







最近的一些研究指出soft labels带来的regularization是知识蒸馏有效的原因之一。这边论文从训练过程中的bias-variance博弈角度出发,对soft labels重新进行了思考,研究发现这种博弈会导致训练过程的智能采样,对此论文提出了weighted soft labels来应对这种博弈,实验表明了这种方法的有效性。
整篇论文论据充分,详细解释了最后结论的推导过程,提出的wsl方法简单易用,能快速应用到实际业务需求中,是值得一读的一篇论文。
来源:杰读源码 微信公众号
论文:RETHINKING SOFT LABELS FOR KNOWLEDGE DISTIL- LATION: A BIAS-VARIANCE TRADEOFF PERSPECTIVE

- 论文:https://arxiv.org/pdf/2102.00650.pdf
Introduction
论文首先通过公式分解比较不带distillation的direct训练和带distillation的训练两者的bias-variance,观察到带distillation的训练会有着更大的bias误差,但是有更小的variance误差。然后将distillation误差公式重写成regularization loss+direct training loss,通过观察这两个loss在训练中的的梯度比较,发现使用soft labels可让训练中的bias-variance博弈产生智能采样。此外,结合以往论文中的结论,在相同蒸馏温度的实验条件下,知识蒸馏的性能受到某种samples的负影响,论文里将这种使得bias上升,variance下降的samples称为regularization samples。为了调查regularization samples是怎么影响蒸馏性能的,论文首先测试了不带regularization samples的训练效果,发现这种方法也会有损蒸馏的性能,这使得作者猜测在标准的知识蒸馏中,regulariztion samples并没有被合理的利用。
基于上述的发现,论文提出了weighted soft labels来动态的给regularization samples赋予更低的权重,其他的samples赋予更高的权重,以此来更合理的权衡训练过程中的bias-variance。
综上,论文的贡献以下:
- 针对知识蒸馏,从bias-variance博弈角度思考了soft labels发挥作用的原因。
- 论文发现bias-variance权衡会导致训练中的智能采样。此外还发现了在固定住蒸馏温度的情况下,regularization samples的数量如果太多会对蒸馏效果有着负影响。
- 论文设计了一种简单的方案来减轻regularization samples带来的负面影响,并且提出了weighted soft labels应用到蒸馏中,实验证明了这种方法的有效性。
BIAS-VARIANCE TRADEOFF FOR SOFT LABELS
从数学角度来soft lables对训练过程中bias-variance权衡带来的影响。
对于一个sample x,它被标注为第i类,它的真值用one-hot编码成向量y(
y
i
=
1
y_i=1
yi=1,
y
≠
i
=
0
y_{\neq i}=0
y=i=0)。设定蒸馏温度为
τ
\tau
τ,teacher模型预测出的soft label为
y
^
τ
t
\hat{y}^t_\tau
y^τt,student模型预测出的值为
y
^
τ
s
\hat{y}^s_\tau
y^τs。
y
^
τ
t
\hat{y}^t_\tau
y^τt用来训练student模型的distillation损失:
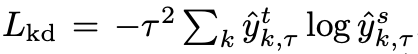
这里
y
^
k
,
τ
s
\hat{y}^s_{k,\tau}
y^k,τs和
y
^
k
,
τ
t
\hat{y}^t_{k,\tau}
y^k,τt表示student模型和teacher模型在第k个元素的输出。使用one-hot标签训练的交叉熵损失为:
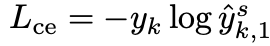
下面对
L
c
e
L_{ce}
Lce和
L
k
d
L_{kd}
Lkd两条公式进行分解。首先将train dataset设为D,还有一个sample x,一个未使用蒸馏的模型在x的输出设为
y
^
c
e
=
f
c
e
(
x
;
D
)
\hat{y}_{ce}=f_{ce}(x;D)
y^ce=fce(x;D),一个使用了蒸馏的模型在x的输出设为
y
^
=
f
k
d
(
x
;
D
,
T
)
\hat{y}_{}=f_{kd}(x;D,T)
y^=fkd(x;D,T),这里的T代表使用的teacher模型。然后得到
y
^
k
d
\hat{y}_{kd}
y^kd和
y
^
c
e
\hat{y}_{ce}
y^ce的均值
y
‾
k
d
\overline{y}_{kd}
ykd和
y
‾
k
d
\overline{y}_{kd}
ykd:
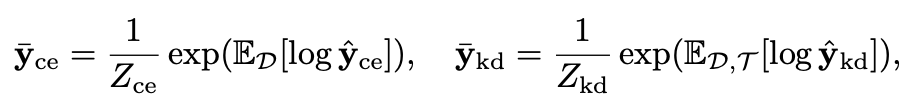
其中
Z
c
e
Z_{ce}
Zce和
Z
k
d
Z_{kd}
Zkd是两个用来标准化的常数。下面对
L
c
e
L_{ce}
Lce进行分解,其中
y
=
t
(
x
)
y=t(x)
y=t(x)是真值:
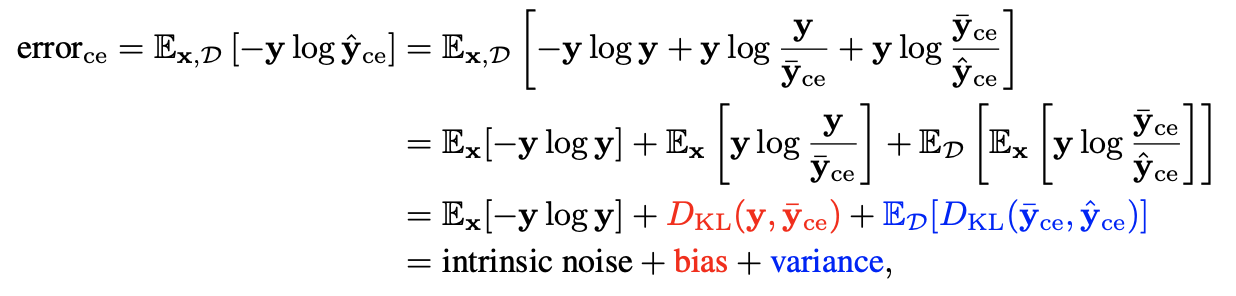
其中的
D
K
L
D_{KL}
DKL是KL散度。上面的分解过程中用到了Heskes在1998年发表的论文*《Bias/variance decompositions for likelihood-based estimators.》*里提出的结论:
l
o
g
y
‾
c
e
E
D
[
l
o
g
y
^
c
e
]
{log\overline{y}_{ce}}\over{E_D[log\hat{y}_{ce}]}
ED[logy^ce]logyce是一个常量,而且
E
x
[
y
]
=
E
x
[
y
‾
c
e
]
=
1
E_x[y]=E_x[\overline{y}_{ce}]=1
Ex[y]=Ex[yce]=1,具体的理论可以看搜那篇论文。
下面用一张图来表达知识蒸馏过程中bias和variance的博弈:
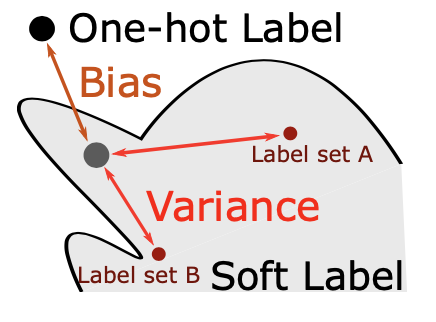
图中的Label set A和Label set B是由teacher模型生成的soft labels,灰点表示正在训练中的模型,当灰点偏向于黑点时,模型的学习更趋向于one-hot-label,此时bias减小,variance增大,模型容易变得过拟合;反之,当模型偏向于红点时,模型的学习趋向于soft lables,bias 增大,variance减小,模型的泛化能力得到提升,当然如果过于极端会变得欠拟合。根据以往论文的结论,使用知识蒸馏的得到的模型的variance往往要比直接训练的模型更小一点,也就是泛化能力要更强一点,由公式表达就是:
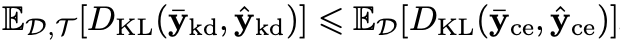
下面的推导也是基于该结论展开的。
对
L
k
d
L_{kd}
Lkd进行分解展开:
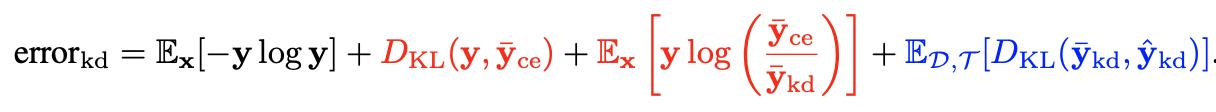
还有一个观察得到的结论:
y
‾
c
e
\overline{y}_{ce}
yce收敛于one-hot labels而
y
‾
k
d
\overline{y}_{kd}
ykd收敛于soft labels,所以
y
‾
c
e
\overline{y}_{ce}
yce的分布相比于
y
‾
k
d
\overline{y}_{kd}
ykd肯定是更接近与one-hot真值的,也就能得到:
E
x
[
y
l
o
g
(
y
‾
c
e
y
‾
k
d
)
]
⩾
0
E_x[ylog(\frac{\overline{y}_{ce}}{\overline{y}_{kd}})]\geqslant0
Ex[ylog(ykdyce)]⩾0。将
L
k
d
L_{kd}
Lkd写成
L
k
d
=
L
k
d
−
L
c
e
+
L
c
e
L_{kd}=L_{kd}-L_{ce}+L_{ce}
Lkd=Lkd−Lce+Lce,发现因为
E
x
[
y
l
o
g
(
y
‾
c
e
y
‾
k
d
)
]
⩾
0
E_x[ylog(\frac{\overline{y}_{ce}}{\overline{y}_{kd}})]\geqslant0
Ex[ylog(ykdyce)]⩾0所以
L
k
d
−
L
c
e
L_{kd}-L_{ce}
Lkd−Lce中bias会变大,而variance因为
E
D
[
D
K
L
(
y
‾
c
e
,
y
^
c
e
)
]
−
E
D
,
T
[
D
K
L
(
y
‾
k
d
,
y
^
k
d
)
]
⩽
0
E_D[D_{KL}(\overline{y}_{ce},\hat{y}_{ce})]-E_{D,T}[D_{KL}(\overline{y}_{kd},\hat{y}_{kd})]\leqslant0
ED[DKL(yce,y^ce)]−ED,T[DKL(ykd,y^kd)]⩽0所以会变小。综上,在知识蒸馏的过程中,
L
k
d
−
L
c
e
L_{kd}-L_{ce}
Lkd−Lce主导variance的下降,而
L
c
e
L_{ce}
Lce主导bias的下降。
THE BIAS-VARIANCE TRADEOFF DURING TRAINING
众所周知,训练一个模型总是希望将其bias和variance都降到最低,但是往往这是相矛盾的。当一个模型训练的开始阶段,bias error占total error的更大的比重,variance相对来说不如bias重要。随着训练的深入,降低bias error(由
L
c
e
主
导
L_{ce}主导
Lce主导)的梯度和降低variance error(由
L
k
d
−
L
c
e
L_{kd}-L_{ce}
Lkd−Lce)的梯度这两者将相互博弈,我们应该把控这种博弈。
为了研究训练过程中的这种博弈,应该思考bias和variance的梯度比较。将z作为student模型在x上的logits输出,
z
i
z_i
zi是第i个元素的输出。接下来只要关注
δ
(
L
k
d
−
L
c
e
)
δ
z
i
\frac{\delta(L_{kd}-L_{ce})}{\delta z_i}
δziδ(Lkd−Lce)。为便于理解,下面只考虑与真值相关联的logit,也就是x的标签为第i类,那么:
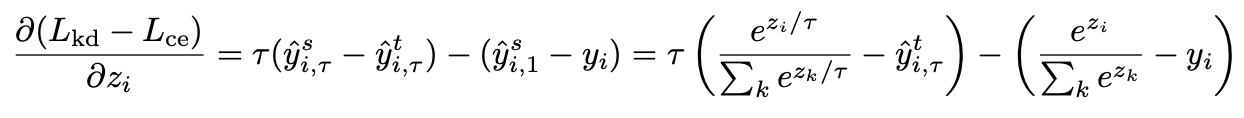
为了更方便理解,将公式里的温度系数
τ
\tau
τ设为1,梯度将变为
y
i
−
y
^
i
,
1
t
y_i-\hat{y}^t_{i,1}
yi−y^i,1t,同时,对于bias,将得到
δ
L
c
e
δ
z
i
=
y
^
i
,
1
s
−
y
i
\frac{\delta L_{ce}}{\delta z_i}=\hat{y}^s_{i,1}-y_i
δziδLce=y^i,1s−yi,很明显,
δ
L
c
e
δ
z
i
\frac{\delta L_{ce}}{\delta z_i}
δziδLce和
δ
(
L
k
d
−
L
c
e
)
δ
z
i
\frac{\delta(L_{kd}-L_{ce})}{\delta z_i}
δziδ(Lkd−Lce)有着相反的符号,反应着训练过程中两者的博弈:如果
δ
L
c
e
δ
z
i
\frac{\delta L_{ce}}{\delta z_i}
δziδLce远大于
δ
(
L
k
d
−
L
c
e
)
δ
z
i
\frac{\delta(L_{kd}-L_{ce})}{\delta z_i}
δziδ(Lkd−Lce),那么bias reduction将主导训练的优化方向,反之如果
δ
(
L
k
d
−
L
c
e
)
δ
z
i
\frac{\delta(L_{kd}-L_{ce})}{\delta z_i}
δziδ(Lkd−Lce)更大,训练数据将用来variance reduction。有一个很有趣的实验发现:在蒸馏温度固定的情况下,如果更多的训练数据被用来variance reduction,那么模型的性能就变差,下面将具体介绍。
REGULARIZATION SAMPLES
本小节的研究来源于Rafael Muller于2019年的论文*《When does label smoothing help?》*中的一个结论:如果一个teacher模型使用label smoothing训练,教授给student模型的有效知识将变少。针对该现象,论文使用不同的蒸馏参数设置做了几组实验来研究bias和variance的影响力。设
a
=
δ
L
c
e
δ
z
i
a=\frac{\delta L_{ce}}{\delta z_i}
a=δziδLce,
b
=
δ
(
L
k
d
−
L
c
e
)
δ
z
i
b=\frac{\delta(L_{kd}-L_{ce})}{\delta z_i}
b=δziδ(Lkd−Lce),用a和b来代表bias和variance在训练中的影响力。训练时,如果一个sample的b>a,那么将这个sample称为regularization samples,因为此时variance主导训练的优化方向。从实验数据发现。模型的性能和regularization samples的数量紧密相关,如下表:
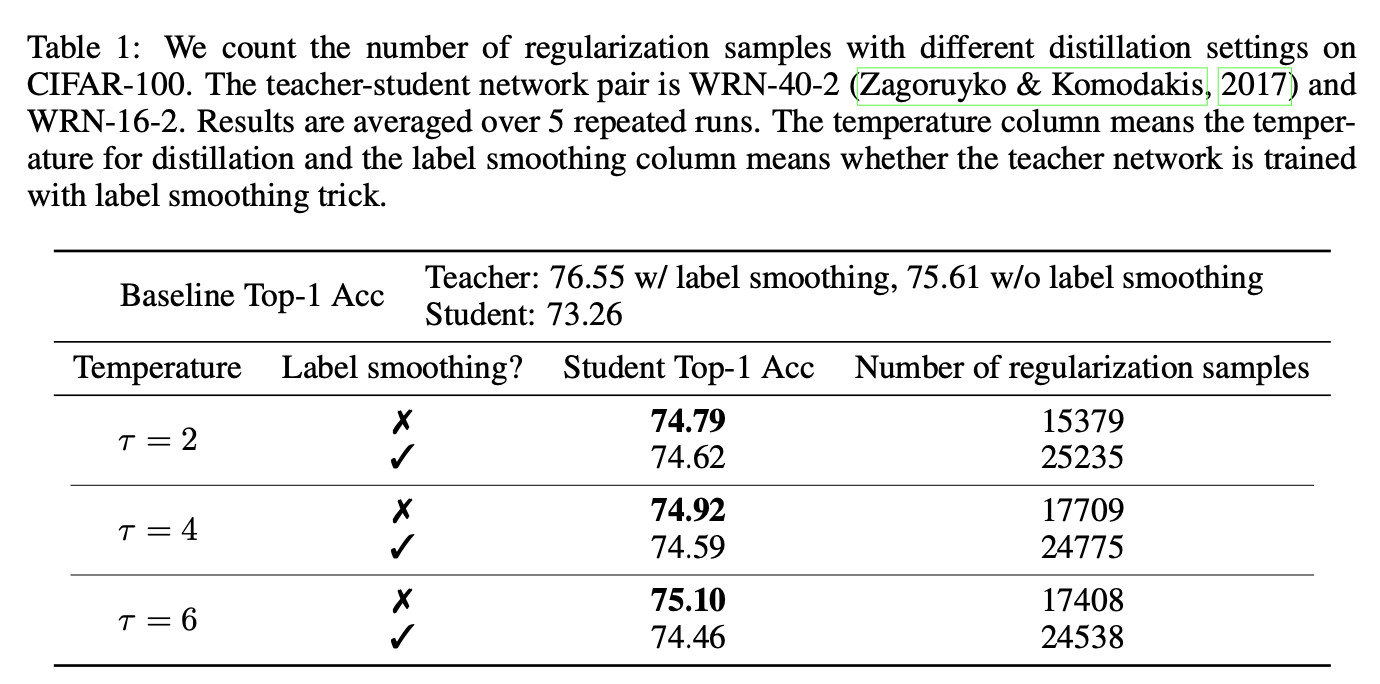
实验结果表明,teacher模型训练使用label smoothing会导致更多的数据用于variance reduction,而这使得模型的性能更差一点。此外还能总结到:对于使用soft labels的知识蒸馏,regulariztion samples的数量和模型的性能也是息息相关的。
论文还将regularization samples的数量和training epochs的关系绘制如下图:
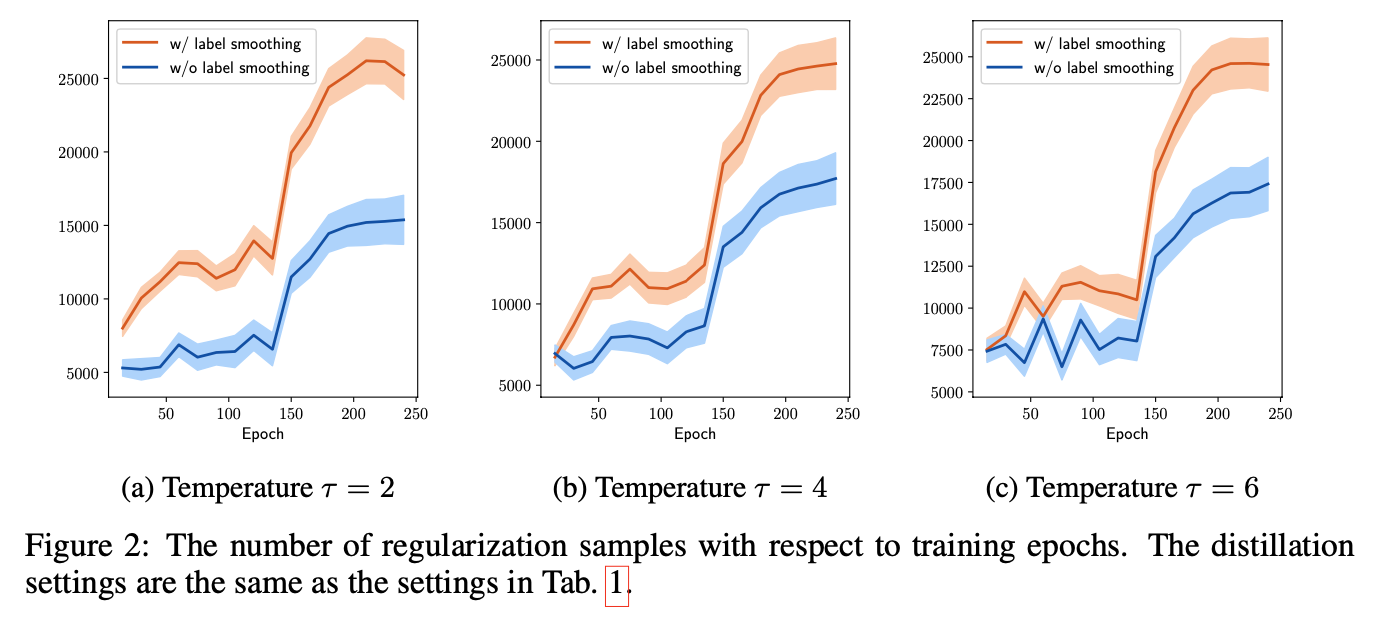
图中表明,当使用label smoothing的时候,regularization samples上升的速度会变得更快。而使用或不使用label smoothing两个训练过程中regularization samples之间的差距也会越来越大。这些实验结果都表明了bias和variance的博弈使得训练时对于sample的采样变得智能,所以对于该博弈的把控也应当是智能的。
HOW REGULARIZATION SAMPLES AFFECT DISTILLATION
上面的实验表明regulariztion似乎并不有利于训练,所以论文又做了几组实验,在训练时将regulariztion samples的影响抛弃掉。
第一个实验是手动解决上面提过的训练时bias和variance在梯度上的矛盾,直接当i为对应label时,
δ
L
k
d
δ
z
i
=
0
\frac{\delta L_{kd}}{\delta z_{i}}=0
δziδLkd=0。此时的
L
k
d
∗
=
∑
k
≠
i
y
^
k
,
τ
t
l
o
g
y
^
k
,
τ
s
L^*_{kd}=\sum_{k\neq i}\hat{y}^t_{k,\tau}log\hat{y}^s_{k,\tau}
Lkd∗=∑k=iy^k,τtlogy^k,τs。另外两组实验是为了搞清regularization samples在蒸馏中到底扮演了什么角色,对此开展了1)
L
k
d
L_{kd}
Lkd不对regularizaion samples起作用的实验和2)
L
k
d
L_{kd}
Lkd只对regularization samples起作用的实验。
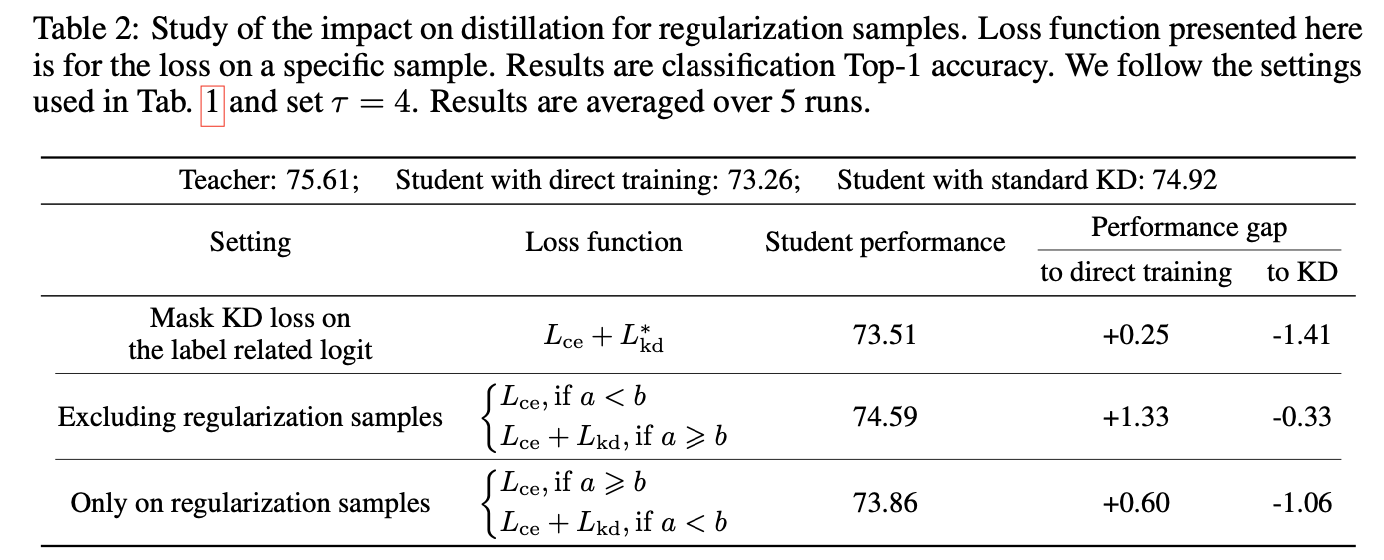
实验数据表明,以上的性能都不如标准知识蒸馏的实验结果,但是都好于直接训练的性能。综上,regularizaiton smaples对训练是有效果的,问题就是如何最大化发挥regularization samples的作用?
WEIGHTED SOFT LABELS
基于以上所有分析,论文作者思考如何对regularization samples的权重做调整。
因为regularization samples是由a和b两者的大小来划分的,所以自然而然的,作者想用a和b的值来计算这个权重。但是
L
k
d
L_{kd}
Lkd的计算包含了超参数温度,a和b也跟温度有关系,如果将温度也带入权重计算,不方便温度这个超参数的调节,毕竟该参数本身只负责蒸馏温度的控制。因此权重计算需要独立于蒸馏温度,这里直接将
τ
=
1
\tau=1
τ=1,那么
a
=
y
^
i
,
1
s
−
y
i
a=\hat{y}^s_{i,1}-y_i
a=y^i,1s−yi,
b
=
y
i
−
y
^
i
,
1
t
b=y_i-\hat{y}^t_{i,1}
b=yi−y^i,1t,实际上最后比的就是
y
^
i
,
1
s
\hat{y}^s_{i,1}
y^i,1s和
y
^
i
,
1
t
\hat{y}^t_{i,1}
y^i,1t。最后,再结合以往论文的经验,论文最终提出了weighted soft labels的公式:
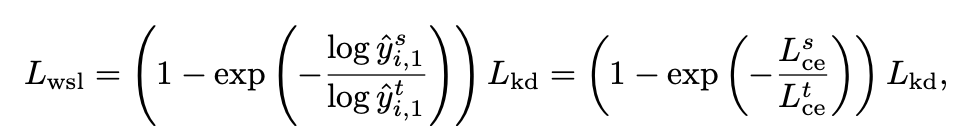
上式表明了使用teacher模型和student模型的输出组成的一个权重因子赋予原本的
L
k
d
L_{kd}
Lkd。从逻辑上理解,假如在同一个sample上student模型相比teacher模型更容易训练,可得
y
^
i
,
1
s
>
y
^
i
,
1
t
\hat{y}^s_{i,1}>\hat{y}^t_{i,1}
y^i,1s>y^i,1t,一个更小的权重将会赋予
L
k
d
L_{kd}
Lkd
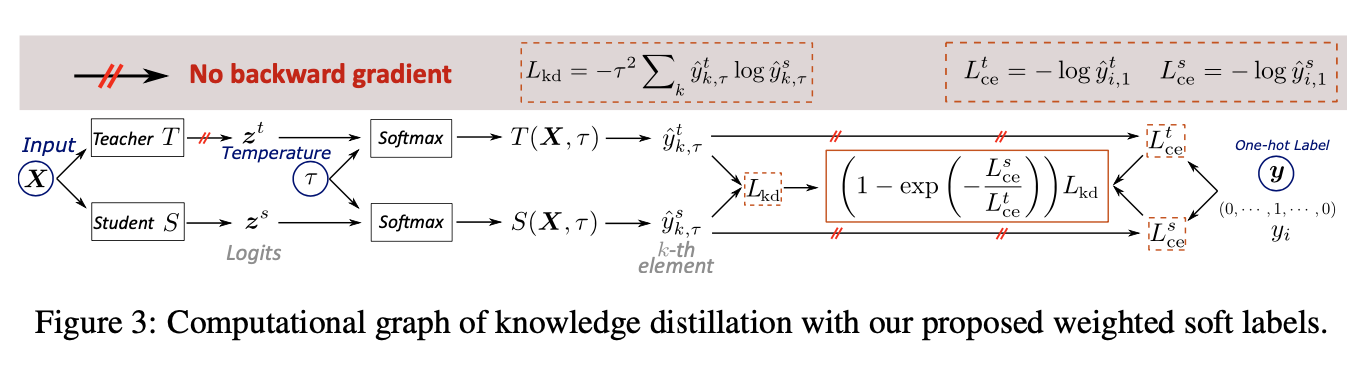
上图中非常清晰的解释了weighted soft labels的计算过程。最后,
L
t
o
t
a
l
=
L
c
e
+
α
L
w
s
l
L_{total}=L_{ce}+\alpha L_{wsl}
Ltotal=Lce+αLwsl作为知识蒸馏的loss用于监督模型训练,
α
\alpha
α为一个平衡超参数。
源码解读
- 代码:https://github.com/open-mmlab/mmrazor
# 真值
gt_labels = self.current_data['gt_label']
# student模型和teacher模型的logits值
student_logits = student / self.tau
teacher_logits = teacher / self.tau
# teacher模型logits值softmax化
teacher_probs = self.softmax(teacher_logits)
# 用于标准KD的损失计算
ce_loss = -torch.sum(
teacher_probs * self.logsoftmax(student_logits), 1, keepdim=True)
student_detach = student.detach()
teacher_detach = teacher.detach()
log_softmax_s = self.logsoftmax(student_detach)
log_softmax_t = self.logsoftmax(teacher_detach)
# 真值one-hoe编码
one_hot_labels = F.one_hot(
gt_labels, num_classes=self.num_classes).float()
# teacher模型预测值与真值的损失
ce_loss_s = -torch.sum(one_hot_labels * log_softmax_s, 1, keepdim=True)
# student模型预测值与真值的损失
ce_loss_t = -torch.sum(one_hot_labels * log_softmax_t, 1, keepdim=True)
# 求比
focal_weight = ce_loss_s / (ce_loss_t + 1e-7)
ratio_lower = torch.zeros(1).cuda()
focal_weight = torch.max(focal_weight, ratio_lower)
focal_weight = 1 - torch.exp(-focal_weight)
ce_loss = focal_weight * ce_loss
# 标准KD损失计算
loss = (self.tau**2) * torch.mean(ce_loss)
# wsl的loss
loss = self.loss_weight * loss
EXPERIMENTS
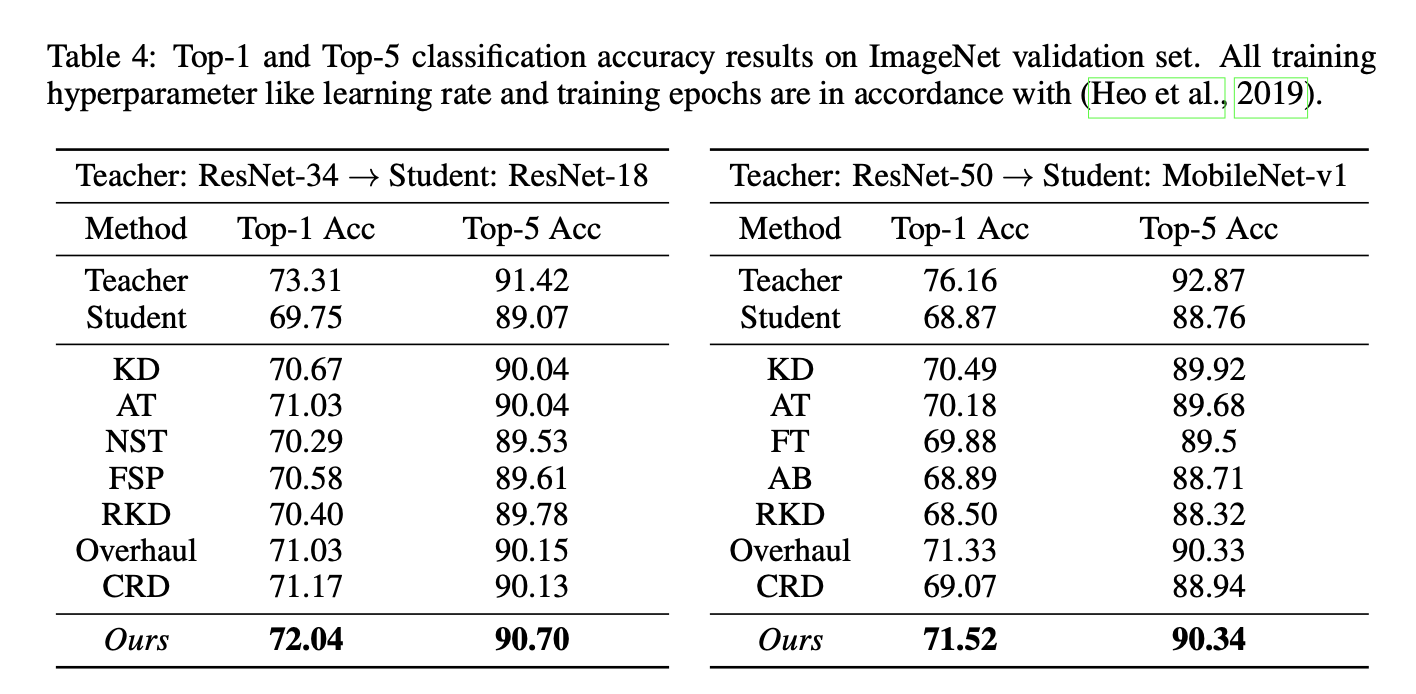
ABLATION STUDIES
论文做了两类ABLATION STUDIES,
Weighted soft labels on different subsets
为了证明wsl的有效性,作者再次做了
L
k
d
L_{kd}
Lkd只在regularization samples和不在regularizaiton samples两组实验,并和之前的一些参数设置相同,得到一下数据:
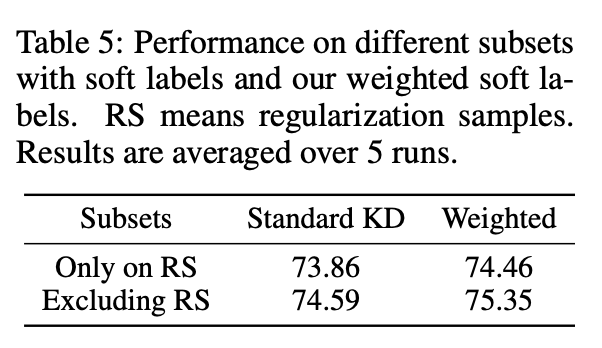
和之前相比,应用weighted soft labels能明显提升性能并高于标准KD的性能。
Distillation with label smoothing trained teacher
针对之前的smoothing label做一次消融实验:
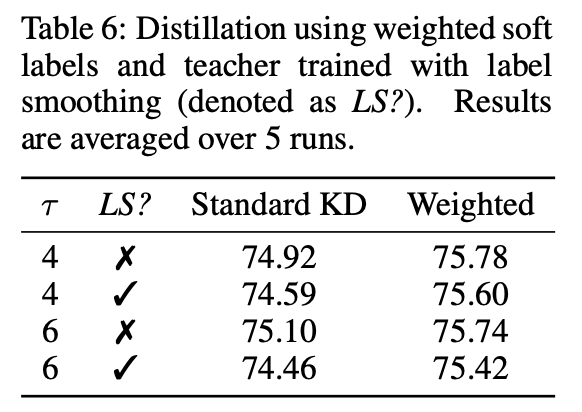
wsl效果显著。
Conclusion
最近的一些研究指出soft labels带来的regularization是知识蒸馏有效的原因之一。这边论文从训练过程中的bias-variance博弈角度出发,对soft labels重新进行了思考,研究发现这种博弈会导致训练过程的智能采样,对此论文提出了weighted soft labels来应对这种博弈,实验表明了这种方法的有效性。
来源:杰读源码 微信公众号



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









