










ETL 实战
实验数据来源
- https://groupllens.org/datasets/movielens/
- 下载一个精简数据集。rating.csv 电影评分记录 :userId给电影评价的用户ID movieId 电影的ID rating 打分5分满分,timestamp时间戳
数据加载
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import to_utc_timestamp
spark = SparkSession.builder.master("local[*]").appName("PySpark ETL").getOrCreate()
sc = spark.sparkContext
#############################################
#相对路径,文件包含标题行
df = spark.read.csv('hdfs://localhost:9000/ml-latest-small/ratings.csv',header=True)
#打印默认的字段类型信息
df.printSchema()
#打印前20条数据
df.show()
#打印总行数
print(df.count())
root
|-- userId: string (nullable = true)
|-- movieId: string (nullable = true)
|-- rating: string (nullable = true)
|-- timestamp: string (nullable = true)
+------+-------+------+---------+
|userId|movieId|rating|timestamp|
+------+-------+------+---------+
| 1| 1| 4.0|964982703|
| 1| 3| 4.0|964981247|
| 1| 6| 4.0|964982224|
| 1| 47| 5.0|964983815|
| 1| 50| 5.0|964982931|
| 1| 70| 3.0|964982400|
| 1| 101| 5.0|964980868|
| 1| 110| 4.0|964982176|
| 1| 151| 5.0|964984041|
| 1| 157| 5.0|964984100|
| 1| 163| 5.0|964983650|
| 1| 216| 5.0|964981208|
| 1| 223| 3.0|964980985|
| 1| 231| 5.0|964981179|
| 1| 235| 4.0|964980908|
| 1| 260| 5.0|964981680|
| 1| 296| 3.0|964982967|
| 1| 316| 3.0|964982310|
| 1| 333| 5.0|964981179|
| 1| 349| 4.0|964982563|
+------+-------+------+---------+
only showing top 20 rows
100836
但是我们发现读取文件后,用printSchema打印各个字段类型都是string,不满足业务的实际情况
df = spark.read.csv('hdfs://localhost:9000/ml-latest-small/ratings.csv',header=True,inferSchema=True)
df.printSchema()
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- rating: double (nullable = true)
|-- timestamp: integer (nullable = true) |-- timestamp: integer (nullable = true)
观察资料
# Matplotlib 绘制折线图
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
#支持中文,否则乱码
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
#准备数据
t = np.arange(0.0, 2.0, 0.01)
s = 1 + np.sin(2 * np.pi * t)
fig, ax = plt.subplots()
#设置窗口标题
fig.canvas.set_window_title('折线图示例')
#绘图,折线图
ax.plot(t, s)
#坐标轴设置
ax.set(xlabel='时间 (s)', ylabel='电压 (mV)',title='折线图')
ax.grid()
plt.show()
对rating.csv数据进行探究
df = spark.read.csv('hdfs://localhost:9000/ml-latest-small/ratings.csv',header=True,inferSchema=True)
df.show(10)
df.printSchema()
# 对rating列进行数据统计分析
df.select("rating").describe().show()
#打印资料的行数量和列数量
print(df.count(),len(df.columns))
#删除所有列的空值和NaN
dfNotNull=df.na.drop()
print(dfNotNull.count(),len(dfNotNull.columns))
#创建视图movie
df.createOrReplaceTempView("movie")
#spark sql
df2 = spark.sql("select count(*) as counter, rating from movie \
group by rating order by rating asc")
df2.show()
##############################################
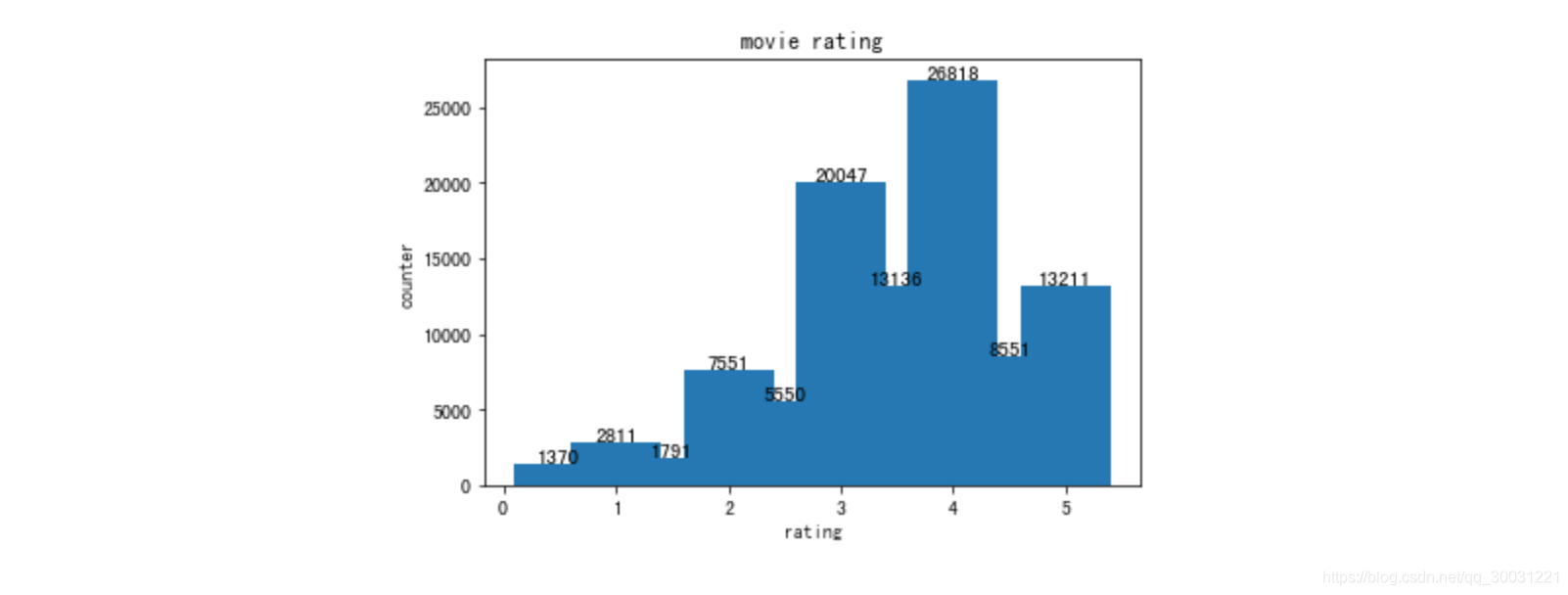
from matplotlib import pyplot as plt
pdf = df2.toPandas()
x = pdf["rating"]
y = pdf["counter"]
plt.xlabel("rating")
plt.ylabel("counter")
plt.title("movie rating")
plt.bar(x,y)
#显示数值标签
for x1,y1 in zip(x,y):
plt.text(x1, y1+0.05, '%.0f' %y1, ha='center', va= 'bottom',fontsize=11)
plt.show()
+------+-------+------+---------+
|userId|movieId|rating|timestamp|
+------+-------+------+---------+
| 1| 1| 4.0|964982703|
| 1| 3| 4.0|964981247|
| 1| 6| 4.0|964982224|
| 1| 47| 5.0|964983815|
| 1| 50| 5.0|964982931|
| 1| 70| 3.0|964982400|
| 1| 101| 5.0|964980868|
| 1| 110| 4.0|964982176|
| 1| 151| 5.0|964984041|
| 1| 157| 5.0|964984100|
+------+-------+------+---------+
only showing top 10 rows
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- rating: double (nullable = true)
|-- timestamp: integer (nullable = true)
+-------+------------------+
|summary| rating|
+-------+------------------+
| count| 100836|
| mean| 3.501556983616962|
| stddev|1.0425292390606342|
| min| 0.5|
| max| 5.0|
+-------+------------------+
100836 4
100836 4
+-------+------+
|counter|rating|
+-------+------+
| 1370| 0.5|
| 2811| 1.0|
| 1791| 1.5|
| 7551| 2.0|
| 5550| 2.5|
| 20047| 3.0|
| 13136| 3.5|
| 26818| 4.0|
| 8551| 4.5|
| 13211| 5.0|
+-------+------+
选择、筛选与聚合
- 转换时间
- UNIX_TIMESTAMP:是把时间字段转化为整型,需要注意的是有些数据库需要指明时间字段类型,比如MySQL里是可以直接UNIX_TIMESTAMP(‘20200223’),而某些大数据平台需要UNIX_TIMESTAMP(‘20200223’,‘yyyyMMdd’)
- FROM_UNIXTIME:从整型里把时间整型进行破解成想要的时间格式,使用时可指定格式
from pyspark.sql.functions import from_unixtime
df = spark.read.csv('hdfs://localhost:9000/ml-latest-small/ratings.csv',header=True,inferSchema=True)
df = df.withColumn("rating", df.rating.cast("double"))
#新增一列date
df = df.withColumn("date",from_unixtime(df.timestamp.cast("bigint"), 'yyyy-MM-dd'))
df = df.withColumn("date",df.date.cast("date"))
#删除timestamp列
df = df.drop("timestamp")
df.show(10)
+------+-------+------+----------+
|userId|movieId|rating| date|
+------+-------+------+----------+
| 1| 1| 4.0|2000-07-31|
| 1| 3| 4.0|2000-07-31|
| 1| 6| 4.0|2000-07-31|
| 1| 47| 5.0|2000-07-31|
| 1| 50| 5.0|2000-07-31|
| 1| 70| 3.0|2000-07-31|
| 1| 101| 5.0|2000-07-31|
| 1| 110| 4.0|2000-07-31|
| 1| 151| 5.0|2000-07-31|
| 1| 157| 5.0|2000-07-31|
+------+-------+------+----------+
- Inner Join 电影表
from pyspark.sql.types import BooleanType
from pyspark.sql.functions import udf
df2 = spark.read.csv('hdfs://localhost:9000/ml-latest-small/movies.csv',header=True)
df3 = df.join(df2, df.movieId == df2.movieId,"inner").select("userId",df.movieId,"title","date","rating")
#定义普通的python函数
def isLike(v):
if v > 4:
return True
else:
return False
#创建udf函数
udf_isLike=udf(isLike,BooleanType())
df3 = df3.withColumn("isLike",udf_isLike(df3["rating"]))
df3.show()
+------+-------+--------------------+----------+------+------+
|userId|movieId| title| date|rating|isLike|
+------+-------+--------------------+----------+------+------+
| 1| 1| Toy Story (1995)|2000-07-31| 4.0| false|
| 1| 3|Grumpier Old Men ...|2000-07-31| 4.0| false|
| 1| 6| Heat (1995)|2000-07-31| 4.0| false|
| 1| 47|Seven (a.k.a. Se7...|2000-07-31| 5.0| true|
| 1| 50|Usual Suspects, T...|2000-07-31| 5.0| true|
| 1| 70|From Dusk Till Da...|2000-07-31| 3.0| false|
| 1| 101|Bottle Rocket (1996)|2000-07-31| 5.0| true|
| 1| 110| Braveheart (1995)|2000-07-31| 4.0| false|
| 1| 151| Rob Roy (1995)|2000-07-31| 5.0| true|
| 1| 157|Canadian Bacon (1...|2000-07-31| 5.0| true|
+------+-------+--------------------+----------+------+------+
- 定义Pandas UDF函数,对象聚合 要求Pyspark2.3 以上
from pyspark.sql.functions import pandas_udf, udf
#定义pandas udf函数,用于GroupedData
@pandas_udf("string", PandasUDFType.GROUPED_AGG)
def fmerge(v):
return ','.join(v)
df5 = spark.read.csv('hdfs://localhost:9000/ml-latest-small/tags.csv',header=True)
df5 = df5.drop("timestamp")
#groupBy聚合
df7 = df5.groupBy(["userId","movieId"]).agg(fmerge(df5["tag"]))
df7 = df7.withColumnRenamed("fmerge(tag)","tags")
#select选择
df6 = df3.join(df7,(df3.movieId == df7.movieId) & (df3.userId == df7.userId))\
.select(df3.userId,df3.movieId,"title","date","tags","rating","isLike") \
.orderBy(["date"], ascending=[0])
#filter筛选
df6 = df6.filter(df.date>'2015-10-25')
df6.show(20)
- 存储数据
#存储数据text格式
f6.rdd.coalesce(1).saveAsTextFile("movie-out")
#存储数据CSV格式
df6.coalesce(1).write.format("csv").option("header","true").save("movie-out-csv")
#parquet格式
df6.write.format('parquet').save("movie-out-parquet")
#json格式
df6.coalesce(1).write.format("json").save("movie-out-json")
#存储到数据库
#需要把对应的数据库驱动安装到目录jars下
#save to file
db_url = "jdbc:sqlserver://localhost:1433;databaseName=bg_data;user=root;password=root"
db_table = "movie"
#overwrite会重新生成表 append
df6.write.mode("overwrite").jdbc(db_url, db_table)
机器学习实战
实验数据来源
- https://www.kaggle.com/c/titanic
- 通过训练数据集分析哪些乘客可能幸存
数据加载
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import to_utc_timestamp
spark = SparkSession.builder.master("local[*]").appName("PySpark AI").getOrCreate()
sc = spark.sparkContext
print("Titanic train.csv Info")
df_train = spark.read.csv('hdfs://localhost:9000/titanic/train.csv',header=True,inferSchema=True).cache()
df_train.printSchema()
print(df_train.count(),len(df_train.columns))
df_train.show()
print("#############################################")
print("Titanic test.csv Info")
df_test = spark.read.csv('hdfs://localhost:9000/titanic/test.csv',header=True,inferSchema=True).cache()
df_test.printSchema()
print(df_test.count(),len(df_test.columns))
df_test.show()
Titanic train.csv Info
root
|-- PassengerId: integer (nullable = true)
|-- Survived: integer (nullable = true)
|-- Pclass: integer (nullable = true)
|-- Name: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Age: double (nullable = true)
|-- SibSp: integer (nullable = true)
|-- Parch: integer (nullable = true)
|-- Ticket: string (nullable = true)
|-- Fare: double (nullable = true)
|-- Cabin: string (nullable = true)
|-- Embarked: string (nullable = true)
891 12
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
|PassengerId|Survived|Pclass| Name| Sex| Age|SibSp|Parch| Ticket| Fare|Cabin|Embarked|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
| 1| 0| 3|Braund, Mr. Owen ...| male|22.0| 1| 0| A/5 21171| 7.25| null| S|
| 2| 1| 1|Cumings, Mrs. Joh...|female|38.0| 1| 0| PC 17599|71.2833| C85| C|
| 3| 1| 3|Heikkinen, Miss. ...|female|26.0| 0| 0|STON/O2. 3101282| 7.925| null| S|
| 4| 1| 1|Futrelle, Mrs. Ja...|female|35.0| 1| 0| 113803| 53.1| C123| S|
| 5| 0| 3|Allen, Mr. Willia...| male|35.0| 0| 0| 373450| 8.05| null| S|
| 6| 0| 3| Moran, Mr. James| male|null| 0| 0| 330877| 8.4583| null| Q|
| 7| 0| 1|McCarthy, Mr. Tim...| male|54.0| 0| 0| 17463|51.8625| E46| S|
| 8| 0| 3|Palsson, Master. ...| male| 2.0| 3| 1| 349909| 21.075| null| S|
| 9| 1| 3|Johnson, Mrs. Osc...|female|27.0| 0| 2| 347742|11.1333| null| S|
| 10| 1| 2|Nasser, Mrs. Nich...|female|14.0| 1| 0| 237736|30.0708| null| C|
| 11| 1| 3|Sandstrom, Miss. ...|female| 4.0| 1| 1| PP 9549| 16.7| G6| S|
| 12| 1| 1|Bonnell, Miss. El...|female|58.0| 0| 0| 113783| 26.55| C103| S|
| 13| 0| 3|Saundercock, Mr. ...| male|20.0| 0| 0| A/5. 2151| 8.05| null| S|
| 14| 0| 3|Andersson, Mr. An...| male|39.0| 1| 5| 347082| 31.275| null| S|
| 15| 0| 3|Vestrom, Miss. Hu...|female|14.0| 0| 0| 350406| 7.8542| null| S|
| 16| 1| 2|Hewlett, Mrs. (Ma...|female|55.0| 0| 0| 248706| 16.0| null| S|
| 17| 0| 3|Rice, Master. Eugene| male| 2.0| 4| 1| 382652| 29.125| null| Q|
| 18| 1| 2|Williams, Mr. Cha...| male|null| 0| 0| 244373| 13.0| null| S|
| 19| 0| 3|Vander Planke, Mr...|female|31.0| 1| 0| 345763| 18.0| null| S|
| 20| 1| 3|Masselmani, Mrs. ...|female|null| 0| 0| 2649| 7.225| null| C|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
only showing top 20 rows
#############################################
Titanic test.csv Info
root
|-- PassengerId: integer (nullable = true)
|-- Pclass: integer (nullable = true)
|-- Name: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Age: double (nullable = true)
|-- SibSp: integer (nullable = true)
|-- Parch: integer (nullable = true)
|-- Ticket: string (nullable = true)
|-- Fare: double (nullable = true)
|-- Cabin: string (nullable = true)
|-- Embarked: string (nullable = true)
418 11
+-----------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
|PassengerId|Pclass| Name| Sex| Age|SibSp|Parch| Ticket| Fare|Cabin|Embarked|
+-----------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
| 892| 3| Kelly, Mr. James| male|34.5| 0| 0| 330911| 7.8292| null| Q|
| 893| 3|Wilkes, Mrs. Jame...|female|47.0| 1| 0| 363272| 7.0| null| S|
| 894| 2|Myles, Mr. Thomas...| male|62.0| 0| 0| 240276| 9.6875| null| Q|
| 895| 3| Wirz, Mr. Albert| male|27.0| 0| 0| 315154| 8.6625| null| S|
| 896| 3|Hirvonen, Mrs. Al...|female|22.0| 1| 1| 3101298|12.2875| null| S|
| 897| 3|Svensson, Mr. Joh...| male|14.0| 0| 0| 7538| 9.225| null| S|
| 898| 3|Connolly, Miss. Kate|female|30.0| 0| 0| 330972| 7.6292| null| Q|
| 899| 2|Caldwell, Mr. Alb...| male|26.0| 1| 1| 248738| 29.0| null| S|
| 900| 3|Abrahim, Mrs. Jos...|female|18.0| 0| 0| 2657| 7.2292| null| C|
| 901| 3|Davies, Mr. John ...| male|21.0| 2| 0| A/4 48871| 24.15| null| S|
| 902| 3| Ilieff, Mr. Ylio| male|null| 0| 0| 349220| 7.8958| null| S|
| 903| 1|Jones, Mr. Charle...| male|46.0| 0| 0| 694| 26.0| null| S|
| 904| 1|Snyder, Mrs. John...|female|23.0| 1| 0| 21228|82.2667| B45| S|
| 905| 2|Howard, Mr. Benjamin| male|63.0| 1| 0| 24065| 26.0| null| S|
| 906| 1|Chaffee, Mrs. Her...|female|47.0| 1| 0| W.E.P. 5734| 61.175| E31| S|
| 907| 2|del Carlo, Mrs. S...|female|24.0| 1| 0| SC/PARIS 2167|27.7208| null| C|
| 908| 2| Keane, Mr. Daniel| male|35.0| 0| 0| 233734| 12.35| null| Q|
| 909| 3| Assaf, Mr. Gerios| male|21.0| 0| 0| 2692| 7.225| null| C|
| 910| 3|Ilmakangas, Miss....|female|27.0| 1| 0|STON/O2. 3101270| 7.925| null| S|
| 911| 3|"Assaf Khalil, Mr...|female|45.0| 0| 0| 2696| 7.225| null| C|
+-----------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
only showing top 20 rows
统计描述
df_train = spark.read.csv('hdfs://localhost:9000/titanic/train.csv',header=True,inferSchema=True).cache()
#计算基本的统计描述信息
df_train.describe("Age","Pclass","SibSp","Parch").show()
df_train.describe("Sex","Cabin","Embarked","Fare","Survived").show()
pdf = df_train.groupBy('sex','Survived') \
.agg({'PassengerId': 'count'}) \
.withColumnRenamed("count(PassengerId)","count") \
.orderBy("sex") \
.toPandas()
print(pdf)
pdf = df_train.groupBy('Pclass','Survived') \
.agg({'PassengerId': 'count'}) \
.withColumnRenamed("count(PassengerId)","count") \
.orderBy("Pclass") \
.toPandas()
print(pdf)
pdf = df_train.groupBy('Parch','Survived') \
.agg({'PassengerId': 'count'}) \
.withColumnRenamed("count(PassengerId)","count") \
.orderBy("Parch") \
.toPandas()
print(pdf)
pdf = df_train.groupBy('SibSp','Survived') \
.agg({'PassengerId': 'count'}) \
.withColumnRenamed("count(PassengerId)","count") \
.orderBy("SibSp") \
.toPandas()
print(pdf)
+-------+------------------+------------------+------------------+-------------------+
|summary| Age| Pclass| SibSp| Parch|
+-------+------------------+------------------+------------------+-------------------+
| count| 714| 891| 891| 891|
| mean| 29.69911764705882| 2.308641975308642|0.5230078563411896|0.38159371492704824|
| stddev|14.526497332334035|0.8360712409770491|1.1027434322934315| 0.8060572211299488|
| min| 0.42| 1| 0| 0|
| max| 80.0| 3| 8| 6|
+-------+------------------+------------------+------------------+-------------------+
+-------+------+-----+--------+-----------------+-------------------+
|summary| Sex|Cabin|Embarked| Fare| Survived|
+-------+------+-----+--------+-----------------+-------------------+
| count| 891| 204| 889| 891| 891|
| mean| null| null| null| 32.2042079685746| 0.3838383838383838|
| stddev| null| null| null|49.69342859718089|0.48659245426485753|
| min|female| A10| C| 0.0| 0|
| max| male| T| S| 512.3292| 1|
+-------+------+-----+--------+-----------------+-------------------+
sex Survived count
0 female 1 233
1 female 0 81
2 male 0 468
3 male 1 109
Pclass Survived count
0 1 0 80
1 1 1 136
2 2 1 87
3 2 0 97
4 3 1 119
5 3 0 372
Parch Survived count
0 0 0 445
1 0 1 233
2 1 0 53
3 1 1 65
4 2 1 40
5 2 0 40
6 3 1 3
7 3 0 2
8 4 0 4
9 5 0 4
10 5 1 1
11 6 0 1
SibSp Survived count
0 0 0 398
1 0 1 210
2 1 0 97
3 1 1 112
4 2 1 13
5 2 0 15
6 3 1 4
7 3 0 12
8 4 0 15
9 4 1 3
10 5 0 5
11 8 0 7
清洗与变形
from pyspark.ml.feature import StringIndexer, VectorAssembler, VectorIndexer
df_train = spark.read.csv('hdfs://localhost:9000/titanic/train.csv',header=True,inferSchema=True).cache()
#用平均值29.699替换缺失值
df_train = df_train.fillna({'Age': round(29.699,2)})
#用登录最多的港口'S'替换缺失值
df_train = df_train.fillna({'Embarked': 'S'})
#df_train = df_train.fillna({'Cabin': 'unknown'})
#删除列
df_train = df_train.drop("Cabin")
df_train = df_train.drop("Ticket")
#StringIndexer转换器把一列标签类型的特征数值化编码
labelIndexer = StringIndexer(inputCol="Embarked", outputCol="iEmbarked")
model = labelIndexer.fit(df_train)
df_train = model.transform(df_train)
labelIndexer = StringIndexer(inputCol="Sex", outputCol="iSex")
model = labelIndexer.fit(df_train)
df_train = model.transform(df_train)
df_train.show()
# 特征选择
features = ['Pclass', 'iSex', 'Age', 'SibSp', 'Parch', 'Fare', 'iEmbarked','Survived']
train_features = df_train[features]
train_features.show()
# train_labels = df_train['Survived']
# train_labels.show()
# VectorAssembler将多个列转换成向量
df_assembler = VectorAssembler(inputCols=['Pclass', 'iSex', 'Age', 'SibSp', 'Parch', 'Fare', 'iEmbarked'], outputCol="features")
df = df_assembler.transform(train_features)
#df["features"].show()-> TypeError: 'Column' object is not callable
df["features",].show()
df["Survived",].show()
+-----------+--------+------+--------------------+------+----+-----+-----+-------+--------+---------+----+
|PassengerId|Survived|Pclass| Name| Sex| Age|SibSp|Parch| Fare|Embarked|iEmbarked|iSex|
+-----------+--------+------+--------------------+------+----+-----+-----+-------+--------+---------+----+
| 1| 0| 3|Braund, Mr. Owen ...| male|22.0| 1| 0| 7.25| S| 0.0| 0.0|
| 2| 1| 1|Cumings, Mrs. Joh...|female|38.0| 1| 0|71.2833| C| 1.0| 1.0|
| 3| 1| 3|Heikkinen, Miss. ...|female|26.0| 0| 0| 7.925| S| 0.0| 1.0|
| 4| 1| 1|Futrelle, Mrs. Ja...|female|35.0| 1| 0| 53.1| S| 0.0| 1.0|
| 5| 0| 3|Allen, Mr. Willia...| male|35.0| 0| 0| 8.05| S| 0.0| 0.0|
| 6| 0| 3| Moran, Mr. James| male|30.0| 0| 0| 8.4583| Q| 2.0| 0.0|
| 7| 0| 1|McCarthy, Mr. Tim...| male|54.0| 0| 0|51.8625| S| 0.0| 0.0|
| 8| 0| 3|Palsson, Master. ...| male| 2.0| 3| 1| 21.075| S| 0.0| 0.0|
| 9| 1| 3|Johnson, Mrs. Osc...|female|27.0| 0| 2|11.1333| S| 0.0| 1.0|
| 10| 1| 2|Nasser, Mrs. Nich...|female|14.0| 1| 0|30.0708| C| 1.0| 1.0|
| 11| 1| 3|Sandstrom, Miss. ...|female| 4.0| 1| 1| 16.7| S| 0.0| 1.0|
| 12| 1| 1|Bonnell, Miss. El...|female|58.0| 0| 0| 26.55| S| 0.0| 1.0|
| 13| 0| 3|Saundercock, Mr. ...| male|20.0| 0| 0| 8.05| S| 0.0| 0.0|
| 14| 0| 3|Andersson, Mr. An...| male|39.0| 1| 5| 31.275| S| 0.0| 0.0|
| 15| 0| 3|Vestrom, Miss. Hu...|female|14.0| 0| 0| 7.8542| S| 0.0| 1.0|
| 16| 1| 2|Hewlett, Mrs. (Ma...|female|55.0| 0| 0| 16.0| S| 0.0| 1.0|
| 17| 0| 3|Rice, Master. Eugene| male| 2.0| 4| 1| 29.125| Q| 2.0| 0.0|
| 18| 1| 2|Williams, Mr. Cha...| male|30.0| 0| 0| 13.0| S| 0.0| 0.0|
| 19| 0| 3|Vander Planke, Mr...|female|31.0| 1| 0| 18.0| S| 0.0| 1.0|
| 20| 1| 3|Masselmani, Mrs. ...|female|30.0| 0| 0| 7.225| C| 1.0| 1.0|
+-----------+--------+------+--------------------+------+----+-----+-----+-------+--------+---------+----+
only showing top 20 rows
+------+----+----+-----+-----+-------+---------+--------+
|Pclass|iSex| Age|SibSp|Parch| Fare|iEmbarked|Survived|
+------+----+----+-----+-----+-------+---------+--------+
| 3| 0.0|22.0| 1| 0| 7.25| 0.0| 0|
| 1| 1.0|38.0| 1| 0|71.2833| 1.0| 1|
| 3| 1.0|26.0| 0| 0| 7.925| 0.0| 1|
| 1| 1.0|35.0| 1| 0| 53.1| 0.0| 1|
| 3| 0.0|35.0| 0| 0| 8.05| 0.0| 0|
| 3| 0.0|30.0| 0| 0| 8.4583| 2.0| 0|
| 1| 0.0|54.0| 0| 0|51.8625| 0.0| 0|
| 3| 0.0| 2.0| 3| 1| 21.075| 0.0| 0|
| 3| 1.0|27.0| 0| 2|11.1333| 0.0| 1|
| 2| 1.0|14.0| 1| 0|30.0708| 1.0| 1|
| 3| 1.0| 4.0| 1| 1| 16.7| 0.0| 1|
| 1| 1.0|58.0| 0| 0| 26.55| 0.0| 1|
| 3| 0.0|20.0| 0| 0| 8.05| 0.0| 0|
| 3| 0.0|39.0| 1| 5| 31.275| 0.0| 0|
| 3| 1.0|14.0| 0| 0| 7.8542| 0.0| 0|
| 2| 1.0|55.0| 0| 0| 16.0| 0.0| 1|
| 3| 0.0| 2.0| 4| 1| 29.125| 2.0| 0|
| 2| 0.0|30.0| 0| 0| 13.0| 0.0| 1|
| 3| 1.0|31.0| 1| 0| 18.0| 0.0| 0|
| 3| 1.0|30.0| 0| 0| 7.225| 1.0| 1|
+------+----+----+-----+-----+-------+---------+--------+
only showing top 20 rows
+--------------------+
| features|
+--------------------+
|[3.0,0.0,22.0,1.0...|
|[1.0,1.0,38.0,1.0...|
|[3.0,1.0,26.0,0.0...|
|[1.0,1.0,35.0,1.0...|
|(7,[0,2,5],[3.0,3...|
|[3.0,0.0,30.0,0.0...|
|(7,[0,2,5],[1.0,5...|
|[3.0,0.0,2.0,3.0,...|
|[3.0,1.0,27.0,0.0...|
|[2.0,1.0,14.0,1.0...|
|[3.0,1.0,4.0,1.0,...|
|[1.0,1.0,58.0,0.0...|
|(7,[0,2,5],[3.0,2...|
|[3.0,0.0,39.0,1.0...|
|[3.0,1.0,14.0,0.0...|
|[2.0,1.0,55.0,0.0...|
|[3.0,0.0,2.0,4.0,...|
|(7,[0,2,5],[2.0,3...|
|[3.0,1.0,31.0,1.0...|
|[3.0,1.0,30.0,0.0...|
+--------------------+
only showing top 20 rows
+--------+
|Survived|
+--------+
| 0|
| 1|
| 1|
| 1|
| 0|
| 0|
| 0|
| 0|
| 1|
| 1|
| 1|
| 1|
| 0|
| 0|
| 0|
| 1|
| 0|
| 1|
| 0|
| 1|
+--------+
Pipeline
- 一个pipeline被指定成为一个阶段序列,
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
training = spark.createDataFrame([
(0, "Hello PySpark", 1.0),
(1, "Using Flink", 0.0),
(2, "PySpark 3.0", 1.0),
(3, "Test MySQL", 0.0)
], ["id", "text", "label"])
# pipeline 三个阶段: tokenizer -> hashingTF -> logR.
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
logR = LogisticRegression(maxIter=10, regParam=0.001)
pipeline = Pipeline(stages=[tokenizer, hashingTF, logR])
#训练数据上进行pipeline fit操作,产生一个model
model = pipeline.fit(training)
#############################################
#测试集
test = spark.createDataFrame([
(4, "PySpark Pipeline"),
(5, "pipeline"),
(6, "PySpark python"),
(7, "julia c#")
], ["id", "text"])
#model执行transform
prediction = model.transform(test)
#预测
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():
tid, text, prob, prediction = row
print("(%d, %s) --> prediction=%f,prob=%s" \
% (tid, text, prediction,str(prob)))
(4, PySpark Pipeline) --> prediction=1.000000,prob=[0.029796174862816768,0.9702038251371833]
(5, pipeline) --> prediction=0.000000,prob=[0.56611226449896,0.43388773550104]
(6, PySpark python) --> prediction=1.000000,prob=[0.029796174862816768,0.9702038251371833]
(7, julia c#) --> prediction=0.000000,prob=[0.56611226449896,0.43388773550104]
逻辑回归预测
- 训练
from pyspark.sql import SparkSession
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import LogisticRegression
import matplotlib.pyplot as plt
spark = SparkSession.builder.master("local[*]").appName("PySpark ML").getOrCreate()
sc = spark.sparkContext
#############################################
df_train = spark.read.csv('hdfs://localhost:9000/titanic/train.csv',header=True,inferSchema=True).cache()
df_train = df_train.fillna({'Age': round(29.699,0)})
df_train = df_train.fillna({'Fare': 36.0})
df_train = df_train.fillna({'Embarked': 'S'})
df_train = df_train.drop("Cabin")
df_train = df_train.drop("Ticket")
labelIndexer = StringIndexer(inputCol="Embarked", outputCol="iEmbarked")
model = labelIndexer.fit(df_train)
df_train = model.transform(df_train)
labelIndexer = StringIndexer(inputCol="Sex", outputCol="iSex")
model = labelIndexer.fit(df_train)
df_train = model.transform(df_train)
features = ['Pclass', 'iSex', 'Age', 'SibSp', 'Parch', 'Fare', 'iEmbarked','Survived']
train_features = df_train[features]
df_assembler = VectorAssembler(inputCols=['Pclass', 'iSex', 'Age', 'SibSp','Parch', 'Fare', 'iEmbarked'], outputCol="features")
train = df_assembler.transform(train_features)
#LogisticRegression模型
lg = LogisticRegression(labelCol='Survived')
lgModel = lg.fit(train)
#保存模型
lgModel.write().overwrite().save("hdfs://localhost:9000/model/logistic-titanic")
print("save model to hdfs://localhost:9000/model/logistic-titanic")
print("areaUnderROC: " + str(lgModel.summary.areaUnderROC))
#ROC curve is a plot of FPR against TPR
plt.figure(figsize=(5,5))
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(lgModel.summary.roc.select('FPR').collect(),
lgModel.summary.roc.select('TPR').collect())
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.show()
save model to hdfs://localhost:9000/model/logistic-titanic
areaUnderROC: 0.8569355233864868

- 预测
from pyspark.ml.classification import LogisticRegressionModel
df_test = spark.read.csv('hdfs://localhost:9000/titanic/test.csv',header=True,inferSchema=True).cache()
df_test = df_test.fillna({'Age': round(29.699,0)})
df_test = df_test.fillna({'Embarked': 'S'})
#有一个null
df_test = df_test.fillna({'Fare': 36.0})
df_test = df_test.drop("Cabin")
df_test = df_test.drop("Ticket")
#新增Survived列,默认值为0
df_test = df_test.withColumn("Survived",0 * df_test["Age"])
labelIndexer = StringIndexer(inputCol="Embarked", outputCol="iEmbarked")
model = labelIndexer.fit(df_test)
df_test = model.transform(df_test)
labelIndexer = StringIndexer(inputCol="Sex", outputCol="iSex")
model = labelIndexer.fit(df_test)
df_test = model.transform(df_test)
features = ['Pclass', 'iSex', 'Age', 'SibSp', 'Parch', 'Fare', 'iEmbarked','Survived']
test_features = df_test[features]
df_assembler = VectorAssembler(inputCols=['Pclass', 'iSex', 'Age', 'SibSp', 'Parch','Fare', 'iEmbarked'], outputCol="features")
test = df_assembler.transform(test_features)
lgModel = LogisticRegressionModel.load("hdfs://localhost:9000/model/logistic-titanic")
testSummary =lgModel.evaluate(test)
results=testSummary.predictions
results["features","rawPrediction","probability","prediction"].show()
+--------------------+--------------------+--------------------+----------+
| features| rawPrediction| probability|prediction|
+--------------------+--------------------+--------------------+----------+
|[3.0,0.0,34.5,0.0...|[1.99328605097899...|[0.88009035220072...| 0.0|
|[3.0,1.0,47.0,1.0...|[0.63374031844971...|[0.65333708360849...| 0.0|
|[2.0,0.0,62.0,0.0...|[1.97058477648159...|[0.87767391006101...| 0.0|
|(7,[0,2,5],[3.0,2...|[2.21170839644084...|[0.90129601257823...| 0.0|
|[3.0,1.0,22.0,1.0...|[-0.2919725495559...|[0.42752102300610...| 1.0|
|(7,[0,2,5],[3.0,1...|[1.68822917787023...|[0.84399113755992...| 0.0|
|[3.0,1.0,30.0,0.0...|[-0.9032166903750...|[0.28838991532794...| 1.0|
|[2.0,0.0,26.0,1.0...|[1.42490075002778...|[0.80610554993708...| 0.0|
|[3.0,1.0,18.0,0.0...|[-1.1236436862496...|[0.24533604281752...| 1.0|
|[3.0,0.0,21.0,2.0...|[2.59895227540995...|[0.93079411943702...| 0.0|
|(7,[0,2,5],[3.0,3...|[2.33390585204715...|[0.91164644844255...| 0.0|
|(7,[0,2,5],[1.0,4...|[0.69025711721974...|[0.66602412131662...| 0.0|
|[1.0,1.0,23.0,1.0...|[-2.7419887292668...|[0.06054069440361...| 1.0|
|[2.0,0.0,63.0,1.0...|[2.82767950026722...|[0.94415337330052...| 0.0|
|[1.0,1.0,47.0,1.0...|[-1.7316563679495...|[0.15037583472736...| 1.0|
|[2.0,1.0,24.0,1.0...|[-1.7197655536498...|[0.15190136429145...| 1.0|
|[2.0,0.0,35.0,0.0...|[0.88008689342827...|[0.70684022722317...| 0.0|
|[3.0,0.0,21.0,0.0...|[1.71304684487762...|[0.84723105652294...| 0.0|
|[3.0,1.0,27.0,1.0...|[-0.1717428611873...|[0.45716950894284...| 1.0|
|[3.0,1.0,45.0,0.0...|[-0.0389664987514...|[0.49025960775551...| 1.0|
+--------------------+--------------------+--------------------+----------+
决策树预测
from pyspark.ml.classification import DecisionTreeClassifier
#DecisionTree模型
dtree = DecisionTreeClassifier(labelCol="Survived", featuresCol="features")
treeModel = dtree.fit(train)
#打印treeModel
print(treeModel.toDebugString)
#对训练数据进行预测
dt_predictions = treeModel.transform(train)
dt_predictions.select("prediction", "Survived", "features").show()
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
multi_evaluator = MulticlassClassificationEvaluator(labelCol = 'Survived', metricName = 'accuracy')
print('Decision Tree Accu:', multi_evaluator.evaluate(dt_predictions))
#查看树信息
DecisionTreeClassificationModel (uid=DecisionTreeClassifier_43ab8b3b232f4c305402) of depth 5 with 49 nodes
If (feature 1 in {0.0})
If (feature 2 <= 3.0)
If (feature 3 <= 2.0)
Predict: 1.0
Else (feature 3 > 2.0)
If (feature 4 <= 1.0)
Predict: 0.0
Else (feature 4 > 1.0)
If (feature 3 <= 4.0)
Predict: 1.0
Else (feature 3 > 4.0)
Predict: 0.0
...
+----------+--------+--------------------+
|prediction|Survived| features|
+----------+--------+--------------------+
| 0.0| 0|[3.0,0.0,22.0,1.0...|
| 1.0| 1|[1.0,1.0,38.0,1.0...|
| 1.0| 1|[3.0,1.0,26.0,0.0...|
| 1.0| 1|[1.0,1.0,35.0,1.0...|
| 0.0| 0|(7,[0,2,5],[3.0,3...|
| 0.0| 0|[3.0,0.0,30.0,0.0...|
| 0.0| 0|(7,[0,2,5],[1.0,5...|
| 0.0| 0|[3.0,0.0,2.0,3.0,...|
| 1.0| 1|[3.0,1.0,27.0,0.0...|
| 1.0| 1|[2.0,1.0,14.0,1.0...|
| 1.0| 1|[3.0,1.0,4.0,1.0,...|
| 1.0| 1|[1.0,1.0,58.0,0.0...|
| 0.0| 0|(7,[0,2,5],[3.0,2...|
| 0.0| 0|[3.0,0.0,39.0,1.0...|
| 1.0| 0|[3.0,1.0,14.0,0.0...|
| 1.0| 1|[2.0,1.0,55.0,0.0...|
| 0.0| 0|[3.0,0.0,2.0,4.0,...|
| 0.0| 1|(7,[0,2,5],[2.0,3...|
| 1.0| 0|[3.0,1.0,31.0,1.0...|
| 1.0| 1|[3.0,1.0,30.0,0.0...|
+----------+--------+--------------------+
only showing top 20 rows
Decision Tree Accu: 0.8417508417508418















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









