






链接:https://arxiv.org/pdf/2502.20380
1. 摘要与动机
论文目标
本文聚焦于利用多轮执行反馈进行代码生成的问题。现有方法要么完全不使用反馈生成代码,要么依赖复杂的层级强化学习来优化多轮奖励,但这往往带来学习信号稀疏和训练效率低下的问题。
核心思路
作者提出了一种名为
μ
CODE
\mu\text{CODE}
μCODE 的方法,其核心思想在于:
- 一轮可恢复性:认为代码生成任务可以看作是一个一轮可恢复(one‐step recoverable)的马尔可夫决策过程(MDP),即无论处于何种中间状态,只需一步就可以恢复到正确的代码。
- 因此,可以利用单步奖励(而非多步复杂的回报优化)来训练模型,从而将问题从强化学习转化为模仿学习,获得更稳定、高效的训练过程。
2. 问题定义与背景建模
2.1 多轮代码生成建模为 MDP
-
状态定义
对于给定问题提示 x x x,在多轮交互中,第 t t t 轮的状态定义为:
s t = { x , y 1 , o 1 , y 2 , o 2 , … , y t − 1 , o t − 1 } s_t = \{ x, y_1, o_1, y_2, o_2, \dots, y_{t-1}, o_{t-1} \} st={x,y1,o1,y2,o2,…,yt−1,ot−1}
其中 y i y_i yi 为第 i i i 轮生成的代码, o i o_i oi 为该代码在公共测试上的执行反馈。 -
动作定义
动作即为生成的代码片段 a t = y t a_t = y_t at=yt。 -
奖励函数
定义oracle奖励 R ( s t , a t ) = R ( x , y t ) R(s_t, a_t) = R(x, y_t) R(st,at)=R(x,yt),若 y t y_t yt 同时通过所有公共和私有测试,则奖励为 1,否则为 0。 -
目标
在训练数据集 D D D 上,目标是找到生成器 π θ ( y t ∣ s t ) \pi_\theta(y_t|s_t) πθ(yt∣st) 来最大化累积折扣奖励:
max π θ E x ∼ D , y t ∼ π θ ( ⋅ ∣ s t ) [ ∑ t = 1 T γ t R ( x , y t ) ] . \max_{\pi_\theta} \mathbb{E}_{x \sim D,\, y_t \sim \pi_\theta(\cdot|s_t)} \left[\sum_{t=1}^T \gamma^t R(x, y_t)\right]. πθmaxEx∼D,yt∼πθ(⋅∣st)[t=1∑TγtR(x,yt)].
3. μ CODE \mu\text{CODE} μCODE 方法
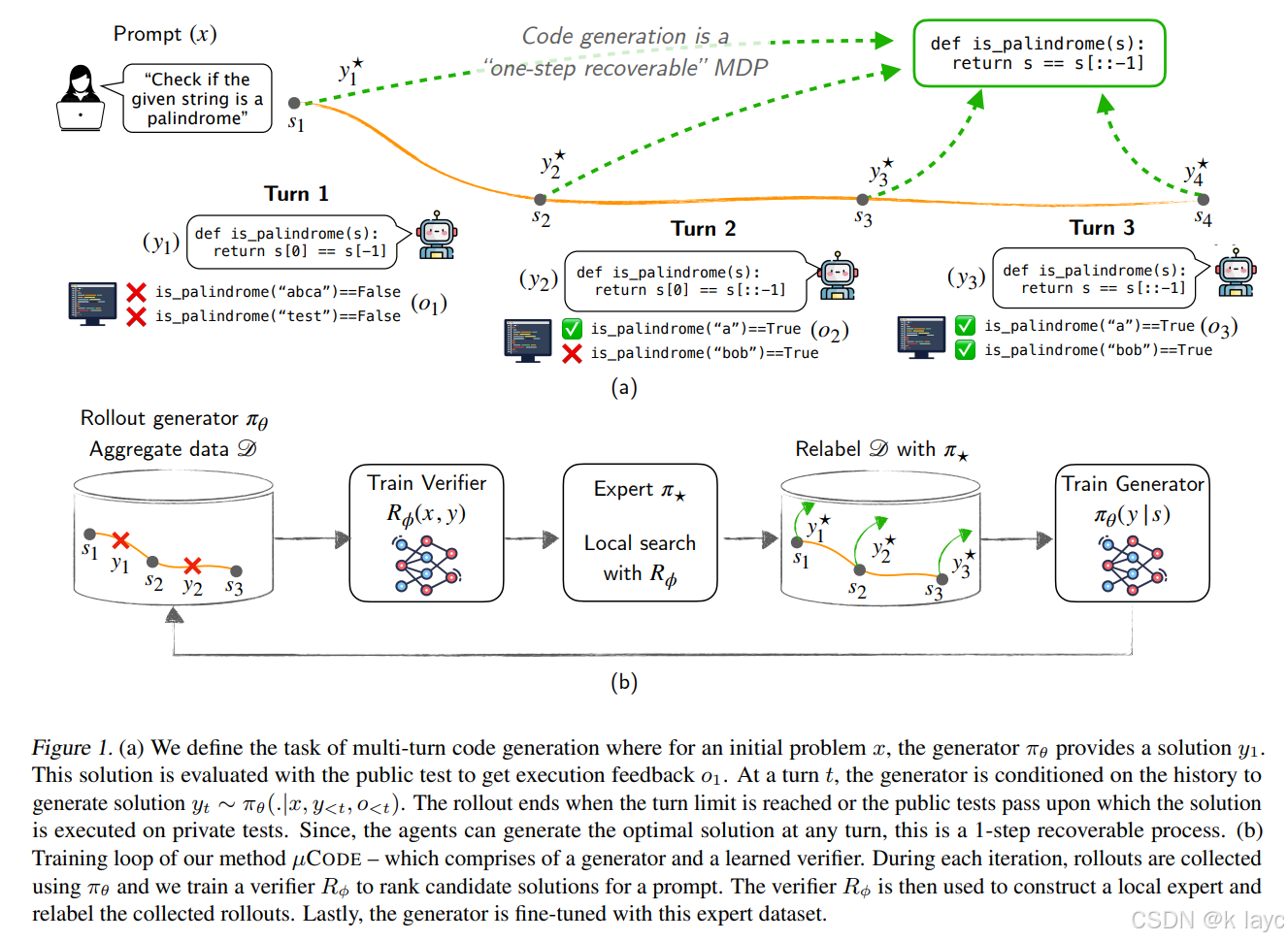
论文提出的 μ CODE \mu\text{CODE} μCODE 方法基于专家迭代(expert iteration)框架,将多轮代码生成转化为交互式模仿学习,主要分为以下几个部分:
3.1 整体训练流程
-
数据采集(Rollout)
- 使用当前生成器
π
θ
\pi_\theta
πθ 在多轮环境中生成交互数据:
D i ← { ( x , s t , y t , o t ) } , D_i \leftarrow \{(x, s_t, y_t, o_t)\}, Di←{(x,st,yt,ot)},
其中每轮数据包含问题提示 x x x、状态 s t s_t st、生成的代码 y t y_t yt 以及执行反馈 o t o_t ot。
- 使用当前生成器
π
θ
\pi_\theta
πθ 在多轮环境中生成交互数据:
-
训练验证器(Verifier)
- 聚合所有采集数据 D = ⋃ i D i D = \bigcup_i D_i D=⋃iDi 后,训练一个验证器 R ϕ ( x , y ) R_\phi(x, y) Rϕ(x,y),用于为每个代码生成打分。
- 验证器有助于在局部搜索中评估候选代码的质量。
-
构造局部专家(Local Expert)
- 对于每个问题
x
x
x,构造专家策略:
π ∗ ( x ) = arg max y ∈ D ( x ) R ϕ ( x , y ) , \pi^*(x) = \arg\max_{y \in D(x)} R_\phi(x, y), π∗(x)=argy∈D(x)maxRϕ(x,y),
即在所有生成的代码中选出得分最高的那个作为“专家”输出。
- 对于每个问题
x
x
x,构造专家策略:
-
数据重标记与生成器训练
- 使用局部专家对数据进行重标记,生成专家数据集:
D ∗ = { ( x , s t , y ∗ ) ∣ y ∗ = π ∗ ( x ) } . D^* = \{(x, s_t, y^*) \mid y^* = \pi^*(x)\}. D∗={(x,st,y∗)∣y∗=π∗(x)}. - 然后对生成器 π θ \pi_\theta πθ 进行微调,使其模仿专家的行为。
- 使用局部专家对数据进行重标记,生成专家数据集:
-
迭代更新
- 重复上述步骤多次,每次迭代都能让生成器和验证器相互提升。
算法伪代码(Algorithm 1)大致描述了这一迭代过程。

3.2 验证器的训练

验证器 R ϕ ( x , y ) R_\phi(x, y) Rϕ(x,y) 用于为给定问题 x x x 下的代码 y y y 打分。文中提出两种损失函数来训练验证器:
-
Binary Cross-Entropy (BCE) 损失
直接用二元交叉熵损失训练验证器预测 oracle 奖励:
L BCE ( ϕ ) = − E ( x , y , r ) ∼ D [ r log R ϕ ( x , y ) + ( 1 − r ) log ( 1 − R ϕ ( x , y ) ) ] . L_{\text{BCE}}(\phi) = -\mathbb{E}_{(x,y,r)\sim D} \Big[r\log R_\phi(x,y) + (1-r)\log (1-R_\phi(x,y))\Big]. LBCE(ϕ)=−E(x,y,r)∼D[rlogRϕ(x,y)+(1−r)log(1−Rϕ(x,y))]. -
Bradley-Terry (BT) 损失
由于目标是对代码进行相对排序,BT 损失基于对比正确代码 y + y^+ y+ 与错误代码 y − y^- y−:
L BT ( ϕ ) = − E ( x , y + , y − ) ∼ D [ log σ ( R ϕ ( x , y + ) − R ϕ ( x , y − ) ) ] , L_{\text{BT}}(\phi) = -\mathbb{E}_{(x,y^+,y^-)\sim D} \left[\log \sigma\Big(R_\phi(x,y^+)-R_\phi(x,y^-)\Big)\right], LBT(ϕ)=−E(x,y+,y−)∼D[logσ(Rϕ(x,y+)−Rϕ(x,y−))],
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 sigmoid 函数。作者发现 BT 损失更易优化。
3.3 生成器的训练
- 对于每个问题
x
x
x,从数据集中选择最优代码:
y ∗ = π ∗ ( x ) = arg max y ∈ D ( x ) R ϕ ( x , y ) . y^* = \pi^*(x) = \arg\max_{y \in D(x)} R_\phi(x,y). y∗=π∗(x)=argy∈D(x)maxRϕ(x,y). - 重标记数据后得到专家数据集 D ∗ D^* D∗,并利用该数据对生成器进行微调,使其学会模仿专家输出。
3.4 推理阶段:多轮 Best-of-N 搜索
-
多轮生成
在推理时,给定当前状态 s t s_t st,生成器生成 N N N 个候选代码 { y t n } n = 1 N \{y^n_t\}_{n=1}^N {ytn}n=1N。 -
候选排序与选择
使用验证器对候选代码进行打分,并选择得分最高的代码:
y t ∗ = arg max 1 ≤ n ≤ N R ϕ ( x , y t n ) . y^*_t = \arg\max_{1 \le n \le N} R_\phi(x, y^n_t). yt∗=arg1≤n≤NmaxRϕ(x,ytn). -
迭代反馈
将选出的代码执行后获得反馈 o t o_t ot,并更新状态为 s t + 1 = { s t , y t ∗ , o t } s_{t+1} = \{s_t, y^*_t, o_t\} st+1={st,yt∗,ot},重复这一过程直至代码通过公共测试或达到最大轮数 T T T。
算法伪代码(Algorithm 2)描述了这一多轮 Best-of-N 推理流程。
4. 理论分析
4.1 一步可恢复 MDP 定义
论文将代码生成过程建模为一个“一步可恢复”的 MDP,其定义为:
- 对于任意状态
s
s
s 和动作
a
a
a,最优策略的优势函数满足:
A ∗ ( s , a ) = Q ∗ ( s , a ) − V ∗ ( s ) ≤ 1. A^*(s,a) = Q^*(s,a) - V^*(s) \le 1. A∗(s,a)=Q∗(s,a)−V∗(s)≤1.
其中,最优 Q 函数满足 Q ∗ ( s , y t ) = R ( x , y t ) Q^*(s, y_t) = R(x, y_t) Q∗(s,yt)=R(x,yt),而最优值函数为 V ∗ ( s ) = max y ′ R ( x , y ′ ) V^*(s) = \max_{y'} R(x,y') V∗(s)=maxy′R(x,y′)。
4.2 性能界
利用“性能差分引理”(Performance Difference Lemma)和 DAGGER(交互模仿学习)理论,作者证明了以下性能界:
J
(
π
∗
)
−
J
(
π
)
≤
O
(
T
(
ϵ
+
γ
(
N
)
)
)
,
J(\pi^*) - J(\pi) \le O\Big(T (\epsilon + \gamma(N))\Big),
J(π∗)−J(π)≤O(T(ϵ+γ(N))),
其中:
- π ∗ \pi^* π∗ 为专家策略,
- ϵ \epsilon ϵ 为可实现性误差,
- γ ( N ) \gamma(N) γ(N) 为平均后悔值。
这一结果表明,对于一轮可恢复的 MDP,模仿学习可以高效地逼近最优策略,其性能损失仅与轮数 T T T 及误差成线性关系,而比一般无法恢复的 MDP 中 O ( ϵ T 2 ) O(\epsilon T^2) O(ϵT2) 的界要好得多。
5. 实验与结果
5.1 实验设置
-
数据集
使用 MBPP(374 个训练样本,500 个测试样本)和 HumanEval(164 个问题)数据集进行评估,任务为根据自然语言描述生成 Python 代码。 -
基线比较
比较方法包括单轮生成(Instruct)、基于 oracle 正确答案微调的 STaR 以及其多轮版本 Multi-STaR。
同时,还评估了多轮 Best-of-N(BoN)搜索对性能的提升。
5.2 主要实验结果
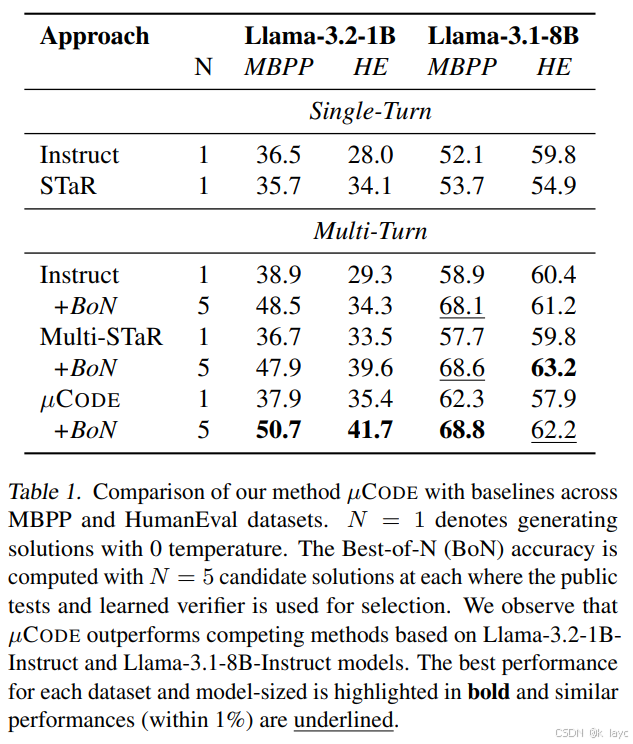
-
生成器评估
当使用贪婪采样(温度设为 0)时,Multi-turn 方法(包括 Multi-STaR 和 µCODE)均优于单轮生成,表明利用执行反馈有助于提高代码正确率。 -
BoN 搜索效果
利用 BoN 搜索(例如 N = 5),在 MBPP 和 HumanEval 数据集上,µCODE 相较于 Multi-STaR 分别在 1B 模型上取得了 1.9% 的提升,并在 8B 模型上在 MBPP 上超越基线,而在 HumanEval 上则表现相近。
5.3 消融实验
-
验证器作用
对比使用 oracle 验证器(OV)与使用学习得到的验证器(LV)进行数据重标记,结果表明:- 单独使用 LV 重标记获得的效果在 MBPP 上最好,在 HumanEval 上与 OV+LV 组合相近。
-
不同生成器
分析了使用 oracle 验证器与学习验证器对生成器多轮改进的影响,结果显示,利用 LV 重标记使得生成器在每一轮都能更好地利用执行反馈,从而逐步提升 BoN 准确率。 -
验证器损失函数
比较 BCE 损失与 BT 损失训练的验证器,实验发现 BT 损失训练的验证器在不同候选数量 N N N 下表现更优,证明了利用相对排序信号更易优化。 -
测试时扩展
实验还考察了在推理时候每轮候选生成数量 N N N 的扩展效果,发现随着 N N N 增大,BoN 准确率有提升,但当 N N N 超过一定值后(例如 MBPP 数据集 N ≥ 5 N \ge 5 N≥5)增益开始减弱。
6. 相关工作
论文讨论了与多轮代码生成相关的其他工作,主要包括:
- 基于提示(prompting)的代码生成与自我调试方法(如 Self-Debugging、AlphaCodium、MapCoder)。
- 利用强化学习训练代码生成器的方法(如 CodeRL、ARCHER、MCTS 等)。
- 一些方法直接利用执行反馈作为奖励,但往往需要复杂的层级设计,而 µCODE 则利用“一步可恢复”这一结构特性,将问题简化为模仿学习。
7. 结论
本文提出了 μ CODE \mu\text{CODE} μCODE,一种简单且可扩展的多轮代码生成方法,其主要贡献包括:
- 新框架:将多轮代码生成建模为“一步可恢复”的 MDP,并利用单步奖励实现多轮生成的高效模仿学习。
- 验证器设计:提出了基于学习的验证器用于数据重标记和多轮 Best-of-N 搜索,并证明了相对排序损失(BT 损失)在训练验证器时的优势。
- 实验效果:在 MBPP 和 HumanEval 数据集上,µCODE 在不同规模模型上均超越了现有多轮方法,展示了利用执行反馈进行逐步改进的有效性。
此外,理论分析证明了对于一轮可恢复的 MDP,利用模仿学习可以获得较好的性能界,并且实验中消融分析进一步验证了验证器和多候选搜索策略的重要性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









