







论文针对dense prediction提出的channel-wise蒸馏方法,不同于以往的spatial蒸馏,将每个channel的激活层使用softmax标准化为probability map,然后使用KL散度缩小teacher网络和student网络之间的差异。实验表明了这种方法的有效性,并且在semantic segmentation和object detection两个方向表现出了state-of-the-art。
来源:杰读源码 微信公众号
论文:Channel-wise Knowledge Distillation for Dense Prediction

- 论文:https://arxiv.org/pdf/2011.13256.pdf
- 代码:https://github.com/open-mmlab/mmrazor
Introduction
知识蒸馏(Knowledge Distillation,简称KD)已经证明了是一种十分有效的将大模型的知识迁移到小模型的手段。本文提出对于dense prediction这类检测,在激活层的每个channel上提取出soft target,然后再将student网络和teacher网络进行loss计算,可以充分利用不同通道关注着不同的特征这一特性,是一种state-of-the-art的方法,思路可以由下图表达。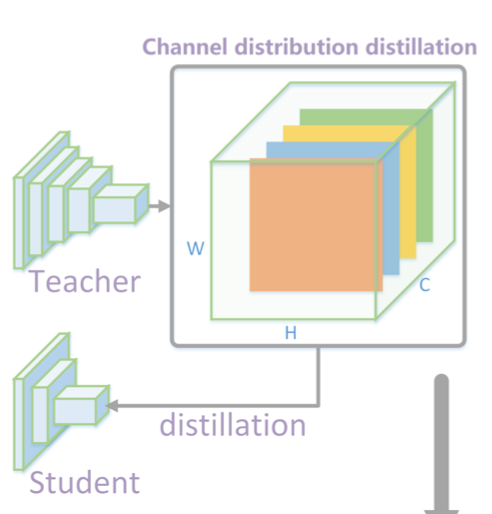
Method
论文使用了KL散度来比较student网络的channel和其对应的teacher网络中的channel的差异,如下公式。
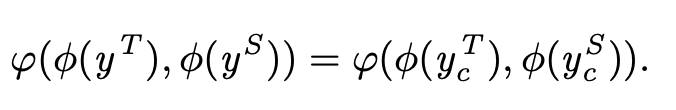
其中
ϕ
\phi
ϕ的是softmax:
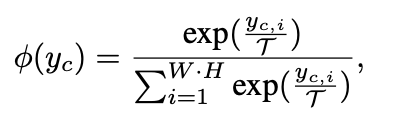
上式中的c代表通道channel,i代表channel中的location,
τ
\tau
τ代表知识蒸馏中常用的超参数温度,作用是调节训练过程中的对负样本的的重视程度。
如果student网络和teacher网络对channel数不一致,可使用1X1的卷积对通道数进行调整。
φ
\varphi
φ(.)是使用KL散度对两个网络之间的差异性进行评估:
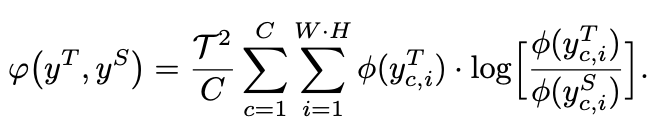
KL散度是一种非对称的指标。从上面的公式中可以看出,如果
ϕ
(
y
c
,
i
T
)
\phi(y^T_{c,i})
ϕ(yc,iT)值较大,
ϕ
(
y
c
,
i
S
)
\phi(y^S_{c,i})
ϕ(yc,iS)也应该和前者差不多大时才能最小化KL散度的值。另一种情况,当
ϕ
(
y
c
,
i
T
)
\phi(y^T_{c,i})
ϕ(yc,iT)较小时,整个KL散度的值也会较小,训练过程中也就不会对
ϕ
(
y
c
,
i
S
)
\phi(y^S_{c,i})
ϕ(yc,iS)过于重视,因为此时当前的location并不是正样本。综上来看,使用KL散度有利于student网络学习到和teacher网络一致的前景概率分布,而背景区域则在学习过程中产生的影响较小。
下面是对上述方法的代码解读:
N, C, H, W = preds_S.shape
# 对teacher网络的输出softmax化
softmax_pred_T = F.softmax(preds_T.view(-1, W * H) / self.tau, dim=1)
logsoftmax = torch.nn.LogSoftmax(dim=1)
# 对上面公式的复现
loss = torch.sum(softmax_pred_T *
logsoftmax(preds_T.view(-1, W * H) / self.tau) -
softmax_pred_T *
logsoftmax(preds_S.view(-1, W * H) / self.tau)) * (
self.tau**2)
loss = self.loss_weight * loss / (C * N)
Experiments
论文中做了两组消融实验。
Effectiveness of channel-wise distillation
这组实验是确认使用channel-wise和KL散度做蒸馏的有效性。实验结果如下:
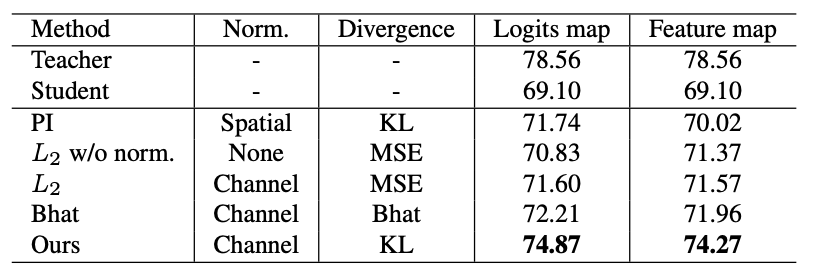
和其他的方法对比,本论文的的方法具有显著的提升效果,表中的Bhat是一种对称式的分布评价指标,用来和非对称的KL作对比。
Impact of the temperature parameter and loss weights
这组实验研究的是温度系数和loss权重的影响:
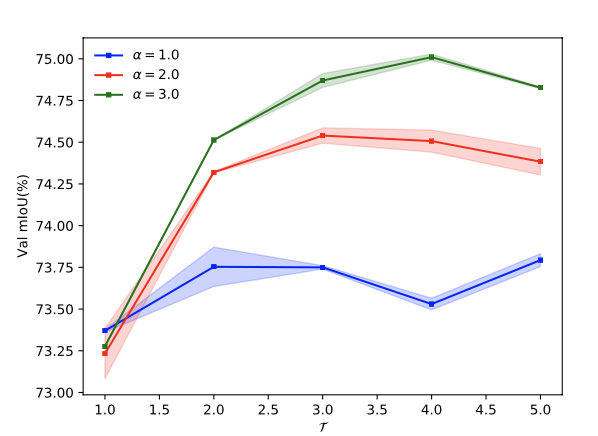
从实验结果得知,更高的温度系数有助于更好的蒸馏效果,在高到一定范围内,对蒸馏的影响也会趋于稳定。温度系数如果很低,那么整体指标会下降,因为在这种情况下,训练更多的是聚焦于重点像素区域。实验表明了使用PSPNet18模型,采取
τ
=
4
\tau=4
τ=4、
φ
=
3
\varphi=3
φ=3,在Cityscapes上的评估指标为最佳。
Qualitative segmentation results
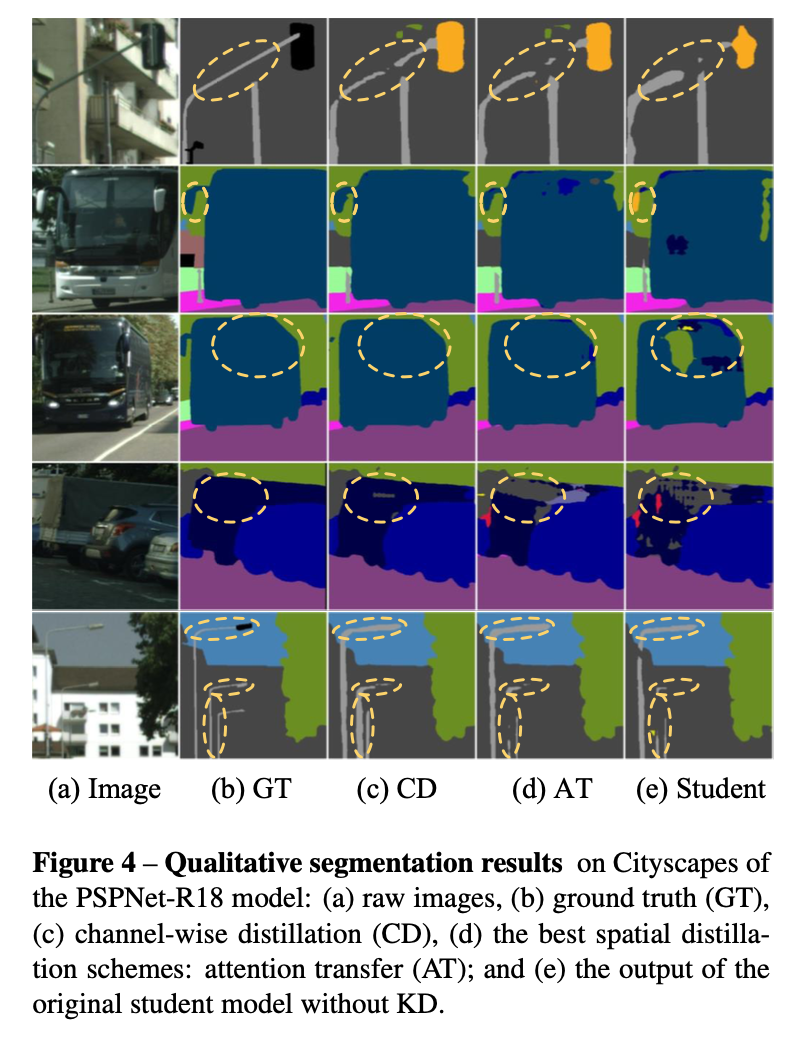
b为真值图,c为采用本文方法channel蒸馏的效果图,d为最好的spatial蒸馏的效果图,e为没有蒸馏的student模型的效果图,从效果图上看本文方法最佳。
Conclusion
论文针对dense prediction提出的channel-wise蒸馏方法,不同于以往的spatial蒸馏,将每个channel的激活层使用softmax标准化为probability map,然后使用KL散度缩小teacher网络和student网络之间的差异。实验表明了这种方法的有效性,并且在semantic segmentation和object detection两个方向表现出了state-of-the-art。
如果本文对你有帮助,更多内容请关注微信公众号【杰读源码】
















 6680
6680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









