






原视频链接:https://www.youtube.com/watch?v=TGZfZVuF9Yc&t=28s&ab_channel=HuggingFace
1.假设我们的语料库和对应词频如下:

2.首先,列出所有可能的字符串
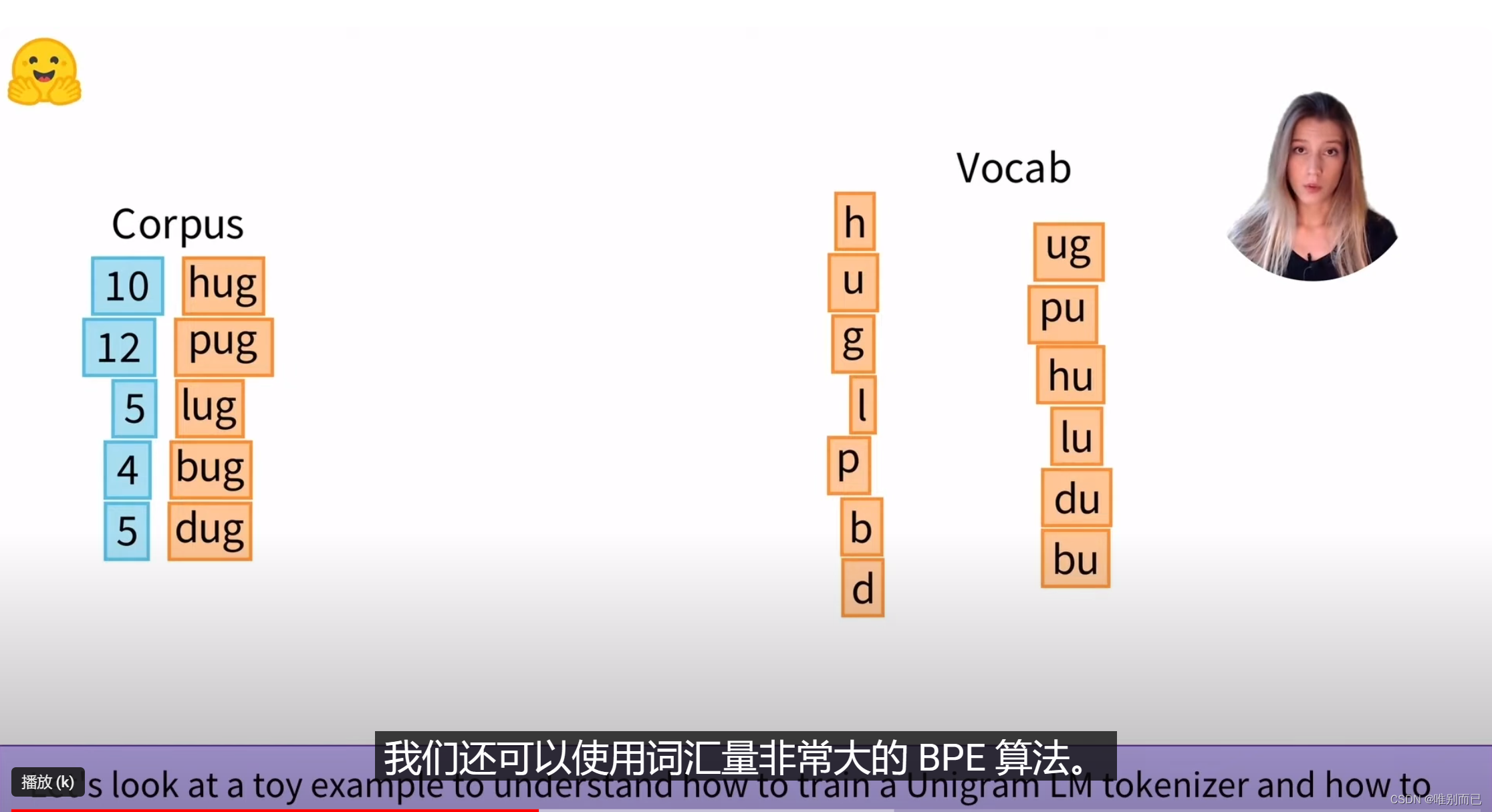
3.每次迭代,我们估计词汇token的概率,删除p%的token(不包括最基本的字母token,因为单个字母可以为任何单词分词),最大限度地减少语料库上的损失。
4.让我们看一个例子
第一次迭代:
每个token的概率按照其在语料库中出现的频率除以所有所有token的总数来计算。
 a.我们如何使用Unigram模型来tokenize一个单词?
a.我们如何使用Unigram模型来tokenize一个单词?
b.如何计算我们的语料库的损失?
Unigram 对于单词“hug”的分词是所有可能的分词中概率最大的那个,为了找到它,首先要列出所有可能的情况
 计算所有情况对应的概率并选出最大的那个并且记录他的概率。
计算所有情况对应的概率并选出最大的那个并且记录他的概率。
 然后对语料库中剩余的单词依次执行相同的计算。
然后对语料库中剩余的单词依次执行相同的计算。
 然后损失按下图中的公式计算:
然后损失按下图中的公式计算:

 在此强调一下,我们最初的目标是减少词汇量。所以接下来我们将会从词汇表移除一个token并计算相应损失。
在此强调一下,我们最初的目标是减少词汇量。所以接下来我们将会从词汇表移除一个token并计算相应损失。
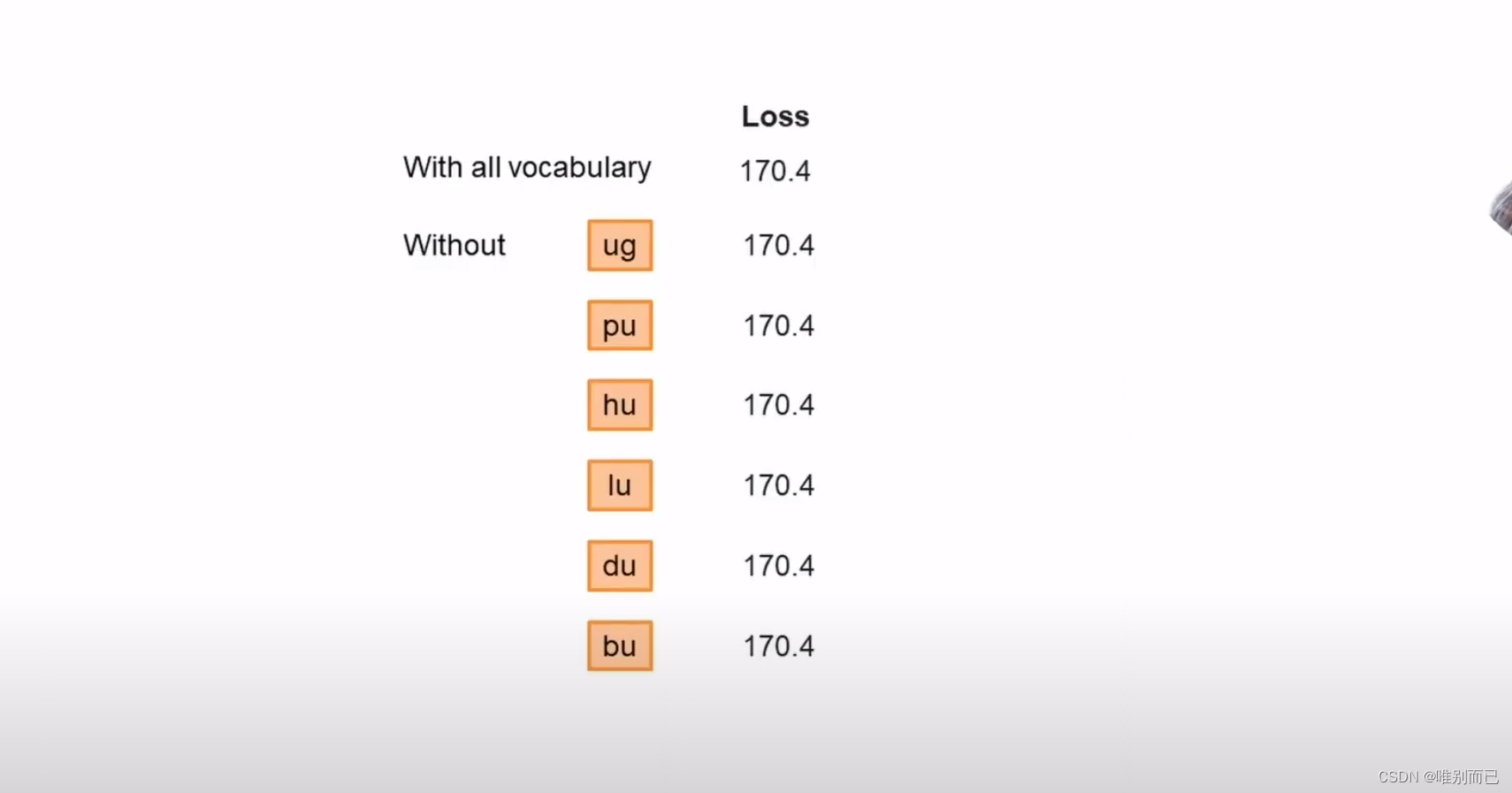
我们移除"ug",移除以后我们依然像前面一样以此计算语料库中单词的概率
 经过计算,损失依是170.40
经过计算,损失依是170.40
 其实继续计算会发现,不论移除哪一个token,损失都是170.4,这意味着在下一次迭代之前,可以任意移除一个token(移除ug)
其实继续计算会发现,不论移除哪一个token,损失都是170.4,这意味着在下一次迭代之前,可以任意移除一个token(移除ug)
 第二次迭代:
第二次迭代:
计算单词概率,计算语料库上的损失:170.4
移除一个token(假设是hu),重新计算单词概率,进一步计算损失:168.20
 然后对剩下的token执行相同操作
然后对剩下的token执行相同操作
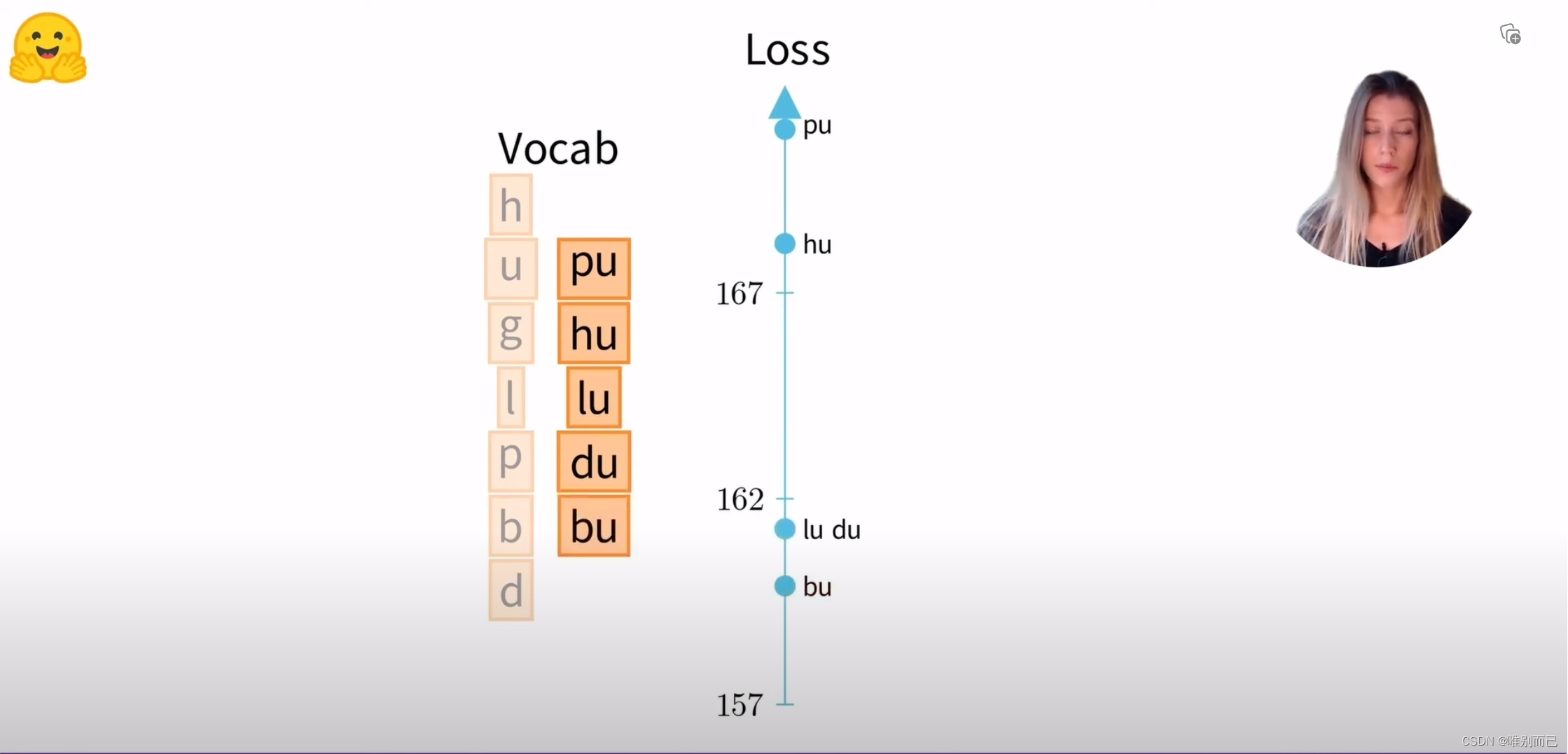 移除影响损失最小的token:bu
移除影响损失最小的token:bu

















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









