







基于WIN10的64位系统演示
一、写在前面
这一次,我们来继续解读ARIMA组合模型文章,也是老文章了:
《PLoS One》杂志的2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndrome in Jiangsu Province, China》文章的公开数据做案例。
这文章做的是用:使用两种ARIMA组合模型预测江苏省出血热发病率。

文章是用单纯的ARIMA模型作为对照,对比了两种组合模型:ARIMA-GRNN模型和ARIMA-NARNN模型。上一期,我们来重现了ARIMA-GRNN模型。本期,我们来尝试ARIMA-NARNN模型。
二、闲聊和复现:
(1)单纯ARIMA模型构建
(2)ARIMA-NARNN组合模型
①首先,使用GPT-4弄清楚文章使用的策略是啥:

不知道大家看懂了没,我又用一个具体例子再次验证:
比如说2001年到2010年的数据构建ARIMA模型,预测2011年的数据。得到2001年到2010年的残差序列,然后使用残差序列构建NARNN模型,预测出2011年的残差,在与ARIMA模型预测的2011年的数据做矫正,得到组合模型的结果?
GPT-4的回答:

简单来说就是,首先使用2004-01到2011-12的数据构建并找出最优模型ARIMA (0,1,1)×(0,1,1)12,并使用模型进行拟合(2004-01至2011-12)和预测(2012-01至2012-12)。然后,根据真实值计算得到2004-01到2011-12的拟合残差序列,以及2012-01至2012-12的预测残差序列。之后,用2004-01到2011-12的拟合残差序列再进行一次时间序列建模,模型用的是NARNN,得到拟合(2004-01至2011-12)和预测(2012-01至2012-12)的残差结果,再用来与ARIMA模型的拟合与预测结果进行校正,输出的就是ARIMA-NARNN组合模型的结果。
很绕是不是?其实就是在把残差序列用另一个模型再预测一次。把NARNN模型换成其他模型,可能就是ARIMA-其他模型的组合模型了。
②那就让GPT-4帮生成代码吧:
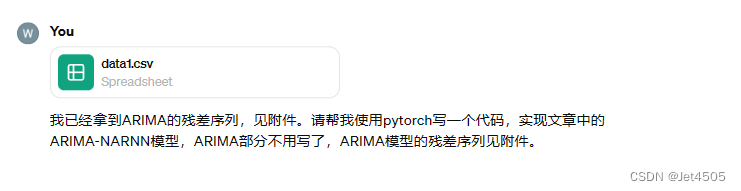
倒是生成了代码,不过有瑕疵,经过我多次微调,如下:
import torch
import torch.nn as nn
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error
# 计算MAPE
def mean_absolute_percentage_error(y_true, y_pred):
y_true, y_pred = np.array(y_true), np.array(y_pred)
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
# 数据加载
data = pd.read_csv('data1.csv')
residuals = data['incidence'].values.astype(float)
# 数据归一化
scaler = MinMaxScaler(feature_range=(-1, 1))
residuals_normalized = scaler.fit_transform(residuals.reshape(-1, 1)).flatten()
# 使用前83个数据进行建模
train_data = residuals_normalized[:83]
# 准备时间序列数据
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data)-seq_length):
x = data[i:(i+seq_length)]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 6 # 使用6个时间点预测下一个时间点
X, y = create_sequences(train_data, seq_length)
X_tensor = torch.FloatTensor(X).view(-1, seq_length, 1)
y_tensor = torch.FloatTensor(y).view(-1, 1)
# 定义模型
class NARNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(NARNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return out
# 设置超参数
input_size = 1
output_size = 1
hidden_size = 50
num_layers = 1
learning_rate = 0.001
num_epochs = 100
model = NARNN(input_size, hidden_size, output_size, num_layers)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
loss.backward()
optimizer.step()
if epoch == num_epochs - 1: # 最后一个epoch计算训练集的MSE, MAE, MAPE
y_pred_train = outputs.detach().numpy()
y_true_train = y_tensor.numpy()
mse_train = mean_squared_error(y_true_train, y_pred_train)
mae_train = mean_absolute_error(y_true_train, y_pred_train)
mape_train = mean_absolute_percentage_error(y_true_train, y_pred_train)
print(f'Train MSE: {mse_train:.4f}, Train MAE: {mae_train:.4f}, Train MAPE: {mape_train:.4f}%')
# 使用最后的模型进行预测最后12个数据
model.eval()
test_data = residuals_normalized[83-seq_length:83] # 使用从71到82的数据开始预测
predictions = []
for _ in range(12):
with torch.no_grad():
x_test_tensor = torch.FloatTensor(test_data).view(1, seq_length, 1)
pred = model(x_test_tensor)
predictions.append(pred.numpy().flatten()[0])
test_data = np.append(test_data[1:], pred.numpy().flatten()[0]) # 更新输入数组
# 反归一化预测结果
predictions = scaler.inverse_transform(np.array(predictions).reshape(-1, 1)).flatten()
original_values = scaler.inverse_transform(residuals_normalized[83:].reshape(-1, 1)).flatten()
# 计算验证集的MSE, MAE, MAPE
mse_val = mean_squared_error(original_values, predictions)
mae_val = mean_absolute_error(original_values, predictions)
mape_val = mean_absolute_percentage_error(original_values, predictions)
print(f'Validation MSE: {mse_val:.4f}, Validation MAE: {mae_val:.4f}, Validation MAPE: {mape_val:.4f}%')③很好奇NARNN模型的参数是什么:
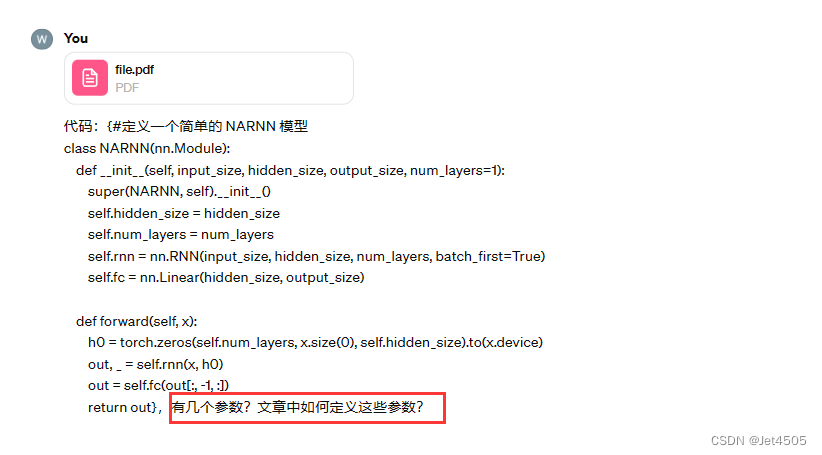
看来,文章其实也没说清楚:

④NARNN模型的参数我就简单设置了:使用6个数据预测下一个,其他默认参数了。最终的结果及其不理想,哈哈哈,大家自行调整了,毕竟参数那么多。不过,感觉吧,就是个玄学。
预测的MAPE为61.9%,比ARIMA模型的还大。拟合的更加惨,甚至大于100%。
三、个人感悟
可以看到,ARIMA-NARNN组合模型的构建策略,也可以延伸出ARIMA-LSTM、ARIMA-CNN、ARIMA-Xgboost等一堆组合模型。至于有没有效果,那就看具体数据和大家的调参能力了。
还是那句话:其实有些数据吧,用组合模型,性能反而变差了,它并不是万能的。
四、数据
链接:https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0135492
有童鞋问咋下载数据:

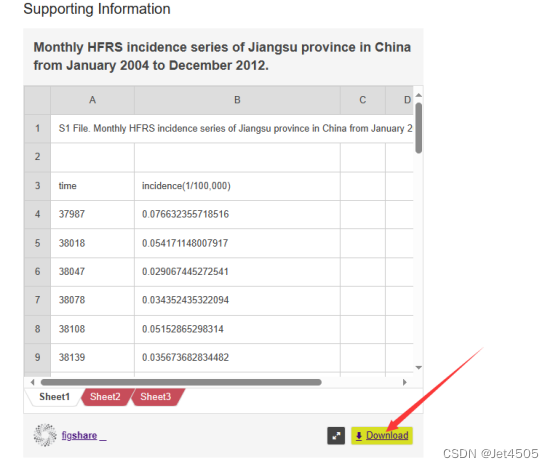

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











