







 本文详细分析了Java中ArrayList和LinkedList的底层实现及其应用场景,探讨了HashMap的扩容过程、红黑树转换条件以及解决哈希冲突的方法。还讨论了HashSet的实现原理和线程安全问题。
本文详细分析了Java中ArrayList和LinkedList的底层实现及其应用场景,探讨了HashMap的扩容过程、红黑树转换条件以及解决哈希冲突的方法。还讨论了HashSet的实现原理和线程安全问题。
文章目录
ArrayList和LinkedList
- ArrayList是基于数组实现的,LinkedList是基于双链表实现的,因此LinkedList可以作为双向队列 ,栈。
- 因为Array是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的,可以直接返回数组中index位置的元素,因此在随机访问集合元素上有较好的性能。Array获取数据的时间复杂度是O(1),但是要插入、删除数据却是开销很大的,因为这需要移动数组中插入位置之后的的所有元素。
- LinkedList需要更多的内存,因为ArrayList的每个索引的位置是实际的数据,而LinkedList中的每个节点中存储的是实际的数据和前后节点的位置。
ArrayList底层实现
- ArrayList的默认初始化空间为10;
- 数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
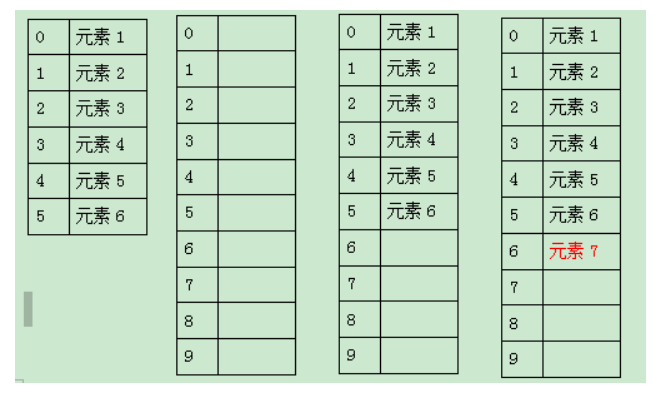
LinkList底层实现
使用场景:
(1)如果应用程序对数据有较多的随机访问,ArrayList对象要优于LinkedList对象;
( 2 ) 如果应用程序有更多的插入或者删除操作,较少的随机访问,LinkedList对象要优于ArrayList对象;
(3)不过ArrayList的插入,删除操作也不一定比LinkedList慢,如果在List靠近末尾的地方插入,那么ArrayList只需要移动较少的数据,而LinkedList则需要一直查找到列表尾部,反而耗费较多时间,这时ArrayList就比LinkedList要快。
HashMap
在JDK1.8之后,HashMap采用位桶(数组)+链表+红黑树实现,当链表长度超过一定值(默认为8)时,则会将链表结构进行调整转变为红黑树结构;当红黑树中的元素数量小于8个时,则又会将结构体进行转变为链表结构;
hashMap扩容过程
HashMap的默认初始容量为16,加载因子0.75,也就意味着当HashMap中存储的Entry数量达到16*0.75时会进行一次扩容操作;当我们通过HashMap的有参构造自定义一个初始容量时,给定的值必须是2的幂次方值;
根据加载因子规则,当 HashMap.Size > Capacity * LoadFactor 时,hashMap会进行一次扩容操作;一次扩容流程可划分为两个步骤:
- resize : HashMap会在原有的数组后再创建一个新的Entry空数组,调整后现有数组的长度为原来的2倍;
- rehash:遍历原Entry数组,把所有的Entry重新Hash到新数组。消耗性能.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









