







字符串匹配的意思是给一个字符串集合,和另一个字符串集合,看这两个集合交集是多少。
若是都只有一个字符串,那么就看其中一个是否包含另外一个;
若是父串集合(比较长的,被当做模板)的有多个,子串(拿去匹配的)只有一个,就是问这个子串是否存在于父串之中;
若是子串父串集合都有多个,那么就是问交集了。
1.KMP算法
KMP算法是用来处理一对一的匹配的。
朴素的匹配算法,或者说暴力匹配法,就是将两个字符串从头比到尾,若是有一个不同,那么从下一位再开始比。这样太慢了。所以KMP算法的思想是,对匹配串本身先做一个处理,得到一个next数组。这个数组是做什么用的呢?next [j] = k,代表j之前的字符串中有最大长度为k 的相同前缀后缀。记录这个有什么用呢?对于ABCDABC这个串,如果我们匹配ABCDABTBCDABC这个长串,当匹配到第7个字符T的时候就不匹配了,我们就不用直接移到B开始再比一次,而是直接移到第5位来比较,岂不美哉?所以求出了next数组,KMP就完成了一大半。next数组也可以说是开始比较的位数。
计算next数组的方法是对于长度为n的匹配串,从0到n-1位依次求出前缀后缀最大匹配长度。
比如ABCDABD这个串:
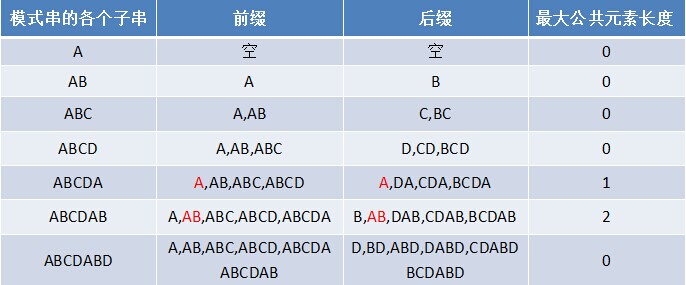
(图片来源https://www.cnblogs.com/zhangtianq/p/5839909.html)
如何去求next数组呢?k是匹配下标。这里没有从最后一位开始和第一位开始分别比较前缀后缀,而是利用了next[i-1]的结果。
void getnext()//获取next数组
{
int i,n,k;
n=strlen(ptr);
memset(next,0,sizeof(next));
k=0;
for(i=1;i<n;i++)
{
while(k>0 && ptr[k]!=ptr[i])
k=next[k];
if(ptr[k]==ptr[i]) k++;
next[i+1]=k;
//next表示的是匹配长度
}
}int kmp(char *a,char *b)//匹配ab两串,a为父串
{
int i=0,j=0;
int len1=strlen(a);
int len2=strlen(b);
getnext();
while(i<len1&&j<len2)
{
if(j==0||a[i]==b[j])
{ i++;j++; }
else j=next[j+1];//到前一个匹配点
}
if(j>=len2)
return i-j;
else return -1;
}一个完整的代码:
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std;
const int N=100;
char str[100],ptr[100];//父串str和子串ptr
int next[100];
string ans;
void getnext()//获取next数组
{
int i,n,k;
n=strlen(ptr);
memset(next,0,sizeof(next));
k=0;
for(i=1;i<n;i++)
{
while(k>0 && ptr[k]!=ptr[i])
k=next[k];
if(ptr[k]==ptr[i]) k++;
next[i+1]=k;
//next表示的是匹配长度
}
}
int kmp(char *a,char *b)//匹配ab两串 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









