







目录
导读:在高并发互联网应用中,数据库性能瓶颈如何突破?读写分离作为分布式数据库设计的基础模式,提供了一条经过验证的解决路径。本文深入剖析读写分离的核心价值、技术原理与实现策略,从MySQL主从复制机制到三种主流实现方案的对比,为您呈现一份完整的技术全景。您是否好奇在读写比例高达100:1的业务场景下,系统性能如何提升?面对主从延迟这一读写分离架构中的典型挑战,又有哪些有效的应对策略?无论您是初探分布式数据库还是寻求架构优化的技术人员,这篇文章都将为您提供系统化的知识框架和可落地的实践指南。
一、引言:读写分离概念解析
1. 读写分离的定义
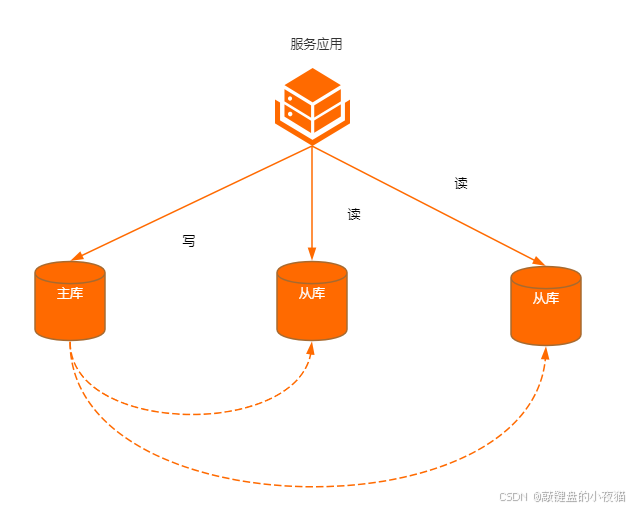
在当今高并发的互联网应用环境中,数据库往往成为系统性能的瓶颈。读写分离是一种通过将数据库读操作和写操作分散到不同数据库实例上执行的架构策略。具体来说:
- 读操作:指的是查询数据的操作(如SELECT语句),通常路由到从库(Slave)执行
- 写操作:包括数据的创建、更新和删除(如INSERT、UPDATE、DELETE语句),仅在主库(Master)上执行
读写分离最初起源于大型网站架构演进过程中,是数据库扩展的第一步策略,也是分布式数据库设计中最基础的模式之一。随着移动互联网和云计算的发展,这一技术已经成为构建高性能应用不可或缺的架构组件。
2. 核心价值与优势
读写分离的引入为系统带来了多方面的收益:
- 性能提升:对于读多写少的业务场景(通常占互联网应用的80%以上),可以显著提高查询性能。在实际应用中,许多系统的读写比例高达10:1甚至100:1,通过读写分离可将读负载分散到多个从库,有效降低主库压力。
- 可扩展性:系统可以根据读请求量的增长,按需横向扩展从库数量。比如,在电商促销活动期间,可以临时增加从库以应对流量高峰,活动结束后再缩减资源,既保证了服务质量又优化了成本。
- 高可用性:主从复制架构提供了自然的数据备份机制。当主库发生故障时,可以快速提升某个从库为新的主库,将系统恢复时间从小时级缩短到分钟级,大幅提升系统的总体可用性。
- 负载均衡:通过在多个从库之间智能分配读请求,可以实现真正的负载均衡,避免单点压力,使整个系统的资源利用更加均衡,响应速度更稳定。实践表明,良好的负载均衡策略可以使系统吞吐量提升30%以上。
二、技术基础:MySQL主从复制
1. 主从复制原理
MySQL主从复制是读写分离的技术基础,其核心是保证主库上的数据变更能可靠地传播到从库。理解这一机制对实现稳定的读写分离架构至关重要。
Mysql主从复制过程后续将有专门章节讲解,敬请期待~
- 主库(Master)与从库(Slave)角色划分 主库负责处理所有写操作,记录变更到二进制日志(binary log)中;从库则负责接收主库的变更,并将这些变更重放到自身数据上。这种"一主多从"的模式是MySQL生态中最常见的分布式部署形式,已经在各类规模的系统中得到了验证。
- 数据同步机制详解 MySQL的主从复制经历了三个演进阶段:
- 基于语句的复制(SBR, Statement-Based Replication):主库记录执行的SQL语句,从库重新执行相同的SQL
- 基于行的复制(RBR, Row-Based Replication):主库记录实际数据行的变化,从库直接应用这些变化
- 混合复制(MBR, Mixed-Based Replication):根据SQL类型自动选择使用SBR或RBR
2. 部署模式
不同的业务场景需要不同的主从复制部署模式:
- 一主一从架构 最简单的部署形式,一个主库对应一个从库。适用于小型应用或早期创业项目,实现简单,维护成本低。这种架构能提供基本的读写分离和高可用保障,但扩展性有限。
- 一主多从架构 一个主库连接多个从库,是最常见的生产环境部署形式。适用于读请求量大的场景,通过增加从库数量,线性提升系统的查询能力。例如,电商平台的商品详情页、内容平台的热点文章等,都可以通过这种架构有效应对高并发读取。
- 级联复制架构 为了减轻主库负担,可以设置中间从库,由这些中间从库再向下一级从库同步数据。这种架构在跨地域部署中尤为有用,可以实现就近读取,降低网络延迟,提升用户体验。
每种部署模式都有其适用场景和优缺点,选择合适的架构需要根据具体业务特点、性能需求和资源限制综合考量。
三、实现策略:读写流量分流方案
1. 服务层面准备
在代码实现读写分离之前,首先需要在服务设计层面做好准备工作:
- 接口职责划分:读服务与写服务 遵循单一职责原则,将读写操作在接口设计阶段就明确分开。例如:
// 读服务接口 public interface UserReadService { User getUserById(Long id); List<User> getUsersByDepartment(String department); // 其他读操作... } // 写服务接口 public interface UserWriteService { Long createUser(User user); boolean updateUserProfile(User user); // 其他写操作... } - ReadService与WriteService的职责界定 明确定义读写服务的边界,避免职责混淆。ReadService只负责数据查询,不应包含任何修改操作;WriteService负责数据变更,并在必要时协调事务。这种清晰的职责划分不仅有利于读写分离的实现,也提升了代码的可维护性和可测试性。
2. 代码分流实现
代码分流是最直接的读写分离实现方式,通过在应用代码中配置多个数据源并根据操作类型动态切换:
- 多数据源配置 在Spring应用中,配置主从两个数据源:
@Configuration public class DataSourceConfig { @Bean @Primary public DataSource primaryDataSource() { // 配置主数据源 return DataSourceBuilder.create() .url("jdbc:mysql://master_db:3306/mydb") .username("master_user") .password("master_pass") .driverClassName("com.mysql.cj.jdbc.Driver") .build(); } @Bean public DataSource replicaDataSource() { // 配置从数据源 return DataSourceBuilder.create() .url("jdbc:mysql://replica_db:3306/mydb") .username("replica_user") .password("replica_pass") .driverClassName("com.mysql.cj.jdbc.Driver") .build(); } } - 动态数据源实现 创建一个拓展AbstractRoutingDataSource的动态数据源类,根据上下文决定使用哪个数据源:
public class DynamicDataSource extends AbstractRoutingDataSource { @Override protected Object determineCurrentLookupKey() { // 根据当前上下文决定使用哪个数据源 return DbContextHolder.getDbType(); } } - AOP拦截与路由 使用AOP在方法调用前动态切换数据源:
@Aspect @Component public class DataSourceAspect { @Before("execution(* com.example.repository.*.find*(..)) || execution(* com.example.repository.*.get*(..))") public void setReadDataSourceType() { DbContextHolder.setDbType(DbType.SLAVE); } @Before("execution(* com.example.repository.*.insert*(..)) || execution(* com.example.repository.*.update*(..))") public void setWriteDataSourceType() { DbContextHolder.setDbType(DbType.MASTER); } @After("execution(* com.example.repository.*.*(..))") public void clearDataSourceType() { DbContextHolder.clearDbType(); } } - 优势:实现简单,灵活性高 代码分流方案的主要优点在于实现简单直接,开发团队可以完全控制路由逻辑,可以根据业务需要实现复杂的路由策略,例如根据查询复杂度、数据敏感度或一致性要求选择不同的从库。 但这种方案也有缺点,主要是对代码有侵入性,需要修改已有代码逻辑,且容易出现人为维护不当导致的问题。
3. 中间件方案

中间件方案利用专门的数据库中间件实现读写分离,无需大量修改应用代码:
- Sharding-JDBC、TDDL等中间件介绍
- Sharding-JDBC:Apache ShardingSphere的核心项目,提供轻量级Java框架,在JDBC层面上实现数据分片、读写分离等分布式数据库功能。
- TDDL:淘宝分布式数据层(Taobao Distributed Data Layer),阿里巴巴内部使用的数据库中间件,提供分库分表、读写分离、动态数据源配置等功能。
- MyCat:开源的数据库中间件,提供MySQL数据库的分布式、读写分离和负载均衡功能。
- SQL语义分析与路由原理 这些中间件通常通过拦截SQL请求,分析SQL语句的语义(SELECT vs INSERT/UPDATE/DELETE),然后将读请求路由到从库,将写请求路由到主库。例如,ShardingSphere的SQL解析引擎会将SQL转换为抽象语法树(AST),识别出SQL类型后应用相应的路由策略。
- 优势:可靠性高,侵入性低 中间件方案的最大优点是对应用代码的侵入性较低,大多只需要修改数据源配置,而不需要修改业务逻辑。同时,成熟的中间件经过大量实际应用验证,提供了完善的配置选项和监控能力,可靠性较高。 以ShardingSphere-JDBC为例,只需要简单的配置就可以启用读写分离:
spring: shardingsphere: datasource: names: master,slave0,slave1 master: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.cj.jdbc.Driver jdbc-url: jdbc:mysql://master:3306/demo username: root password: root slave0: # 从库0配置 slave1: # 从库1配置 rules: readwrite-splitting: data-sources: myds: type: Static props: write-data-source-name: master read-data-source-names: slave0,slave1 load-balancer-name: round_robin load-balancers: round_robin: type: ROUND_ROBIN
4. 代理模式
代理模式是在应用和数据库之间部署独立的代理服务,对应用透明地实现读写分离:
- 数据库代理原理 数据库代理作为独立的服务部署,接收应用的所有数据库请求,解析SQL,并将请求转发到适当的数据库实例。从应用角度看,代理就是一个单一的数据库服务,无需感知后端的主从架构。
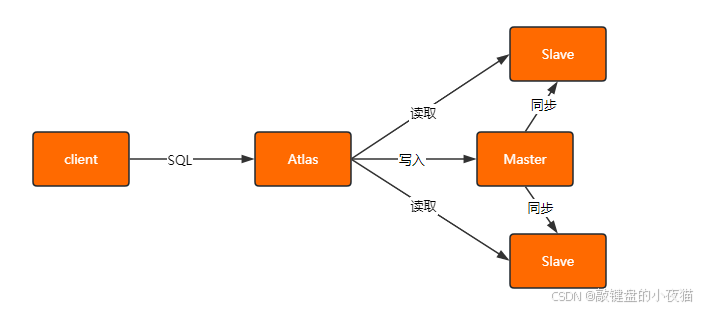
- Atlas实现案例 Atlas是奇虎360开发的MySQL数据库中间层项目,具有读写分离、负载均衡、失败迁移等功能。它的工作流程如下:
- 应用程序连接到Atlas代理
- Atlas接收SQL请求,解析SQL类型
- 对于写请求,Atlas将其转发到主库
- 对于读请求,Atlas根据配置的负载均衡策略,选择一个从库处理
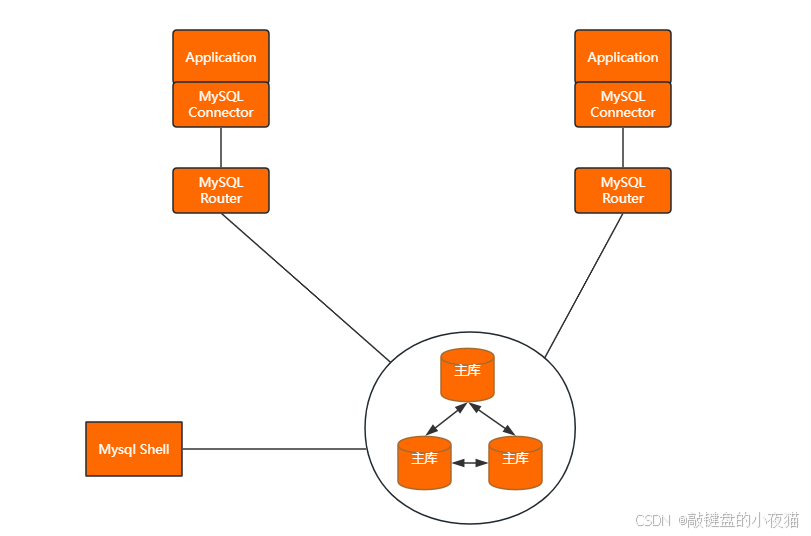
- MySQL Router的新功能 MySQL 8.2版本引入了内置的透明读写分离功能,通过MySQL Router实现:
[routing:primary]
bind_address=0.0.0.0
bind_port=6446
destinations=primary.example.com:3306
routing_strategy=first-available
[routing:secondary]
bind_address=0.0.0.0
bind_port=6447
destinations=secondary1.example.com:3306,secondary2.example.com:3306
routing_strategy=round-robin-with-fallback- 优势:对应用透明,配置灵活 代理模式的最大优势是对应用完全透明,不需要修改任何应用代码,甚至不需要修改连接串。同时,代理服务可以独立于应用升级和维护,便于运维团队集中管理数据库路由策略。 此外,一些高级代理如ProxySQL还提供了查询缓存、连接池复用、SQL防火墙等增强功能,可以进一步提升系统性能和安全性。
四、方案选择与最佳实践
1. 三种方案比较
选择适合的读写分离方案需要从多个维度进行评估:
- 可靠性对比
方案 可靠性 说明 代码分流 中 依赖开发团队的实现质量,容易出现人为错误 中间件方案 高 成熟的中间件经过广泛验证,有完善的异常处理机制 代理模式 高 独立服务运行,可靠性高,但增加了系统复杂度 - 侵入性对比
方案 侵入性 说明 代码分流 高 需要修改大量业务代码,添加AOP拦截和上下文维护 中间件方案 低 主要修改数据源配置,基本不需要修改业务逻辑 代理模式 极低 对应用完全透明,只需修改数据库连接地址 - 稳定性对比
方案 稳定性 说明 代码分流 中 容易受应用升级影响,需要持续维护 中间件方案 高 独立于业务逻辑,稳定性较好 代理模式 中高 服务稳定,但引入了网络通信开销
2. 推荐方案
综合考虑各种因素,对大多数企业级应用,应用层中间件方案(如ShardingSphere-JDBC)通常是最佳选择:
- 应用层中间件的优势
- 平衡的侵入性:只需修改数据源配置,无需大规模修改业务代码
- 出色的性能:直接嵌入应用,无额外网络开销
- 功能丰富:不仅支持读写分离,还支持分库分表、数据脱敏等高级功能
- 生态完善:主流中间件都有完善的文档、社区支持和监控工具
- 实施建议
- 循序渐进:先从非核心业务开始实施读写分离,验证后再推广到核心业务
- 监控先行:建立完善的监控体系,监控主从延迟、SQL执行时间等关键指标
- 故障演练:定期进行主从切换、从库不可用等故障演练,验证系统弹性
- 数据一致性考量:对于一致性要求高的场景,考虑使用事务内读主库的策略
五、扩展知识:主从延迟问题
1. 主从延迟的影响
主从延迟是读写分离架构中最常见的问题,它指主库数据变更后,从库同步完成需要的时间。主从延迟可能导致:
- 数据不一致:用户写入数据后立即查询,可能看不到自己刚才的操作
- 业务异常:依赖最新数据的业务流程可能出现逻辑错误
- 用户体验下降:显示过时数据会让用户感到困惑
在实际运维中,需要密切监控主从延迟,一般建议将延迟控制在毫秒级,最多不超过1秒。
2. 解决方案探讨
针对主从延迟问题,有多种解决策略:
- 技术层面优化
- 使用半同步复制:主库只有在至少一个从库确认收到事务后才提交事务
- 优化网络环境:减少主从库之间的网络延迟,考虑使用专用复制网络
- 提升从库硬件配置:特别是IO子系统,确保从库有足够性能应用binlog
- 使用并行复制:MySQL 5.7+支持基于组提交的并行复制,可显著提升从库应用binlog效率
- 应用层面策略
- 写后读主库:关键业务流程中,写操作后的读操作强制路由到主库
- 延迟敏感的查询使用主库:对数据一致性要求高的查询统一使用主库
- 业务接口添加版本号:客户端可以指定查询需要的数据版本,不满足时等待或重试
- 异步更新缓存:对实时性要求高的数据使用缓存,由后台任务定期从主库更新
读写分离主从延迟将单独章节讲解,敬请期待~
六、结语与未来展望
读写分离是构建高性能、高可用数据库架构的重要一环,但它只是分布式数据库的第一步。随着业务规模进一步扩大,还需要考虑分库分表、跨区域部署等更复杂的技术方案。
未来,随着云原生数据库和NewSQL数据库的发展,读写分离可能会以新的形式出现,如自动伸缩的读节点、智能负载感知的路由策略等。但无论技术如何演进,深入理解读写分离的核心原理,将有助于我们在面对数据库扩展挑战时做出明智的技术选择。


















 2218
2218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











