






支持向量机(SVM)是一种在分类和回归问题中广泛应用的机器学习算法。其核心目标是找到一个能够最大化不同类别数据点间隔的超平面,这个超平面被选为能够最好地分隔数据,而最靠近它的数据点被称为支持向量。SVM适用于线性和非线性问题,通过核函数将数据映射到高维空间,实现在新空间中的线性分隔。这使得SVM能够处理复杂的数据结构,例如图像和文本,取得优秀的分类效果。其优势之一是对高维数据的有效处理,尤其在需要处理大量特征的情况下表现突出。同时,SVM对小样本数据具有鲁棒性,不容易受到异常值的干扰,这使得它在现实世界的应用中更为可靠。
一、前置理论
1.最大间隔与分类
在支持向量机(SVM)中,最大间隔指的是通过寻找一个超平面,使得该超平面到最近的训练样本点的距离尽可能远。这个距离被称为间隔,是两个不同类别的训练样本中距离最近的样本点到超平面的垂直距离的最大值。通过最大化这个间隔,SVM构建了一个最宽的安全通道,确保两个类别之间有足够的空间,提高了分类的鲁棒性和泛化能力。这个超平面的选择是通过优化算法来完成的,最终实现了在处理线性可分问题时找到清晰而有力的分类边界。
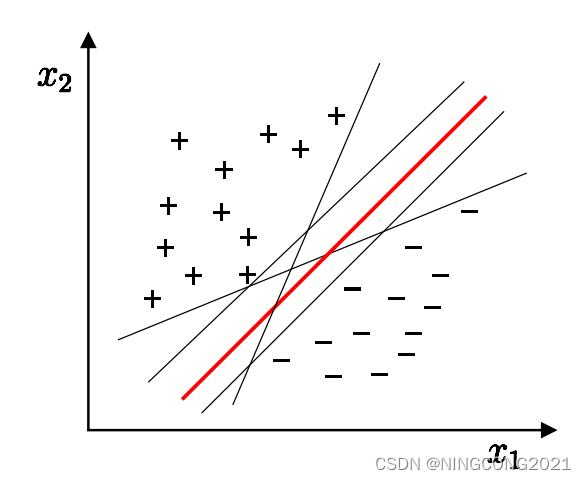
在选择分离训练样本的超平面时,SVM不仅追求最大间隔,还注重选择一个“正中间”的超平面。这种选择确保了超平面的容忍性、鲁棒性和泛化能力都得到了最大程度的提升。通过追求“正中间”的超平面,SVM考虑到了未来可能出现的新样本点,使得这个超平面在面对未见过的数据时更加稳健。这种容忍性的好处在于,即使训练样本中存在一些噪音或异常点,SVM也能够忽略它们,而不会过于依赖于训练数据的特定特征。鲁棒性的提高意味着模型对于不同数据分布的适应能力更强,不容易受到局部变化的影响。而泛化能力的增强使得SVM在处理新的、未知的数据时表现更为出色,从而更具有实际应用的可靠性。

2.对偶问题
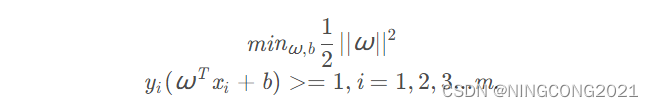
对于最大间隔与分类问题,最后的问题可转化为求解w,b使得上式成立

根据拉格朗日乘子法:就是求函数f(x1,x2,…)在g(x1,x2,…)=0的约束条件下的极值的方法。其主要思想是将约束条件函数与原函数联系到一起,使能配成与变量数量相等的等式方程,从而求出得到原函数极值的各个变量的解。即可以求得:

通过对偶问题的转化,引入了拉格朗日乘子,并通过最大化一个关于这些乘子的函数,将原始问题中的约束条件纳入优化目标中。最终,通过对偶问题的最小化,可以得到与原始问题等价的解。
SMO(Sequential Minimal Optimization)算法是一种用于训练支持向量机(SVM)的优化算法,。其核心思想是将大规模优化问题分解成多个小规模子问题,并通过解析方法直接求解每个子问题,以加速整个优化过程。SMO的基本步骤包括参数初始化、选择变量、固定其他变量、解子问题、更新阈值,以及检查收敛条件。通过这种分解策略,SMO避免了对整个问题进行全局优化,提高了在大规模数据集上的效率。尤其在处理非线性分类问题时,SMO可以通过核函数灵活应用。



3.核函数
核函数的出现旨在处理那些在原始特征空间中线性不可分的问题,即无法通过一个线性超平面来完美分割的数据。核函数通过将原始特征映射到一个高维空间,使得在新的空间中数据变得线性可分。这种映射使得支持向量机(SVM)在高维空间中能够更灵活地找到一个线性超平面,从而在原始特征空间中解决非线性问题。
核函数的作用在于计算两个样本点在高维空间中的内积,而无需显式计算映射后的数据。这节省了计算成本,使得SVM在高维空间中的计算变得可行。常用的核函数包括线性核、多项式核、径向基函数(RBF)核等,它们分别对应不同的特征映射方式。
核支持向量机(Kernel Support Vector Machine)是指在支持向量机的基础上使用核函数的一种扩展。通过核函数,SVM可以处理非线性问题,将数据映射到高维空间,然后在该空间中寻找一个线性超平面进行分类。这种方法在实践中取得了很大的成功,因为它不仅可以解决线性可分问题,还能够处理更为复杂的非线性情况。
核支持向量机在机器学习中被广泛应用,特别是在图像识别、文本分类等领域,其中数据通常具有高度复杂的非线性结构。通过核函数,SVM能够适应这些复杂性,提高分类器的性能和泛化能力
几种常见的核函数:
线性核函数(Linear Kernel):
![]()
线性核函数对原始特征进行线性组合,适用于线性可分的情况。虽然它不引入额外的复杂性,但在处理非线性问题上有限制。
多项式核函数(Polynomial Kernel):
![]()
多项式核函数引入了多项式特征映射,其中d是多项式的次数,c是常数。它可以处理一定程度的非线性问题,通过调整次数d可以增加模型的复杂性。
径向基函数核(RBF Kernel / Gaussian Kernel):
![]()
RBF核函数基于样本点之间的距离,将数据映射到无限维的空间。它在处理非线性问题上非常强大,通过调整参数σ(标准差)可以控制映射的宽度。
Sigmoid核函数:
![]()
4.软间隔和正则化
软间隔(Soft Margin)和正则化(Regularization)是支持向量机(SVM)中用于处理数据集中噪声或异常点的概念。
-
软间隔: 软间隔允许在训练数据中存在一些分类错误或离群点,而不是要求所有样本都被正确分类。软间隔的目标是在保持尽可能大的间隔的同时,容忍一些错误。这对于处理非线性可分或包含噪声的数据集特别有用。软间隔的优化问题通常通过引入惩罚项来实现,即在最小化目标函数时,除了最大化间隔外,还要最小化分类错误的惩罚。
-
正则化: 正则化是一种通过在优化问题中引入额外的惩罚来防止过拟合的技术。在SVM中,正则化通常通过在优化目标中添加权重向量的L1或L2范数来实现。正则化的目标是防止模型在训练集上过度拟合,使其更具有泛化能力。正则化项的引入使得模型更趋向于选择简单的解,从而避免过分依赖训练数据的细节。
优化目标:

其中C > 0 C>0C>0是一个常数,为惩罚参数。当C CC为无穷大时,会迫使所有样本满足约束。
L0/1是0/1损失函数:
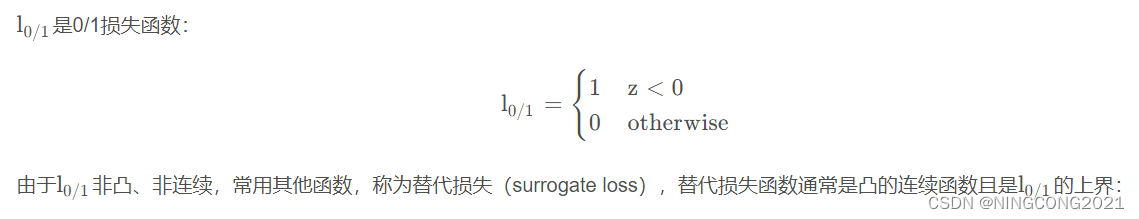
采用hinger loss,则

软间隔和正则化都是为了增加SVM模型的鲁棒性和泛化能力。软间隔通过容忍一定程度的分类错误来适应噪声,而正则化通过对模型复杂度的惩罚来防止过拟合。
二、支持向量回归
支持向量回归(SVR)是一种机器学习算法,专门用于处理回归问题。与传统回归方法不同,SVR采用支持向量机(SVM)的理念,将回归问题视为支持向量的集合求解问题。
SVR的目标在于找到一个函数,将输入数据映射到高维空间,并在该空间中找到一个超平面,使得输入数据在该超平面上的投影与目标值的差异最小化。这个超平面被称为回归函数,用于预测新输入数据对应的目标值。
关键概念包括支持向量、间隔和核函数:
- 支持向量:在SVR中,支持向量是训练数据中与回归函数最相关的数据点,位于超平面附近,对回归函数的确定至关重要。
- 间隔:SVR通过最大化间隔来确定回归函数,即从超平面到最近支持向量的距离。这有助于提高回归函数的泛化能力。
- 核函数:SVR利用核函数将输入数据映射到高维空间,以更容易分离数据。线性核、多项式核和径向基函数(RBF)核是常用的核函数类型。
SVR的求解过程可概括为以下几个步骤:
- 数据预处理:对原始数据进行归一化或标准化,消除不同特征之间的量纲差异。
- 核函数选择:选择适当的核函数,并确定其参数,依赖于具体问题和数据集的特性。
- 建立模型:利用训练数据构建SVR模型,需要确定超参数C和ε,分别控制模型的容错程度和拟合精度。
- 模型训练:通过解决优化问题,找到最大化间隔的超平面和支持向量,可使用优化算法(如序列最小最优化算法)来实现。
- 预测:利用训练好的模型对新输入数据进行预测,通过核函数映射到高维空间,确定预测值。
三、代码分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
#这里我们创建了100个数据点,并将它们分为了2类
x,y=make_blobs(n_samples=100,n_features=2,centers=2,cluster_std=1.0,center_box=(-10.0,10.0),shuffle=True,random_state=6)
plt.figure(1,figsize=(10,7),dpi=450)#画布
for c,location in zip([0.01,0.05,1,50],[221,222,223,224]):
#构建一个内核为线性的支持向量机模型
clf=svm.SVC(kernel="linear",C=c)
clf.fit(x,y)
ax = plt.subplot(location)
ax.set_title('C='+str(c))
ax.scatter(x[:,0],x[:,1],c=y,s=30,cmap=plt.cm.Paired)
#plt.scatter(x[:,0],x[:,1],c=y,s=30,cmap=plt.cm.Paired)
#建立图形坐标
ax=plt.gca()#坐标轴移动函数
xlim=ax.get_xlim()#获取数据点x坐标的最大值和最小值
ylim=ax.get_ylim()#获取数据点y坐标的最大值和最小值
#根据坐标轴生成等差数列(这里是对参数进行网格搜索)
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=clf.decision_function(xy).reshape(XX.shape)
#画出分类的边界
ax.contour(XX,YY,Z,colors='K',levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],s=100,linewidths=1,facecolors="none")
plt.show()
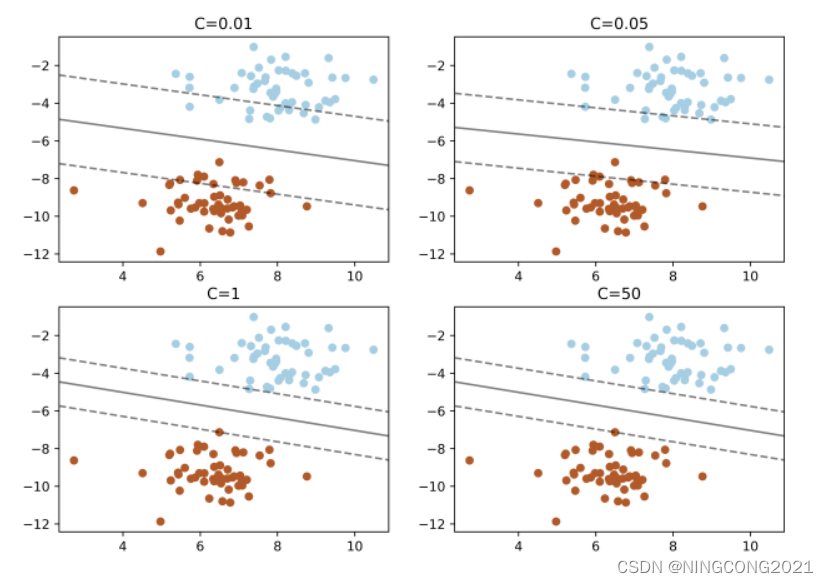
这段代码使用支持向量机(SVM)对生成的二维数据进行分类,通过不同的正则化参数C值展示了不同的决策边界和支持向量。首先,生成100个二维随机数据点,然后循环遍历不同的C值,构建线性核的支持向量机模型,并在一个大的画布上创建四个子图,每个子图展示一个不同C值的决策边界。在每个子图中,通过散点图显示生成的数据点,不同类别用不同颜色表示。接着,计算决策函数的值,通过等高线图显示决策边界,并用散点图标示支持向量。
运行结果:
代码分析:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from matplotlib.colors import ListedColormap
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data[:, [0, 2]] # 选取两个特征
y = iris.target
# 数据可视化
sns.pairplot(data=pd.DataFrame(data=np.c_[X, y], columns=iris.feature_names + ['target']), diag_kind='hist', hue='target')
plt.show()
# 绘制决策边界
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1], c='black', alpha=0.8, linewidths=1, marker='o', s=10, label='test set')
# 绘制不同核函数的决策边界
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
for ax, kernel in zip(axes.flatten(), ['linear', 'poly', 'rbf', 'sigmoid']):
svm = SVC(kernel=kernel, random_state=0, gamma=0.3, C=1.0 if kernel != 'poly' else 100)
svm.fit(X, y)
plot_decision_regions(X, y, classifier=svm, test_idx=range(105, 150))
ax.set_title(kernel.capitalize())
plt.show()
这份代码加载鸢尾花数据集,选择其中的两个特征进行可视化。通过seaborn的pairplot函数,以散点图矩阵的形式展示了特征之间的关系,并按目标变量的不同类别用不同颜色标示。接下来,通过支持向量机(SVM)实现了不同核函数下的决策边界的绘制。每个子图代表一个不同核函数的SVM模型,通过contourf方法在图中绘制了等高线,表示不同类别的决策边界。
运行结果

四、总结
在学习支持向量机(SVM)的过程中,我深入了解了其核心理论和关键概念。理论基础包括最大间隔与分类、对偶问题的引入,为了处理非线性问题,学习了核函数的应用,其中线性核、多项式核、径向基函数(RBF)核等起到了关键作用。软间隔和正则化的概念进一步提高了SVM模型的鲁棒性和泛化能力。此外,支持向量回归(SVR)作为SVM在回归问题上的应用,通过构建回归函数实现对目标值的预测,加深了我对SVM的理解。通过实际代码示例,我学到了如何在分类和回归任务中应用SVM,包括调整参数、选择不同核函数以及绘制决策边界等步骤。这一系列学习内容为我提供了全面的SVM知识体系,使我能够更自信地理解和应用这一强大的机器学习算法。支持向量机不仅是一个理论丰富的模型,同时在实践中展现了其在处理各种数据类型和问题上的灵活性和性能。
















 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











