







结合视频和笔记:https://zhuanlan.zhihu.com/p/21407711?refer=intelligentunit
函数关于每个变量的导数指明了整个表达式对于该变量的敏感程度。
反向传播的直观理解
反向传播是一个优美的局部过程。在整个计算线路图中,每个门单元都会得到一些输入并立即计算两个东西:1. 这个门的输出值,和2.其输出值关于输入值的局部梯度。门单元完成这两件事是完全独立的,它不需要知道计算线路中的其他细节。然而,一旦前向传播完毕,在反向传播的过程中,门单元门将最终获得整个网络的最终输出值在自己的输出值上的梯度。链式法则指出,门单元应该将回传的梯度乘以它对其的输入的局部梯度,从而得到整个网络的输出对该门单元的每个输入值的梯度。
模块化:Sigmoid例子
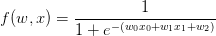
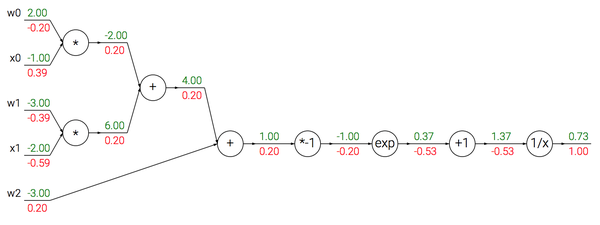
使用sigmoid激活函数的2维神经元的例子。输入是[x0, x1],可学习的权重是[w0, w1, w2]。一会儿会看见,这个神经元对输入数据做点积运算,然后其激活数据被sigmoid函数挤压到0到1之间。
在上面的例子中可以看见一个函数操作的长链条,链条上的门都对w和x的点积结果进行操作。该函数被称为sigmoid函数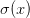
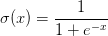
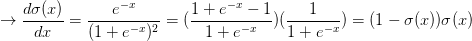
可以看到梯度计算简单了很多。举个例子,sigmoid表达式输入为1.0,则在前向传播中计算出输出为0.73。根据上面的公式,局部梯度为(1-0.73)*0.73~=0.2,和之前的计算流程比起来,现在的计算使用一个单独的简单表达式即可。因此,在实际的应用中将这些操作装进一个单独的门单元中将会非常有用。该神经元反向传播的代码实现如下:
w = [2,-3,-3] # 假设一些随机数据和权重
x = [-1, -2]
# 前向传播
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid函数
# 对神经元反向传播
ddot = (1 - f) * f # 点积变量的梯度, 使用sigmoid函数求导
dx = [w[0] * ddot, w[1] * ddot] # 回传到x
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # 回传到w
# 完成!得到输入的梯度实现提示:分段反向传播。上面的代码展示了在实际操作中,为了使反向传播过程更加简洁,把向前传播分成不同的阶段将是很有帮助的。比如我们创建了一个中间变量dot,它装着w和x的点乘结果。在反向传播的时,就可以(反向地)计算出装着w和x等的梯度的对应的变量(比如ddot,dx和dw)。
反向传播实践:分段计算

x = 3 # 例子数值
y = -4
# 前向传播
sigy = 1.0 / (1 + math.exp(-y)) # 分子中的sigmoid #(1)
num = x + sigy # 分子 #(2)
sigx = 1.0 / (1 + math.exp(-x)) # 分母中的sigmoid #(3)
xpy = x + y #(4)
xpysqr = xpy**2 #(5)
den = sigx + xpysqr # 分母 #(6)
invden = 1.0 / den #(7)
f = num * invden # 搞定! #(8)反向传播:
# 回传 f = num * invden
dnum = invden # 分子的梯度 #(8)
dinvden = num #(8)
# 回传 invden = 1.0 / den
dden = (-1.0 / (den**2)) * dinvden #(7)
# 回传 den = sigx + xpysqr
dsigx = (1) * dden #(6)
dxpysqr = (1) * dden #(6)
# 回传 xpysqr = xpy**2
dxpy = (2 * xpy) * dxpysqr #(5)
# 回传 xpy = x + y
dx = (1) * dxpy #(4)
dy = (1) * dxpy #(4)
# 回传 sigx = 1.0 / (1 + math.exp(-x))
dx += ((1 - sigx) * sigx) * dsigx # Notice += !! See notes below #(3)
# 回传 num = x + sigy
dx += (1) * dnum #(2)
dsigy = (1) * dnum #(2)
# 回传 sigy = 1.0 / (1 + math.exp(-y))
dy += ((1 - sigy) * sigy) * dsigy #(1)
# 完成! 嗷~~对前向传播变量进行缓存:在计算反向传播时,前向传播过程中得到的一些中间变量非常有用。在实际操作中,最好代码实现对于这些中间变量的缓存,这样在反向传播的时候也能用上它们。如果这样做过于困难,也可以(但是浪费计算资源)重新计算它们。
在不同分支的梯度要相加:如果变量x,y在前向传播的表达式中出现多次,那么进行反向传播的时候就要非常小心,使用+=而不是=来累计这些变量的梯度(不然就会造成覆写)。(参考上面sigmod函数)这是遵循了在微积分中的多元链式法则,该法则指出如果变量在线路中分支走向不同的部分,那么梯度在回传的时候,就应该进行累加。
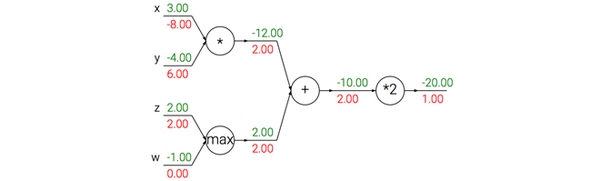
- 加法门单元把输出的梯度相等地分发给它所有的输入。
- 取最大值门单元对梯度做路由。取最大值门将梯度转给其中一个输入,这个输入是在前向传播中值最大的那个输入。
- 乘法门单元它的局部梯度就是输入值,但是是相互交换之后的,然后根据链式法则乘以输出值的梯度。
用向量化操作计算梯度
# 前向传播
W = np.random.randn(5, 10)
X = np.random.randn(10, 3)
D = W.dot(X)
# 假设我们得到了D的梯度
dD = np.random.randn(*D.shape) # 和D一样的尺寸
dW = dD.dot(X.T) #.T就是对矩阵进行转置
dX = W.T.dot(dD)














 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









