







以下分割线前为转载!
简介
KMP 算法是 D.E.Knuth、J,H,Morris 和 V.R.Pratt 三位神人共同提出的,称之为 Knuth-Morria-Pratt 算法,简称 KMP 算法。该算法相对于 Brute-Force(暴力)算法有比较大的改进,主要是消除了主串指针的回溯,从而使算法效率有了某种程度的提高。
提取加速匹配的信息
上面说道 KMP 算法主要是通过消除主串指针的回溯来提高匹配的效率的,那么,它是则呢样来消除回溯的呢?就是因为它提取并运用了加速匹配的信息!
这种信息就是对于每模式串 t 的每个元素 t j,都存在一个实数 k ,使得模式串 t 开头的 k 个字符(t 0 t 1…t k-1)依次与 t j 前面的 k(t j-k t j-k+1…t j-1,这里第一个字符 t j-k 最多从 t 1 开始,所以 k < j)个字符相同。如果这样的 k 有多个,则取最大的一个。模式串 t 中每个位置 j 的字符都有这种信息,采用 next 数组表示,即 next[ j ]=MAX{ k }。
加速信息,即数组 next 的提取是整个 KMP 算法中最核心的部分,弄懂了 next 的求解方法,也就弄懂了 KMP 算法的十之七八了,但是不巧的是这部分代码恰恰是最不容易弄懂的……
先上代码
void Getnext(int next[],String t)
{
int j=0,k=-1;
next[0]=-1;
while(j<t.length-1)
{
if(k == -1 || t[j] == t[k])
{
j++;k++;
next[j] = k;
}
else k = next[k];//此语句是这段代码最反人类的地方,如果你一下子就能看懂,那么请允许我称呼你一声大神!
}
}
ok,下面咱们分三种情况来讲 next 的求解过程
1. 特殊情况
当 j 的值为 0 或 1 的时候,它们的 k 值都为 0,即 next[0] = 0、next[1] =0。但是为了后面 k 值计算的方便,我们将 next[0] 的值设置成 -1。
2. 当 t[j] == t[k] 的情况
举个例子: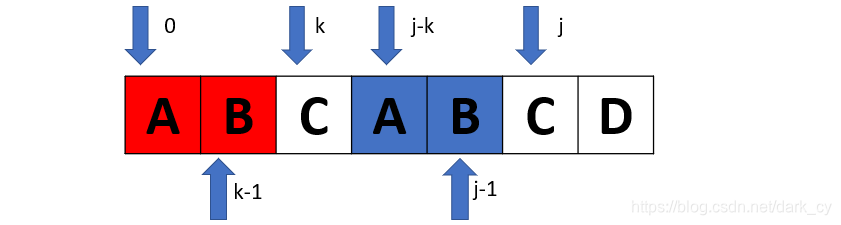
观察上图可知,当 t[j] == t[k] 时,必然有"t[0]…t[k-1]" == " t[j-k]…t[j-1]",此时的 k 即是相同子串的长度。因为有"t[0]…t[k-1]" == " t[j-k]…t[j-1]",且 t[j] == t[k],则有"t[0]…t[k]" == " t[j-k]…t[j]",这样也就得出了next[j+1]=k+1。
3. 当t[j] != t[k] 的情况
关于这种情况,在代码中的描述就是“简单”的一句 k = next[k];。我当时看了之后,感觉有点蒙,于是就去翻《数据结构教程》。但是这本书里,对于这行代码的解释只有三个字:k 回退…!于是我从“有点蒙”的状态升级到了“很蒙蔽”的状态,我心想,k 回退?我当然知道这是 k 退回,但是它为什么要会退到 next[k] 的位置?为什么不是回退到k-1???巴拉巴拉巴拉…此处省略一万字。
我绞尽脑汁,仍是不得其解。于是我就去问度娘…
在我看了众多博客之后,终于有了一种拨云见日的感觉,看下图
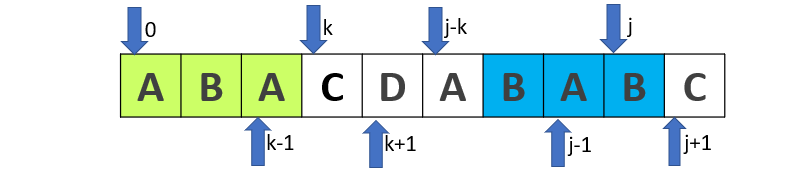
由第2中情况可知,当 t[j] == t[k] 时,t[j+1] 的最大子串的长度为 k,即 next[j+1] = k+1。但是此时t[j] != t[k] 了,所以就有 next[j+1] < k,那么求 next[j+1] 就等同于求 t[j] 往前小于 k 个的字符(包括t[j],看上图蓝色框框)与 t[k] 前面的字符(绿色框框)的最长重合串,即 t[j-k+1] ~ t[j] 与 t[0] ~ t[k-1] 的最长重合串(这里所说“最长重合串”实不严谨,但你知道是符合 k 的子串就行…),那么就相当于求 next[k](只不过 t[k] 变成了 t[j],但是 next[k] 的值与 t[k] 无关)!!!。所以才有了这句 k = next[k],如果新的一轮循环(这时 k = next[k] ,j 不变)中 t[j] 依然不等于 t[k] ,则说明倒数第二大 t[0~next[k]-1] 也不行,那么 k 会继续被 next[k] 赋值(这就是所谓的 k 回退…),直到找到符合重合的子串或者 k == -1。
至此,算是把求解数组 next 的算法弄清楚了(其实是,终于把 k = next[k] 弄懂了…)
因为这个算法神奇难解之处就在k=next[k]这一处的理解上,网上解析的非常之多,有的就是例证,举例子按代码走流程,走出结果了,跟肉眼看的一致,就认为解释了为什么k=next[k];很少有看到解释的非常清楚的,或者有,但我没有仔细和耐心看下去。我一般扫一眼,就大概知道这个解析是否能说的通。仔细想了三天,搞的千转百折,山重水复,一头雾气缭绕的。搞懂以后又觉得确实简单,但是绕人,烧脑。
再此特别感谢昵称为“sofu6”的博客园主,正是他的博客,让我这愚笨的脑袋瓜开窍了
KMP算法实现
当你求出了 next 数组之后,KMP 算法就很轻易搞定了,下面我用三张图,让你明白 KMP 算法完成匹配的整个过程。
以目标串:s,指针为 i ;模式串:t 指针为 j ; 为例

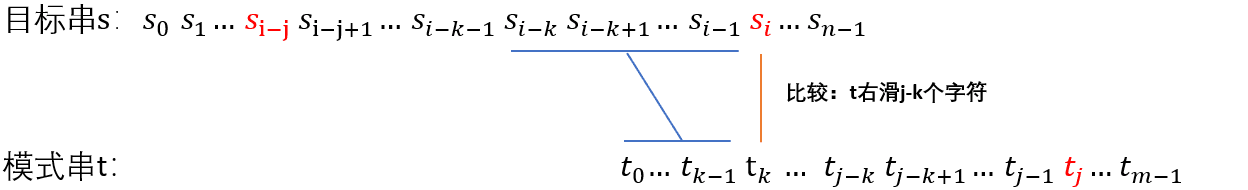
将模式串右移,得到上图,这样就避免了目标穿的指针回溯。
都明了之后就可以手写 KMP 的代码了
int KMP(String s,String t)
{
int next[MaxSize],i=0;j=0;
Getnext(t,next);
while(i<s.length&&j<t.length)
{
if(j==-1 || s[i]==t[j])
{
i++;
j++;
}
else j=next[j]; //j回退。。。
}
if(j>=t.length)
return (i-t.length); //匹配成功,返回子串的位置
else
return (-1); //没找到
}
改进后的 next 求解方法
先来看一下上面算法存在的缺陷:
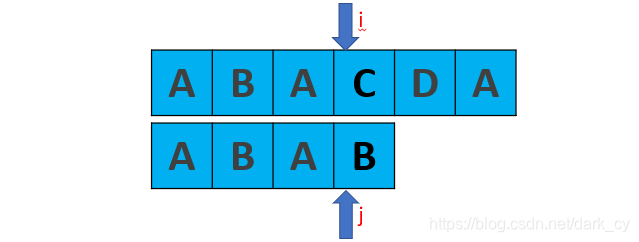
显然,当我们上边的算法得到的next数组应该是[ -1,0,0,1 ]
所以下一步我们应该是把j移动到第1个元素咯:
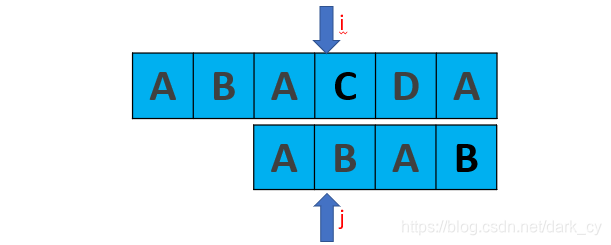
不难发现,这一步是完全没有意义的。因为后面的B已经不匹配了,那前面的B也一定是不匹配的,同样的情况其实还发生在第2个元素A上。
显然,发生问题的原因在于t[j] == t[next[j]]。
所以我们需要谈价一个判断:
void Getnext(int next[],String t)
{
int j=0,k=-1;
next[0]=-1;
while(j<t.length-1)
{
if(k == -1 || t[j] == t[k])
{
j++;k++;
if(t[j]==t[k])//当两个字符相同时,就跳过
next[j] = next[k];
else
next[j] = k;
}
else k = next[k];
}
}
本文对sofu6的博客多有借鉴,所以在此特别鸣谢,并附上他的博客:想看点这里
树
字典树

一道训练题----> ACwing-tire
#include<iostream>
#include<algorithm>
#include<string.h>
#include <set>
#include<cstdio>
#include <vector>
#include<map>
#include<string>
#include<cstring>
#include<numeric>
#include<math.h>
#include<queue>
#include <functional>
#include <bits/stdc++.h>
#include<unordered_map>
using namespace std;
#define Fast std::ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
#define SQR(i) fixed<<setprecision(i)
#define int long long
typedef long long ll;
#define endl '\n'
#define int long long
#define inf 0x3f3f3f3f
#define inf_max 0x7f7f7f7f
typedef pair<int, int> PII;
const int N = 2e6 + 5;
int son[N][26], cnt[N], idx;
//son代表字典树,每个节点延展26个分支,cnt记录每个字符串出现的次数
//idx表示节点位置
void insert_str(string& s)
{
int p = 0;
for (int i = 0, len = s.size(); i < len; ++i)
{
int u = s[i] - 'a';
if (!son[p][u])son[p][u] = ++idx;
p = son[p][u];
}
cnt[p]++;
}
int qunery_str(string& s)
{
int p = 0;
for (int i = 0, len = s.size(); i < len; ++i)
{
int u = s[i] - 'a';
if (!son[p][u])return 0;
p = son[p][u];
}
return cnt[p];
}
void Solve() {
int n; cin >> n;
while (n--)
{
char op[2];
string s;
cin >> op>>s;
if (op[0] == 'I') insert_str(s);
else cout << qunery_str(s) << endl;
}
}
signed main()
{
std::ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
int t;
Solve();
}
异或树
ACwing-异或大法
#include <bits/stdc++.h>
#include<unordered_map>
using namespace std;
#define Fast std::ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
#define SQR(i) fixed<<setprecision(i)
#define int long long
typedef long long ll;
#define endl '\n'
#define int long long
#define inf 0x3f3f3f3f
#define inf_max 0x7f7f7f7f
typedef pair<int, int> PII;
const int N = 2e6 + 5;
int son[N][2], idx;
//分支只有1 0,idx为节点
void insert_num(int x) {
int p = 0;//root;
for (int i = 30; i >= 0; --i) {
//30是因为范围是2^31
int u = x >> i & 01;
//这个操作是求第几位二进制是多少
if (!son[p][u])son[p][u] = ++idx;
p = son[p][u];
}
}
int qunery_num(int x) {
int p = 0, res = 0;
for (int i = 30; i >= 0; --i) {
int u = x >> i & 01;
if (!son[p][!u]) {
p = son[p][u];
res = res * 2 + u;
//存数字 左移1为+u
//属于是退而求其次
}
else {
p = son[p][!u];
res = res * 2 + !u;
}
}
return res;
}
void Solve() {
int n;
cin >> n;
int res = 0;
while (n--) {
int x;
cin >> x;
int t = qunery_num(x);
insert_num(x);
res = max(res, t ^ x);
}
cout << res << endl;
}
signed main() {
std::ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int t;
Solve();
}
KMP 字典tire AC自动机 题:
1.831. KMP字符串
对于本体来说就是模板题,这里重新解释一波,首先我们正常的cin,先处理模板串,求出ne,ne就是最长相等前后缀,什么是最长相等前后缀呢,比如:aba,ne初始-1,0,对于第三个字符我们可以求出ne为0,因为在第三个字符前面ab,拆分成两个部分没有相等的地方,而对于abab我们知道前两个初始化为-1,0,但是对于第三个字符,和上述情况一样,ne=0,第四个字符就不一样了,它的前面是aba,前缀我们取a(左边的a)后缀取右边的a,这最长相等前后缀就是1,所以它的ne[3]=1,如果有ababa,第五个字符前面的abab我们得到分成两个ab,那么他们的最长相等前后缀就是2,在知道什么是ne之后,我们用代码实现后,对于下一个for就是单纯的变例找了,没有找到,发现不同就回溯,j=ne[j],直到找到相等或者j==0,就退出!!!
题解代码:
#include<iostream>
#include<algorithm>
#include<string.h>
#include <set>
#include<cstdio>
#include <vector>
#include<map>
#include<string>
#include<cstring>
#include<numeric>
#include<math.h>
#include<queue>
#include <functional>
#include <bits/stdc++.h>
#include<unordered_map>
using namespace std;
#define Fast std::ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
#define SQR(i) fixed<<setprecision(i)
#define int long long
typedef long long ll;
#define endl '\n'
#define int long long
#define inf 0x3f3f3f3f
#define inf_max 0x7f7f7f7f
typedef pair<int, int> PII;
const int N = 2e6 + 5;
int ne[N];
int cnt;
char p[N], s[N];
void Solve() {
int n, m;
cin >> n >> p+1 >> m >> s+1;
for (int i = 2,j=0; i <= n; ++i)
{
while (j && p[i] != p[j+1])j = ne[j];
if (p[i] == p[j+1]) j++;
ne[i] = j;
}
for (int i = 1, j = 0; i <= m; ++i)
{
while (j && p[j + 1] != s[i])j = ne[j];
if (p[j + 1] == s[i]) j++;
if (j == n) {
cout << i - n << " ";
j = ne[j];
}
}
}
signed main()
{
std::ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
int t;
Solve();
}














 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









