






The Extent and Consequences of P-Hacking in Science

Abstract
关注新的、确证性的和统计学显著性的结果会导致科学文献中存在大量偏倚。一种被称为“p-黑客”的偏见发生在研究人员收集或选择数据或统计分析,直到不重要的结果变得重要。在这里,我们使用文本挖掘来证明p-hacking在整个科学领域都很普遍。然后,我们说明了如何可以测试p-黑客时,进行荟萃分析,并表明,虽然p-黑客可能是常见的,其效果似乎是弱相对于正在测量的真实的效果大小。这一结果表明,p-hacking可能不会彻底改变从荟萃分析中得出的科学共识。
Introduction
人们越来越担心许多已发表的结果是假阳性[1,2](但请参见[3])。许多人认为,目前的科学实践创造了强烈的激励,以发表统计上显著的(即,有充分的证据表明,期刊,特别是具有较高影响因子的知名期刊,不成比例地发表统计学上显著的结果[4-10]。雇主和资助者经常计算论文,并通过期刊的影响因子来衡量它们,以评估研究人员的表现[11]。这些因素结合在一起,促使研究人员有选择地追求和有选择地试图发表具有统计意义的研究成果。
有两种类型的研究人员驱动的出版偏见被广泛认可:选择(也被称为“文件抽屉效应”,其中研究结果不显著的出版率较低[7])和通货膨胀[12]。通货膨胀偏差,也称为“p-黑客”或“选择性报告”,是在已发表的研究中对真实效应量的错误报告(框1)。当研究人员尝试几种统计分析和/或数据资格规范,然后选择性地报告那些产生显著结果时,就会发生这种情况[12-15]。导致p-hacking的常见做法包括:在实验中途进行分析,以决定是否继续收集数据[15,16];记录许多响应变量并决定分析后报告哪些变量[16,17],决定分析后是否包括或删除离群值[16],分析后排除、合并或拆分治疗组[2],包括或排除协变量分析后[14],如果分析产生显著的p值,则停止数据探索[18,19]。
Box 1. The History of P
Fisher [20]引入了零假设显著性检验(NHST),以客观地将有趣的发现与背景噪音[21]分开。NHST是大多数科学学科中使用最广泛的数据分析方法[22,23]。零假设是一个典型的声明,表明变量之间没有关系,或者实验操作没有影响。使用NHST,计算概率(即,p)如果零假设为真,则发现至少比观察结果更极端的效应[24,25]。
NHST方法使用任意的截止值(通常为0.05)。具有较小p值的结果被描述为“统计学显著”(“阳性”结果),其余的被描述为“不显著”(“阴性”结果)。这种武断的分界线导致了科学上可疑的做法,即认为“重要”的发现更有价值,更可靠,更可重复[24],从而激励了各种研究偏见。在计算机出现之前,测试统计(例如,t和F)常规手工计算,相关p值在统计表中查找。这里,p值是针对有限的一组值给出的(例如,0.001、0.01、0.02和0.05)[26]。然后,研究人员将p值报告为与检验统计量一致的最低阈值(例如,p < 0.05或p < 0.01)。使用现代统计软件,这种做法是不必要的,因为现在提供了精确的p值,但它仍然很常见。以前的研究表明,严格遵守p值阈值会使研究报告的方式产生偏差,即使在显著性区域内也是如此[27]。
p值很容易被误解。例如,它通常等同于关系的强度,但是一个很小的效应量可以在足够大的样本量下具有非常低的p值。同样,低p值并不意味着发现具有重大临床或生物学意义[28]。许多研究人员主张废除NHST(例如,[29,30])。然而,其他人注意到,许多与发表偏倚有关的问题在其他方法中也会出现,例如报告效应量及其置信区间[31]或贝叶斯可信区间[32]。发表偏倚不是p值本身的问题。它们只是反映了报告强有力的动机(即,显着)的影响。
如果公布的数据有偏见,数据综合可能会导致有缺陷的结论。荟萃分析是一组统计方法,联合收割机结合对同一问题的研究,以估计真实的效应量[33]。荟萃分析现在是综合治疗效果或存在关系的证据的“金标准”,并结合研究中的效应量估计以给出总体估计。荟萃分析指导医学治疗和政策决策的应用,并影响未来的研究方向[34]。然而,如果综合的研究不能反映效应量的真实分布,荟萃分析就会受到影响[5,35 -37]。
量化p-hacking很重要,因为假阳性的发布会阻碍科学进步。当假阳性结果进入文献时,它们可能非常持久。在许多领域,几乎没有复制研究的动机[38]。即使研究被重复,早期的积极研究往往比后来的消极研究受到更多的关注。此外,假阳性可能会激发对徒劳的研究项目的投资,甚至使整个领域失去信誉[14,16]。
尽管p-hacking的潜在重要性,正式和非正式的数据合成的后果是未知的。在这里,我们使用p曲线来解决这两个问题(见方框2)。首先,我们使用文本挖掘来获取来自广泛科学学科的论文中的报告p值。然后,我们根据p曲线的形状寻找p-黑客攻击的证据。其次,我们根据已发表的荟萃分析中使用的原始数据制作了p曲线。这使我们能够在研究人员明确确定为普遍感兴趣的特定假设(即,这是一个荟萃分析(metaanalysis)。
Box 2. The P-Curve: What Can It Tell Us?
p曲线是一组研究的p值分布。P曲线是评估已发表研究可靠性的有用工具。在这里,我们概述了如何使用它们来评估文献。
证据的价值。人们可以通过检验p值的分布,特别是那些在0和0.05之间的分布,来检验一组发现是否包含证据价值。“证据价值”是指某一特定假设的已发表证据是否表明效应量非零。
当所研究现象的效应量为零时,每个p值都有可能被观察到。零假设下p值的预期分布是均匀的(图1A和图2A中的黑线),使得p<0.05的概率为5%,p<0.04的概率为4%,以此类推。另一方面,当真实效应量为非零时,p值的预期分布是右偏指数分布[39-42](图1B和图2B中的黑线)。当真实效应很强时,研究人员更有可能获得非常低的p值(例如,p<0.001)比中等低的p值(例如,0.01),并且不太可能获得不显著的p值(p > 0.05)[41]。因此,随着真实效应量的增加,p曲线更加向右倾斜[41]。
出版偏见。一些研究已经绘制了p值或相关检验统计量(即,Z或t)在p=0.05(通常在0.01到0.1的范围内)的主要显著性阈值附近的分布。P值显著下降到0.05以上(或Z值为1.96)(红线,图1A和图1B)被解释为发表偏见的证据(例如,[40,43-45])。虽然p值在0.05左右的分布不连续表明存在发表偏见,但它不能区分选择性发表偏见和p黑客攻击(见方框1)。
p-Hacking。然而,通过仅考虑重要发现,p曲线可用于识别p黑客攻击[14]。如果研究者对一个真正不显著的结果进行p-破解,并将其转化为显著的结果,那么p-曲线的形状将发生改变,接近感知显著性阈值(通常p = 0.05)。因此,一条p-切割的p-曲线将具有略低于0.05的过量p-值[12,40,41]。如果研究者在没有真实效应的情况下进行p-hack,则p曲线将从平坦变为左斜(图2A)。然而,如果研究人员在存在真实效应时进行p-hack,则p-曲线将是指数型的,具有右偏,但在分布尾部略低于0.05的p-值将被过度表示(图2B)。p-黑客攻击和选择性发表偏倚都预测p-曲线在0.05附近不连续,但只有p-黑客攻击预测p-值在0.05以下的过剩[12]。然而,p曲线的确切形状将取决于真实效应(即:p-劈裂之前的p-曲线)和p-劈裂的强度[41]。
评估p-曲线的p-黑客攻击和证据价值。与之前的研究相似(例如,[14,43])我们采用二项测试来寻找证据的证据ofevidential价值和phacking在我们的文本挖掘和荟萃分析数据集。我们使用双尾符号检验来检验证据价值,其中我们比较了落在0 p < 0.025分组中的p值的数量与落在0.025 p < 0.05分组中的p值的数量。在没有证据值的零假设下,这些箱中的每个箱中的p值的期望数量相等。较低区间中显著更多的p值与证据值一致(即,右倾斜的p曲线),并且上部箱中显着更多的p值与严重的p黑客一致。该检验是Simohnson等人提出的检验的略微修改版本。[41],他们建议使用两个单独的单尾符号检验用于相同的目的。
具有p = 0.025阈值的双尾符号测试(上文)和Simonsohn等人提出的测试。[41]可以检测严重的p-黑客攻击,但对更温和(可以说更现实)的p-黑客攻击水平不敏感。尤其是当平均真实效应大小很强时,这一点更是如此,因为引入p曲线的右偏斜将掩盖p黑客攻击造成的左偏斜。检测p-黑客攻击的一种更敏感的方法是寻找p值的相对频率的增加,刚好低于0.05,我们预计p-黑客攻击的信号最强。在无p-黑客的零假设下,我们预期p值的分布均匀接近0.05(如果真实效应大小为零),或右偏(即,如果至少某些效应量为非零)。然而,p-hacking引入了接近0.05的额外p值,产生了左偏斜。因此,一个简单且保守的p-黑客测试涉及测试零假设,即p值略低于0.05是均匀分布或右偏。我们使用单尾符号检验来询问邻接0.05的bin中的p值的数量是否大于相邻较低bin中的p值的数量。如果使用更小的箱,这个测试更有可能检测到p-黑客,因为当平均效应大小为正时p值是右偏的(掩蔽p-黑客),但在实践中,使用更小的箱将减少样本大小(因此功率)的测试。我们选择了0.005的箱宽,下箱指定为0.04 < p < 0.045,上箱指定为0.045 < p < 0.05。我们选择p < 0.05作为上限的截止值(见[3]),而不是p = 0.05(见[46]),因为我们怀疑许多作者不认为p = 0.05是显著的。作为对phacking强度的测量,我们给出了上箱中p值的比例和相关的95%置信区间(根据Clopper和Pearson [47]使用R中的binom检验函数计算)。
我们分别对每个学科和荟萃分析数据集进行了上述分析。此外,我们在两个主要数据集(分别为p值的文本挖掘和荟萃分析数据集)中测试了整体证据值(双尾测试)和p黑客的迹象(单尾测试)。为此,我们使用每个学科或荟萃分析(取决于分析的数据集)的上区间中出现的p值比例,并运行二项式广义线性模型来测试观察到的截距是否不同于0.5(即,两个箱中的病例数相等)。这种方法相当于在结合单个学科或问题时对显著趋势进行荟萃分析测试,因为每个学科或问题都按其样本量加权。我们使用的R代码存放在Dryad [48]。
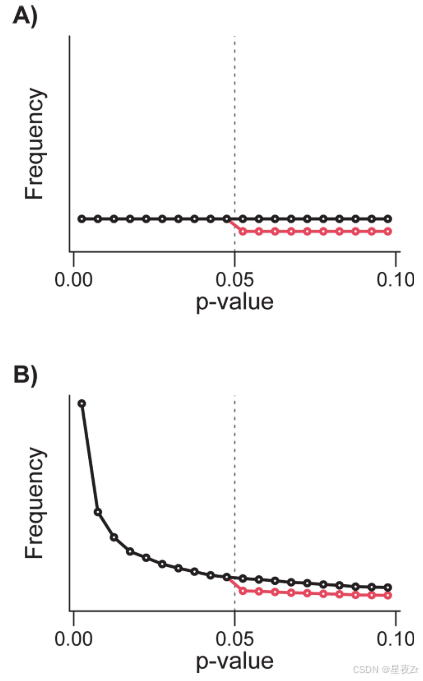
图1.发表偏倚对显著性阈值0.05附近p值分布的影响。A)黑线表示无证据值时的p值分布,红线表示发表偏倚如何影响该分布。B)黑线表示存在证据价值时的p值分布,红线表示发表偏倚如何影响该分布。文件抽屉效应导致的发表偏倚检验通常比较0.05两侧每个区间的p值数量。
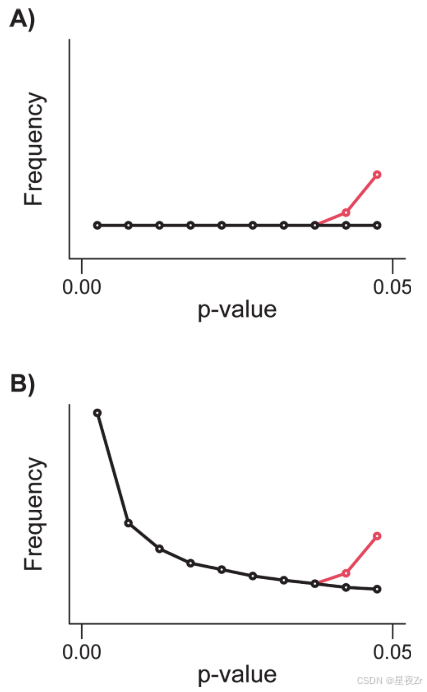
见图2。在显著性范围内p-黑客对p-值分布的影响。A)黑线表示当没有证据值时p值的分布,红线表示p黑客如何影响该分布。B)黑线表示当存在证据值时p值的分布,红线表示p黑客如何影响该分布。对p-黑客攻击的测试通常比较两个相邻bin中的p值的数量刚好低于0.05。
Assessing the Extent of P-Hacking in the Scientific Literature Using Text-Mining
基于文本挖掘的科技文献中P-Hacking程度评估
我们使用文本挖掘来搜索PubMed数据库中所有开放获取论文中的p值(见S1文本)。为了量化“证据价值”(即,如果有证据表明真实效应量非零)和p-hacking,我们从获得的p值构建p曲线(见框2)。我们分别对从结果部分提取的p值和从摘要中提取的p值进行了验证值和p黑客攻击的测试。研究人员已经发现了使用文本挖掘数据寻找出版偏见的弱点(例如,[46])。在此,我们采取了几项措施来克服这些弱点(见S1文本)。
汇集所有学科的p值,有强有力的证据表明“证据价值”;也就是说,研究人员似乎主要研究具有非零效应大小的现象,如结果中发现的p值p曲线的强烈右偏所示。(二项式glm:上部箱中p值的估计比例(0.025 p < 0.05)(CI下限,CI上限)= 0.257(0.254,0.259),p < 0.001,n = 14个学科)和摘要(二项式glm:上区间中p值的估计比例(0.025 p < 0.05)(下CI,上CI)= 0.262(0.257,0.267),p < 0.001,n = 10个学科)。我们在文本挖掘数据中代表的每个学科中都发现了显著的证据价值,无论我们是否测试了结果或摘要的p值(表1;表2)。然而,基于所有学科的净趋势,在两个结果中也有强有力的证据表明p-黑客行为(二项式glm:上区间p值的估计比例(0.045 < p < 0.05))(CI下限)= 0.546(0.536),p < 0.001,n = 14个学科)和摘要(二项glm:上箱中p值的估计比例(0.045 < p < 0.05)(较低CI)= 0.537(0.518),p < 0.001,n = 10个学科)。在大多数学科中,上箱中的p值比下箱中的p值多;当我们查看从每个学科的结果部分文本挖掘的p值时,我们具有良好的统计能力(即,健康和医学科学、生物科学和多学科),这种差异具有统计学显著性(表1,图3A)。当查看从摘要中挖掘的p值时,尽管总体趋势显著,但只有多学科和信息与计算机科学类别是显著的(表2,图3B)。
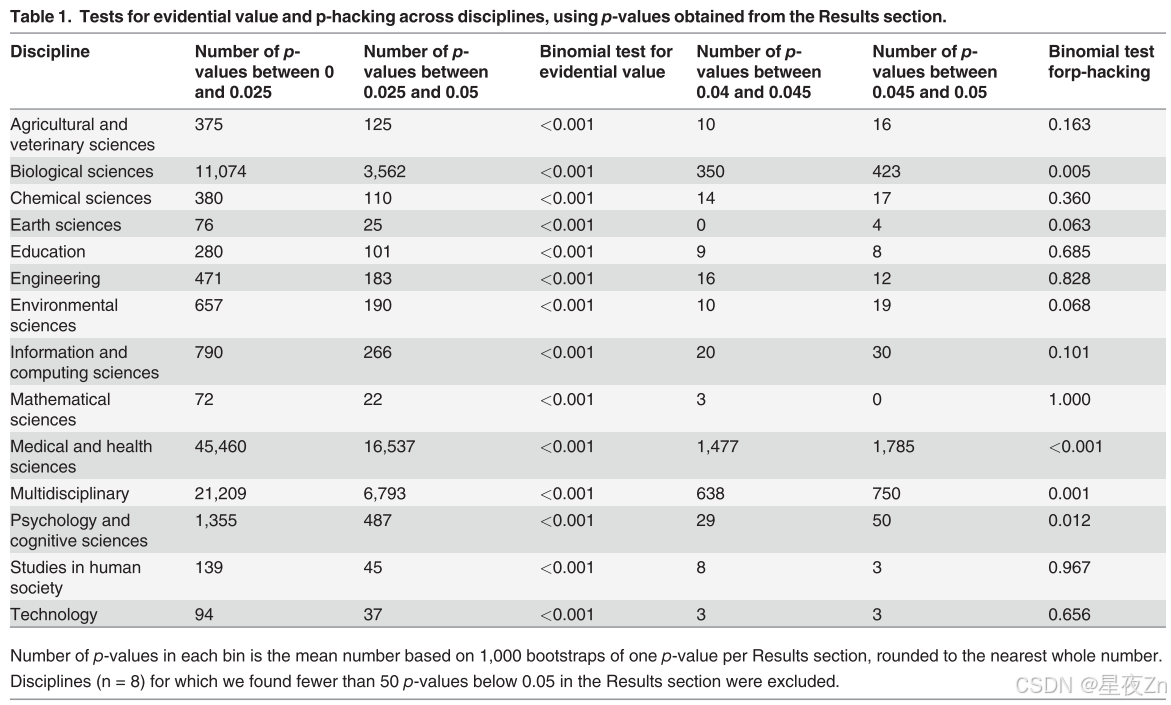
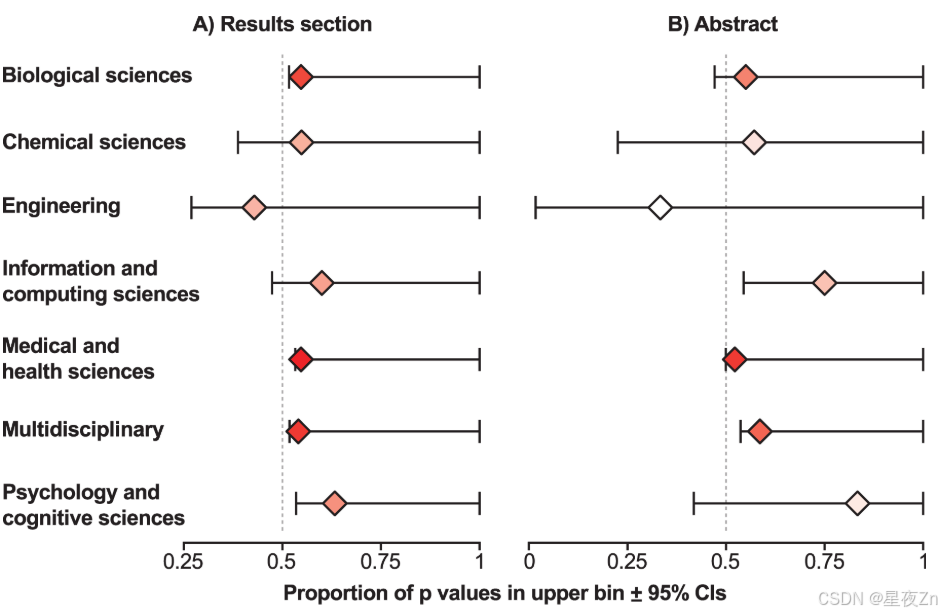
附图3.跨科学学科的p-黑客攻击证据。A)从结果部分获得的p值中获得p黑客攻击的证据。B)从摘要中获得的p值的phacking证据。p-hacking的强度表示为上箱中p值的比例(0.045 < p < 0.05),具有单侧95%置信区间(根据Clopper和Pearson [47]使用R中的binom.检验函数计算)。仅列出了结果部分的文本挖掘返回的p值在0.04和0.05之间超过25个的学科。标记颜色根据样本量进行着色:白色表示样本量较小,红色表示样本量较大。
我们的文本挖掘表明,p-hacking很普遍。其他一些研究对小得多的期刊的p曲线进行了检查,也发现了p-黑客攻击的证据[12,40,45]。相比之下,Jager和Leek [3]在对五种医学期刊的文本挖掘研究中没有发现p-黑客的证据。然而,他们因使用摘要中的p值而受到批评[46],因为在摘要中报告p值是可选的,所以它们更可能只包含最强的结果(即,最小p值)。这种偏见会夸大我们分析中的证据价值,并使检测p-黑客变得更加困难(例如,如果研究人员审查的结果与p = 0.049从摘要,但不是p = 0.041)。即使摘要更有可能包含与主要假设相关的p值,预计这些p值比来自不太有趣的辅助测试的p值更强,但较低的功率和报告偏差可能会阻碍使用从摘要获得的p值检测p黑客攻击。事实上,我们在所有科学学科的数据(我们的整体分析)中使用摘要或结果部分的p值时发现了phacking的证据,这支持了p-hacking普遍存在的结论。
虽然我们提出的证据表明,p-黑客是普遍的,仍然有一个强大的右偏在所有的p-曲线,我们检查。这与研究人员调查导致反驳零假设的预测是一致的,这意味着生命科学家研究的平均真实效应大小是非零的。鉴于最近对研究结果缺乏可重复性的担忧(例如,[49]但见[50])和许多已发表的结果是错误的可能性[2],我们的结果是令人放心的。当然,重要的是要注意,当使用文本挖掘时,我们会结合许多不同类型的问题来生成p曲线。因此,目前还不清楚是否有一些研究领域或问题包含在我们考虑的学科中,其发表结果的平均效应量为零(即,P曲线是平坦的)。为了检验这一点,重要的是还要看看明确定义的研究问题的p曲线[41]。
The Consequences of P-Hacking for Meta-analyses
荟萃分析是一种系统综合文献并通过对多项研究的效应量进行平均(根据其可靠性对每项研究进行加权)来量化效应或关系的优秀方法[33,51]。然而,荟萃分析仅与其使用的数据一样好,最近的一项研究估计,高达37%的临床试验荟萃分析报告了显着的平均效应量代表假阳性[34]。证据价值和p-hacking的测试可以很容易地用于检测荟萃分析中使用的数据集的偏差。我们鼓励进行荟萃分析的研究人员报告与每个效应量相关的p值(这不是目前的标准做法),然后测试证据价值和p-黑客。关于这种做法的最新例子,见[52]。为了证明这一过程,我们从进化生物学家研究性选择的荟萃分析中获得了p值[53-61](见S1文本)。
当我们对这些荟萃分析中使用的所有数据进行自己的荟萃分析时,有明确的证据表明,研究人员对效应量非零的说法具有很强的证据价值(二项式glm:上区间中p值的估计比例(0.025 p < 0.05)(下CI,上CI)= 0.202(0.179,0.228),p<0.001,n = 12个数据集)。然后,我们分别检查了每个数据集,发现12条p曲线中有9条具有统计学显著性证据价值(表3)。未显示证据价值的三条p曲线具有三个最低的样本量,因此检测证据价值的统计功效较低可能解释了缺乏显著性。同样,值得注意的是,充分研究的现象的证据价值并不是给定的(参见[62]中的一个现实世界的例子)。
当考虑p-黑客的证据时,我们发现当我们包括错误报告的p-值时(p < 0.05,实际上更大;总共16个案例-见S1正文),12条p-曲线中有7条的上部比下部的p-值更多(表3)。这种偏差在一个数据集中很明显(图4),该数据集也是样本量最大的数据集。然而,当我们从我们的分析中排除错误报告的p值时,p-黑客攻击的证据消失了(表3)。有人可能会说,在我们的二项式检验的上箱中包含错误报告的p值会使我们的结果偏向于检测p-黑客攻击,但报告“p<0.05”的不显著结果是p-黑客攻击的一个组成部分,不应该被忽视。事实上,Leggett等人。[45]还发现在0.05阈值附近的p值存在相当大的误报。他们指出,当p值不显著时,p值更有可能被误报为显著,而不是相反,而且这种“错误”近年来变得越来越普遍。
更重要的是,当我们的分析中包括误报的p值时,我们发现12项荟萃分析的p曲线的荟萃分析中有显著的p值黑客(二项式glm:上区间p值的估计比例(0.045 < p < 0.05))(CI下限)= 0.615(0.513),p = 0.033;排除误报p值:0.489(0.375),p = 0.443)。虽然进行荟萃分析的问题可能不是科学家提出的所有研究问题的代表性样本,但我们的研究结果表明,研究人员认为重要到足以保证荟萃分析的问题的研究往往是p-黑客攻击。这是否会影响荟萃分析的一般结论,取决于p-hacking的程度和真实效果的强度。例如,我们在发表的荟萃分析中发现,在12个问题中,只有一个问题有统计学意义的p-黑客攻击迹象(图4)。然而,这项研究[56]也显示了很强的证据价值,0.045-0.05区间的p值仅占已发表的显著p值的一小部分。因此,尽管p-hacking可能夸大了估计的平均效应量,但p-hacking不太可能改变本荟萃分析中得出的定性结论。一般来说,荟萃分析可能对p-黑客攻击导致的夸大效应大小具有鲁棒性,因为:1)在其他条件相同的情况下,最容易受到p-黑客攻击的研究是那些样本量较小的研究(即,因为低的统计功效意味着更少的显著结果的机会),并且这些在荟萃分析中被给予更少的权重,2)至少在某些领域(例如,生态学和进化),元分析经常使用与原始论文的主要焦点没有直接关系的数据。与次要问题相关的p值不太可能被p黑客攻击。检验效应大小的估计值对p-黑客攻击的敏感程度的一种方法是随机删除适当数量的研究,这些研究导致p-曲线中略低于0.05的驼峰。或者,荟萃分析师可以使用p曲线(即,仅使用他们发现的显著p值),这是一种被提出来解释发表偏倚并在存在p-hacking时提供真实效果的保守估计的方法[62,63]。p曲线方法的开发正在进行中,我们期待着进一步测试它们纠正文件抽屉效应、p黑客和其他形式的出版偏差的能力,因为真实的世界数据可能违反其有效性模拟中的一些假设。
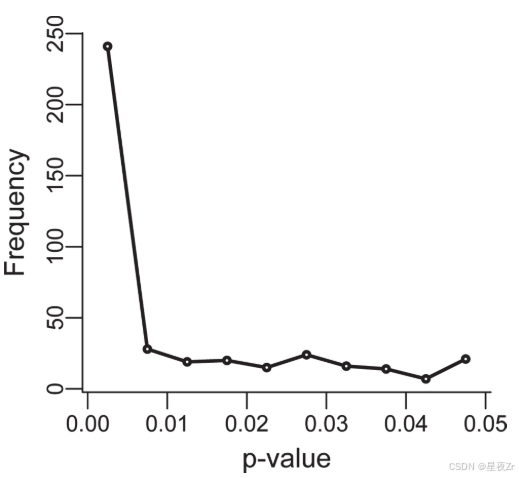
图4. 与Jiang et al.(2013)进行的荟萃分析相关的p值分布。p-曲线显示了证据价值(强右偏)和p-黑客攻击(p-值上升略低于0.05)的证据。
Summary and Conclusions
我们的研究提供了两条经验证据,证明p-hacking在科学文献中很普遍。我们的文本挖掘方法是基于一个非常大的数据集,由来自不同学科和问题的p值,而我们的荟萃分析方法由关于一些特定假设的p值。这两种方法都产生了类似的结果:关键研究问题的平均效应量非零的说法具有证据价值–研究人员根据重要的研究发现得出的结论–但估计的平均效应量可能被p-黑客夸大了。
当职业发展是通过出版物的产出来评估的时候,完全消除p-黑客是不可能的,出版决定受到p值或其他关系统计支持措施的影响。即便如此,研究团体和科学出版商还是可以采取一些措施来减少p-hacking的发生(见方框3)。
Box 3. Recommendations
减少p-hacking的关键是对研究人员进行更好的教育。许多导致p-hacking的做法仍然被认为是可以接受的。约翰等人[16]测量了心理学中有问题的研究实践的普遍性。他们询问调查参与者是否曾经从事过一系列有问题的研究实践,如果是,他们是否认为他们的行为在0 -2级(0 =否,1 =可能,2 =是)中是合理的。超过50%的参与者承认“未能报告研究的所有依赖性指标”,“在查看结果是否显著后决定是否收集更多数据”,这些做法的平均防御性评级大于1.5。这表明,许多研究人员p-hack,但不明白这是一种科学不端行为的程度。令人惊讶的是,如果研究期间获得了重大结果,一些动物伦理委员会甚至鼓励或强制终止研究,这是一种特别恶劣的p-黑客攻击形式(匿名评论者,个人通讯)。
What can researchers do?
- 明确将研究标记为预先指定的(即,设计用于回答特定问题,其中方法和分析的详细信息可在数据收集之前完整报告)或探索性(即,涉及对看起来有趣的数据的探索,其中使用的方法和分析通常是事后的[13]),以便读者可以适当谨慎地对待结果。预先指定的研究结果提供了比探索性研究更有说服力的证据[2]。
- 遵循通用分析标准[2];仅测量已知(或预测)重要的响应变量;并使用足够的样本量。-
- 尽可能进行数据盲分析。这种方法很难获得具体的结果。
- 在审查或评估研究时,更加重视研究方法和数据收集的质量,而不是随后发现的重要性或新奇。理想情况下,方法应独立于结果进行评估[13,44]。
What can journals do?
- 为数据分析和结果的完整报告提供明确和详细的指南。例如,声明有必要报告效应量,无论是小还是大,报告所有p值到小数点后三位[27,64],报告样本量,最重要的是,明确整个分析过程(不仅仅是用于生成报告p值的最终检验)。这将减少p-hacking,并有助于收集数据进行荟萃分析和文本挖掘研究。
- 鼓励和/或提供方法预先指定的平台[13,65]。尽管出版物中的方法和结果并不总是与其预先指定的方案相匹配[5,66],但预先指定允许读者评估p-黑客攻击的风险,并相应地调整他们对报告结果的信心。
- 鼓励和/或提供开放获取原始数据的平台。虽然对原始数据的访问并不能防止p-hacking,但它确实使研究人员对边际结果更加负责,并允许读者重新分析数据以检查结果的稳健性。
以上内容全部使用机器翻译,如果存在错误,请在评论区留言。欢迎一起学习交流!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









