






目录
shardingsphere文档地址:
https://shardingsphere.apache.org/document/current/cn/quick-start/
在线yml转换工具 在线yaml转properties-在线properties转yaml-ToYaml.com
1.maven依赖
<!-- druid 数据源,一定不能用druid-spring-boot-starter -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<!--一定不能引入dynamic-datasource-spring-boot-starter包-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3</version>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.0.0-beta</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-namespace</artifactId>
<version>5.0.0-beta</version>
</dependency>
注意 dynamic-datasource相关包不要引入,会冲突
2.配置文件
2.1mybatis-plus配置
#mybatis-plus配置
mybatis-plus:
mapper-locations: classpath:/mybatis/mapper/*.xml
#数据库实体类的包全路径,方便在mapper.xml中不许使用实体类的全路径,写类名就行(不区分大小写)
type-aliases-package: com.example.dto
configuration:
#sql日志打印
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
#开启驼峰命名匹配
map-underscore-to-camel-case: true
global-config:
db-config:
#逻辑删除
logic-delete-value: 0
logic-not-delete-value: 1
logic-delete-field: deleted2.2 数据源配置
spring:
shardingsphere:
props:
sql:
show:
true
datasource:
names: ds0,ds1,slave,master
enabled: true
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test01?useUnicode=true&serverTimezone=GMT%2B8
username: root
password:
initialSize: 5
minIdle: 10
maxActive: 50
maxWait: 6000
timeBetweenEvictionRunsMillis: 300000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
validationQueryTimeout: 10
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test02?useUnicode=true&serverTimezone=GMT%2B8
username: root
password:
initialSize: 5
minIdle: 10
maxActive: 50
maxWait: 6000
timeBetweenEvictionRunsMillis: 300000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
validationQueryTimeout: 10
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test-slave?useUnicode=true&serverTimezone=GMT%2B8
username: root
password:
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test-master?useUnicode=true&serverTimezone=GMT%2B8
username: root
password: 其中ds0,ds1是分库分表数据源,master,slave是读写分离数据源
2.3 读写分离配置
rules:
readwrite-splitting:
data-sources:
master-slave:
write-data-source-name: master
read-data-source-names:
- slave
load-balancer-name: roundRobin # 负载均衡算法名称
load-balancers:
roundRobin:
type: ROUND_ROBIN # 一共两种一种是 RANDOM(随机),一种是 ROUND_ROBIN(轮询)2.4 分库分表配置
# 分片规则
rules:
sharding:
sharding-algorithms:
database-inline:
props:
algorithm-expression: ds$->{user_id % 2}
type: INLINE
table-inline:
props:
algorithm-expression: user_$->{(user_id % 5) % 2}
type: INLINE
tables:
user:
actual-data-nodes: ds$->{0..1}.user_$->{0..1}
database-strategy:
standard:
sharding-algorithm-name: database-inline
sharding-column: user_id
table-strategy:
standard:
sharding-algorithm-name: table-inline
sharding-column: user_iduser表 分2库,每个库分表2个表进行测试
3.测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class TestCut {
@Resource
private IUserMapper userDao;
@Resource
private IUserInfoMapper userInfoMapper;
@Test
public void test() {
// 测试分库分表
for (int i = 1; i < 50; i++) {
User user = new User();
user.setUserId(i);
user.setUserNickName("");
user.setUserHead("head");
user.setUserPassword("1");
user.setCreateTime(new Date());
user.setUpdateTime(new Date());
userDao.insert(user);
}
// 测试读写分离
QueryWrapper<UserInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.lambda().eq(UserInfo::getUserId, 2);
userInfoMapper.selectOne(queryWrapper);
UserInfo user = new UserInfo();
user.setUserId(50);
user.setUserNickName("");
user.setUserHead("head");
user.setUserPassword("1");
user.setCreateTime(new Date());
user.setUpdateTime(new Date());
userInfoMapper.insert(user);
}
}数据库:
4.druid监控配置
页面配置
@Configuration
public class DruidConfig {
@Bean
ServletRegistrationBean regisDruid() {
//固定写法,配置访问路径
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
//配置登录信息,固定写法
HashMap<String, String> initParams = new HashMap<>();
//账号和密码的key是固定的
initParams.put("loginUsername", "admin");
initParams.put("loginPassword", "123456");
//允许谁可以访问
initParams.put("allow", "");
//禁止谁访问 initParams.put("huangcc","192.168.3.12");
//设置初始化参数
bean.setInitParameters(initParams);
return bean;
}
}监控配置
#配置监控统计拦截的filters,去掉后监控界面sql无法统计, 'wall'用于防火墙
filters: stat
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500启动项目
访问监控页http://localhost:8080/druid/index.html
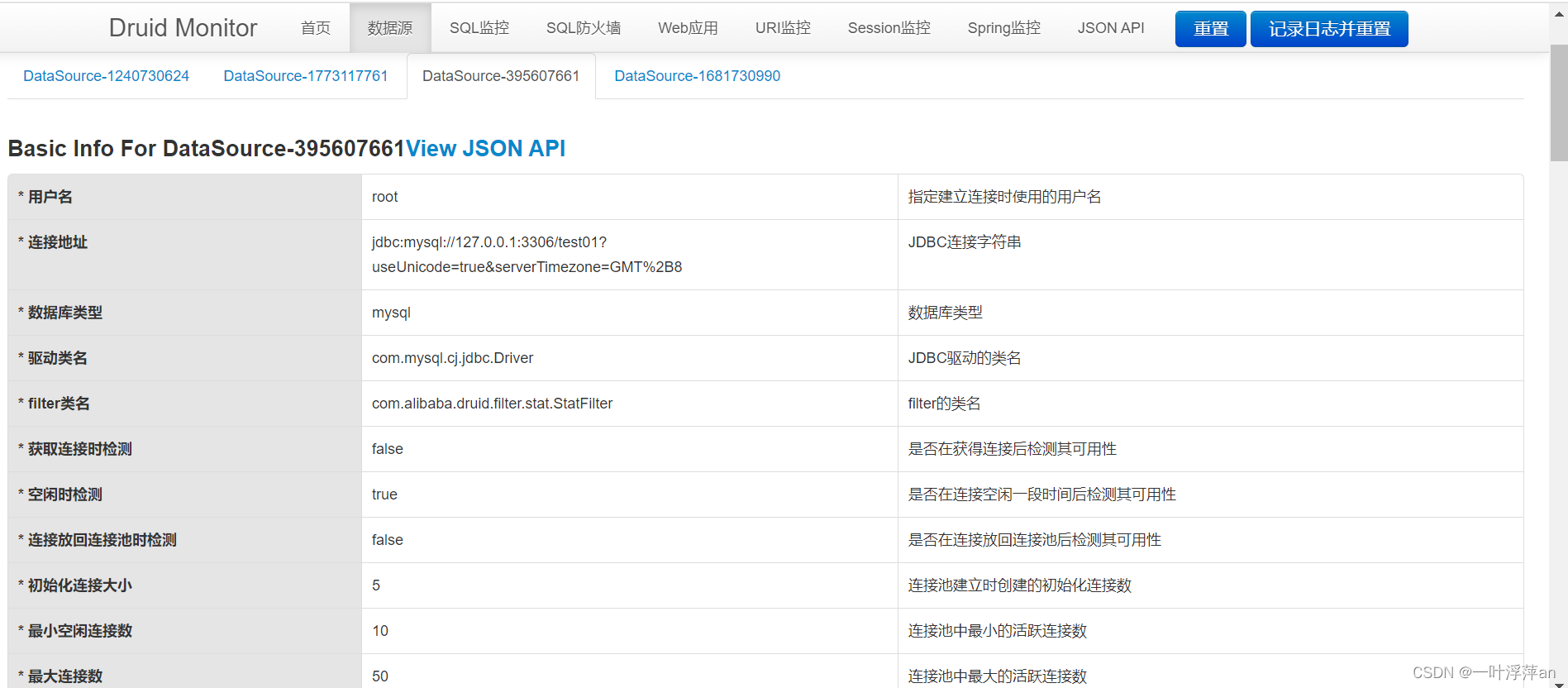
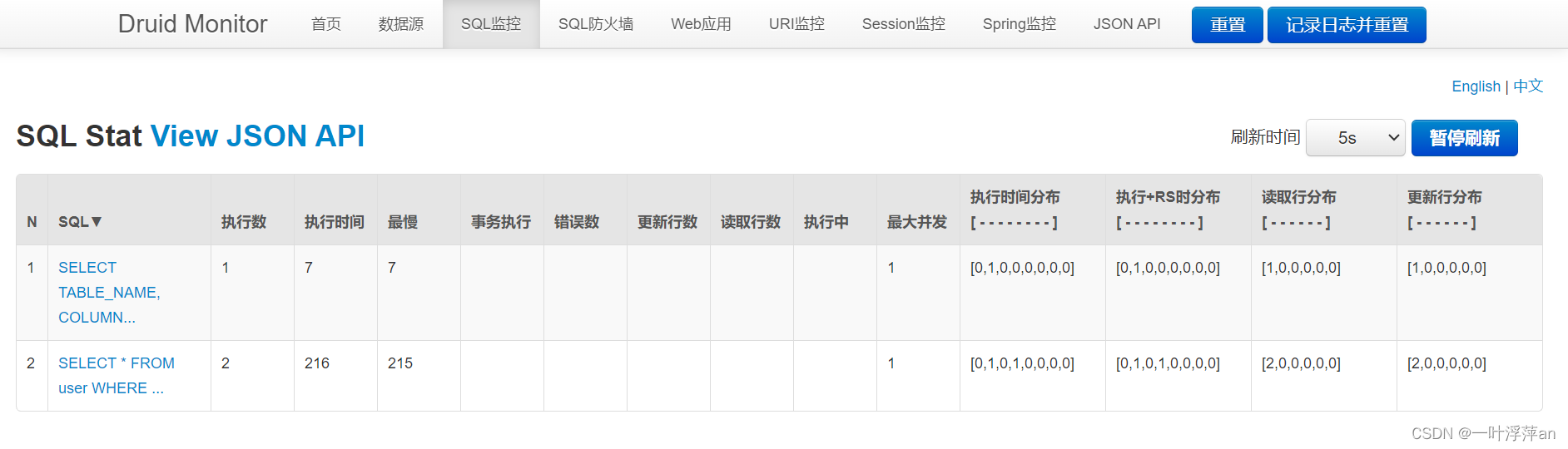 至此就配置好了
至此就配置好了
5.遇到的问题
- jar版本冲突,一定要注意兼容性
- 分库分表的键的列在数据库要是主键,否则会失效
- 配置中的一些自定义属性名最好避免用下划线,'_',可能会出现问题
- 读写分离和分库分表用的不同的库并且是不同表,注意配置时datasource和sharding是同一级别















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









