







前言
朴素贝叶斯建模。
一、数据预处理
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 666)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
二、NB的调参策略
先复习一下参数(传送门),需要调整的参数有:
① priors:先验概率大小,如果没有给定,模型则根据样本数据自己计算(利用极大似然法),这个可以不调。
② var_smoothing:所有特征的最大方差部分,添加到方差中用于提高计算稳定性,默认1e-9。
三、NB调参演示
(A)先默认参数走一波:
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
print(cm_train)
print(cm_test)
结果还可以:
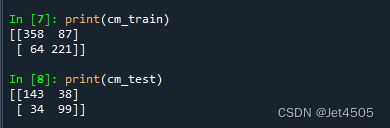

调整一下参数:
(B)调var_smoothing:
from sklearn.naive_bayes import GaussianNB
param_grid=[{
'var_smoothing': [1e-9,1e-6,1e-4,1e-3,1e-2,1,10,100],
},
]
boost = GaussianNB()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 2, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier = classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
print(cm_train)
print(cm_test)
结果:
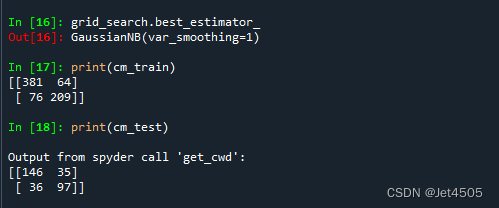

最优模型:GaussianNB(var_smoothing=1)
性能一般般吧,勉强过得去:
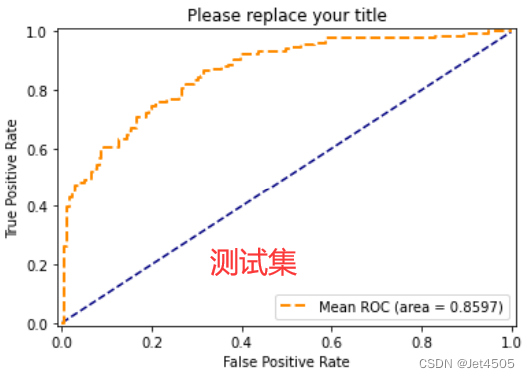
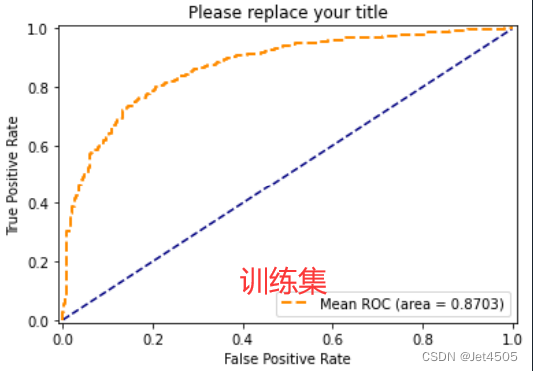
总结
终于,把是个最经典的机器学习分类模型的大致调参策略都介绍完了,头发掉了不少,我发现写流程跟自己分析数据差距还是很大的,需要更多的精力和时间。
当然还没完,还需要大家把所有十个模型的性能参数进行归类,找出有好的模型!
接下来,我会把之前埋的坑补上,然后这个阶段——ML分类建模就告一段落了。

















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











