







前言
人类可以从很少的样本中获取新的概念,比如一个小孩儿能从书中的一张图片知道什么是长颈鹿。但是对于深度学习系统来说,要学习一个新的类别需要成百上千的样本。因此对one-shot learning的研究就变得非常重要。什么是one-shot learning呢?也就是让系统能从很小一部分的带标记的样本中学习一个新类别。
深度学习一般需要较大型的数据集,当数据集变小时,会产生过拟合问题,数据增强和正则化技术虽然能够缓解过拟合,但不能完全解决这个问题。而且,就算使用数据增强和正则化,学习速度依然很慢,并且仍要基于较大的数据集,要使用SGD进行很多次的权重更新。作者认为,这主要是由于模型的参数化方面(parametric aspect),这些模型就是参数化模型(parametric model),即训练样本需要通过模型来缓慢地学习它的参数。
与参数化模型相反,非参数化模型(non-parametric model)允许新样本被快速地同化,即快速学习新样本。比如最近邻模型(nearest neighbors)不需要任何训练,它的性能取决于所选择的度量。本文的目标是将参数化模型和非参数化模型中的最佳特征结合起来,即快速获取新样本,同时对常见样本进行归纳。
本文的贡献有以下几个方面:
- 模型的提出:本文提出了Matching Nets(MN),它是一种神经网络,利用了attention和memory,从而能够快速地学习;
- 训练过程:本文的训练过程基于一个简单的机器学习原则,即测试和训练的条件必须匹配。也就是说,为了使MN能够快速学习,在训练网络时每个类别只有很少的样本,就和测试的时候一样,在测试的时候会提供一个新类别,而这个新类别中也只包含很少的样本。
- 为ImageNet和Omniglot上的one-shot learning实验设置了benchmark
模型的设计
本文提出了一种非参数化方法,用以处理one-shot learning,它基于以下两个部分:
- 本文的模型结构采用的是记忆增强的神经网络,给定一个支持集(support set) S S S,本文的模型为每个 S S S定义了一个函数 c s c_s cs(或分类器),即一个映射 S → c s ( ⋅ ) S \to c_s(\cdot) S→cs(⋅);
- 本文采用的训练策略是专门为了从支持集 S S S中进行one-shot learning
1. 模型结构
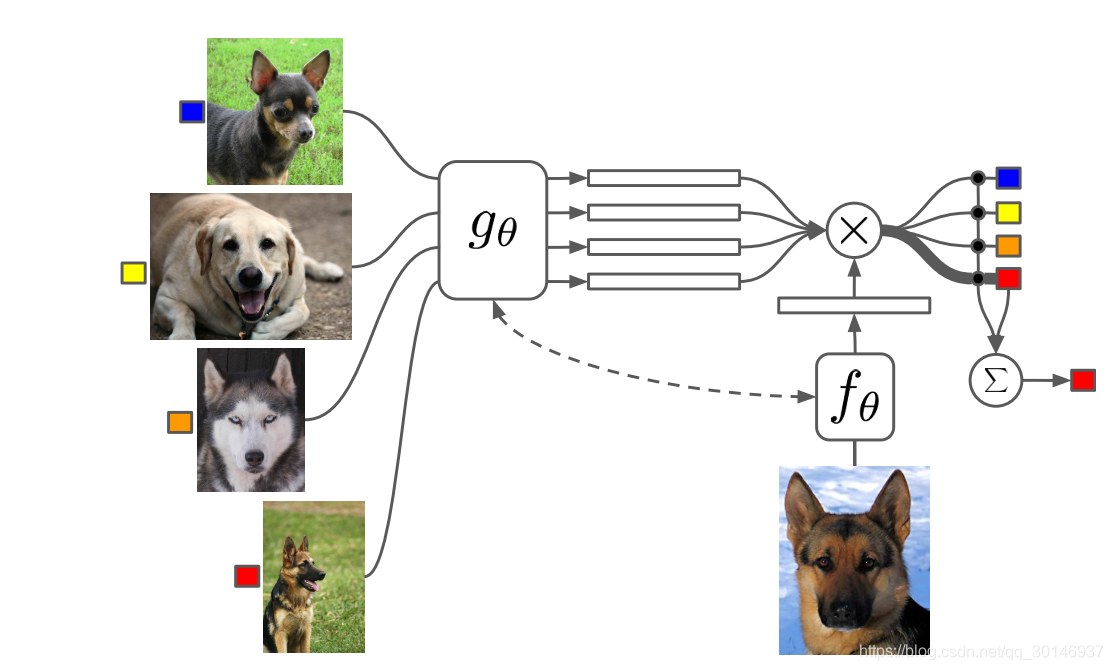
为神经网络结构附加external memory是一种有效的扩增方式,在这一类模型中,出现了一种神经注意力机制(neural attention mechanism),也就是通过访问存储有用信息的记忆矩阵(memory matrix)来处理任务。比如在seq2seq模型中,external memory用于对 P ( B ∣ A ) P(B|A) P(B∣A)进行建模,其中 A A A和 B B B都是序列;而在本文的MatchingNet中, A A A和 B B B是一个集合。
MatchingNet在训练时,能够为还没有被观察到的类别生成合理的测试标签,并且网络不需要任何的改变。具体来说就是:
- 训练过程:给定一个有 k k k个样本的支持集 S = { ( x i , y i ) } i = 1 k S=\lbrace(x_i,y_i) \rbrace^k_{i=1} S={ (xi,yi)}i=1k,定义一个 S S S到分类器 c S ( x ^ ) c_S(\hat x) cS(x^)的映射,其中 x ^ \hat x x^是测试样本, c S ( x ^ ) c_S(\hat x) cS(x^)就是输出 y ^ \hat y y^的概率分布,也就是对 x ^ \hat x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2807
2807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









