11所示。

图11. 线程分配示意图
如图11所示,如果是blockDim为160 是32的整数倍,则刚好可以分配5个warp;若blockDim为161,则在5个warp的基础上多加1个warp,第6个warp只包含1个线程。
四、参考文献与链接
最后特此感谢NVIDIA 的老师们,辛苦了。特此感谢何琨老师、樊哲勇老师和不知道名字的GPUS Lady以及其他老师们。
此文章作为个人学习记录,若有问题欢迎各位读者指出。非常感谢~
















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











