






链接:https://arxiv.org/pdf/2503.02003
论文详细解读
本论文针对大型语言模型(LLM)在生成答案时常出现“幻觉”——即生成混合事实与非事实陈述的问题,提出了一种新颖的提示技术:Highlighted Chain-of-Thought Prompting(HoT)。该方法通过在生成链式思考(Chain-of-Thought, CoT)的过程中,对输入问题中的关键信息进行 XML 标签高亮,并在回答中引用这些标签,旨在提高模型的答案准确性及其可验证性。以下从各个角度对论文进行详细解读。
1. 摘要与研究动机
-
背景问题:
- 大型语言模型在生成答案时容易“幻觉”,即输出中混杂非事实的内容,给用户验证答案正确性带来困难。
- 现有方法多采用后置引用外部文献或文档,但无法直接将生成过程中的关键事实与输入对应起来。
-
研究目标:
- 设计一种新的提示技术 —— HoT,使得模型在生成答案前首先对输入问题进行重格式化,通过 XML 标签将关键信息(例如数字、关键实体等)高亮。
- 在生成回答时,模型会引用这些高亮标签,从而使答案中涉及的每个事实都能追溯到输入问题中的支持信息。
-
主要贡献:
- 提出了 HoT 提示结构,对传统的 CoT 方法进行增强。
- 在 17 个任务(包括算术、逻辑推理、问答和阅读理解)上进行了大规模实验,并在多个模型(如 GPT-4o、Gemini 系列、Llama 系列)上展示了显著性能提升。
- 通过用户实验,证明高亮(highlight)不仅加快了人类验证答案的速度,同时在某些情况下也提高了验证准确率(但也存在过度信任错误答案的风险)。
2. 论文整体结构

-
引言
- 阐述了 LLM 生成答案时出现幻觉的问题及现有解决方案的不足。
- 引出利用 XML 标签高亮关键信息的思路。
-
相关工作
- 回顾了生成带引用的答案的方法,如引用网页、文档、段落等。
- 讨论了传统的 CoT 提示、Re-reading 和 EchoPrompt 等技术在问题重述和答案生成中的应用。
-
方法
- 重格式化输入问题: 利用 XML 标签(例如
<fact1>,<fact2>, …)标记问题中不可或缺的关键信息。 - 生成带高亮的答案: 模型在生成答案时,会在涉及关键事实的部分嵌入相应的 XML 标签,使得答案中的每个关键信息都能直接对应到输入问题中。
- 提供了完整的提示结构示例(包括 8-shot 示例),确保模型能够按照预期格式生成回答。
- 重格式化输入问题: 利用 XML 标签(例如
-
实验设计
- 选择了 17 个数据集,覆盖算术问题、逻辑推理、问答任务和阅读理解。
- 实验比较了多种提示策略:传统 CoT、仅重复问题(R-Q)、仅在问题中添加标签(T-Q)、仅在答案中添加标签(T-A)以及完整的 HoT 方法。
-
结果与消融研究
- 在各类任务上 HoT 均表现优于传统 CoT 提示,提升幅度在不同任务中有所不同。
- 消融实验表明:重复问题、在问题中添加标签以及在答案中添加标签,各自都能带来一定提升,而将两者结合(即完整的 HoT)效果最佳。
- 分析了标签匹配的重要性,指出标签错位会显著降低准确性。
-
用户验证实验
- 对比了用户在验证 HoT 与 CoT 答案时的时间与准确率,发现 HoT 可使验证时间平均减少约 25%(从 62.38 秒减少到 47.26 秒)。
- 但同时,高亮可能使用户在遇到错误答案时更倾向于误认为其正确。
-
讨论与未来工作
- 提出了 HoT 改善模型性能的潜在原因:标签在注意力矩阵中重复出现,有助于模型更好地捕捉关键信息。
- 讨论了方法的局限性,如格式一致性问题、少样本依赖性以及过度信任高亮带来的风险,并指出未来的改进方向,如对模型进行微调使其直接生成 HoT 格式答案。
-
结论
- HoT 方法有效提高了 LLM 在多种任务上的准确性,并能加快人类对答案的验证速度,为解释性 AI 以及人机交互提供了新的思路。
3. 方法详解

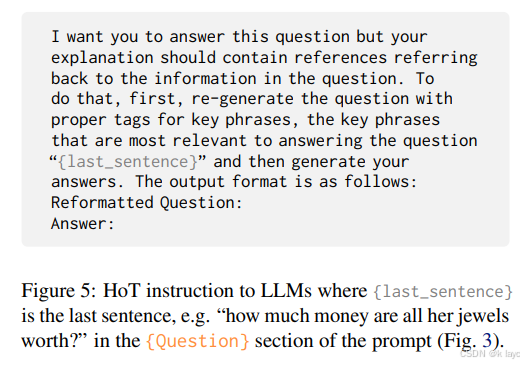
3.1 HoT 提示结构
-
步骤 1:重格式化问题
- 利用 XML 标签对输入问题中的关键信息进行包裹。标签命名一般采用
<fact1>,<fact2>等,标记那些若被移除后会使问题无法解答的关键内容。 - 例如:
- 原问题:
Jenna starts out with 8 sapphires. She trades 3 sapphires for two rubies... - 重格式化后:
Jenna starts out with <fact1>8 sapphires</fact1>. She trades <fact2>3 sapphires</fact2> for <fact3>two rubies</fact3>...
- 原问题:
- 利用 XML 标签对输入问题中的关键信息进行包裹。标签命名一般采用
-
步骤 2:生成带高亮标签的答案
- 模型生成答案时,在涉及上述关键信息的部分也嵌入相应标签,从而形成问题与答案之间的对应关系。
- 示例回答中对数量计算、价格计算均使用了标签引用,使得每一处计算均可追溯到原问题中的相关信息。
3.2 提示设计示例
- 示例输入:
Question: Jenna starts out with 8 sapphires. She trades 3 sapphires for two rubies. If sapphires are worth $800 and rubies are worth $1200, how much money are all her jewels worth? - 重格式化后的问题:
Reformatted Question: Jenna starts out with <fact1>8 sapphires</fact1>. She trades <fact2>3 sapphires</fact2> for <fact3>two rubies</fact3>. If sapphires are worth <fact4>$800</fact4> and rubies are worth <fact5>$1200</fact5>, how much money are all her jewels worth? - 生成的答案:
Answer: Jenna starts with <fact1>8 sapphires</fact1> and trades away <fact2>3 sapphires</fact2>, leaving her with $8-3=5$ sapphires, worth $5\times<fact4>$800</fact4>=$4000. She receives <fact3>two rubies</fact3> worth $2\times<fact5>$1200</fact5>=$2400. In total, her jewels are worth $4000+2400=$6400.
这种格式要求模型在生成答案时必须将输入中关键的数值和信息与答案中的计算、推理直接关联,从而降低幻觉风险并便于后续验证。
4. 实验设计与数据集
4.1 数据集分类
- 算术问题:
- 数据集包括 GSM8K、MultiArith、ASDiv、SVAMP、AQUA、r-GSM 和 GSM-Symbolic。
- 逻辑推理:
- 来自 BigBench Hard 的任务,如 Five Objects、Seven Objects、Colored Objects、Causal Judgement 和 Navigate。
- 问答任务:
- 如 StrategyQA、SpartQA、Date Understanding。
- 阅读理解:
- 采用 DROP 数据集中的 Break 和 Census 子集。
4.2 模型与对比方法
- 使用模型:
- 实验涉及多种大型语言模型:GPT-4o、Gemini-1.5-Flash、Gemini-1.5-Pro、Llama-3.1-70B、Llama-3.1-405B 等。
- 对比提示:
- CoT: 标准的链式思考提示,不包含 XML 标签。
- R-Q: 仅重复问题,不对问题添加标签。
- T-Q: 仅在问题中添加 XML 标签。
- T-A: 仅在答案中添加 XML 标签。
- HoT: 同时在问题和答案中添加 XML 标签(完整方案)。
5. 实验结果与消融研究
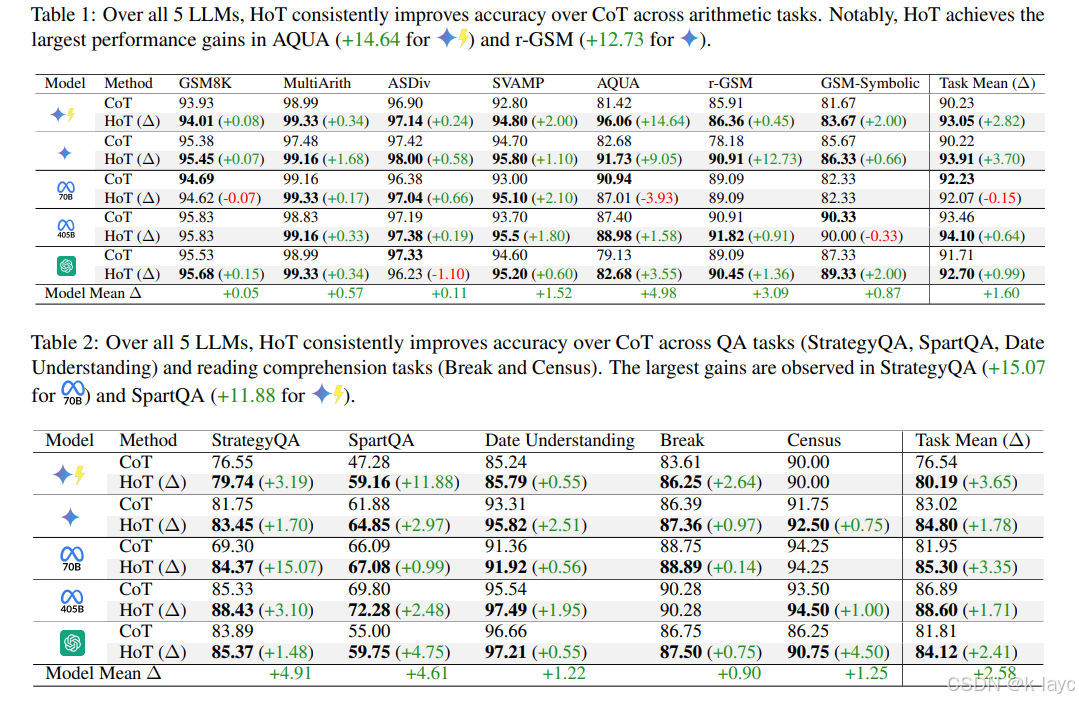
5.1 模型准确性提升
- 整体提升:
在算术、问答和逻辑推理任务上,HoT 分别平均提升了约 + 1.60 +1.60 +1.60、 + 2.58 +2.58 +2.58 和 + 2.53 +2.53 +2.53 个百分点(pp)。 - 局部显著提升:
在 AQUA 与 StrategyQA 等较难任务上,提升幅度分别高达 + 14.64 +14.64 +14.64 和 + 15.07 +15.07 +15.07 个百分点。
5.2 消融研究
-
各组件效果:
- 重复问题(R-Q): 本身能提高准确性,但效果有限。
- 仅在问题中添加标签(T-Q)或仅在答案中添加标签(T-A): 均比 R-Q 提升更多,但单独使用时仍不及完整 HoT。
- 完整 HoT: 同时在问题和答案中添加标签,获得最佳效果。
-
标签匹配:
- 实验还表明,将答案中的标签错误地分布到其他随机位置(即标签不匹配原问题)会导致准确性平均下降约 $-2.13$ pp,证明了标签精确对应的重要性。
5.3 人类验证实验
- 验证速度:
使用 HoT 提示的答案使用户在验证过程中平均所需时间从 62.38 秒减少至 47.26 秒,约提升 25% 的速度。 - 验证准确率:
用户在验证正确答案时准确率提高(84.48% 对比 78.82%),但在验证错误答案时准确率下降(54.83% 对比 72.21%),表明高亮可能导致用户过于信任答案。
5.4 人类验证准确率估计
论文提出了一个估计用户验证准确率的公式:
P
=
M
c
×
H
c
+
(
1
−
M
c
)
×
H
i
P = M_c \times H_c + (1 - M_c) \times H_i
P=Mc×Hc+(1−Mc)×Hi
其中:
- M c M_c Mc 为模型的实际准确率,
- H c H_c Hc 为用户在面对正确答案时的验证准确率,
- H i H_i Hi 为用户在面对错误答案时的验证准确率。
实验结果显示,基于该公式,HoT 在所有 17 个数据集上的估计验证准确率比 CoT 平均高出约 $+3.33$ 个百分点。
5.5 模型自我验证
- 当使用其他 LLM 对答案进行验证时,HoT 高亮对验证准确性的影响不够一致,可能是因为大部分错误信息并不出现在 XML 标签包裹的部分。
6. 讨论与未来工作
-
机制分析:
研究者推测,强制模型生成在问题和答案中匹配的 XML 标签,使得这些标签在注意力矩阵中出现两次,从而促使模型更多地关注关键信息。这一机制与 Mekala et al. (2024) 和 Xu et al. (2024) 的相关发现相符。 -
未来方向:
- 微调模型: 使模型能够直接生成符合 HoT 格式的答案,而不依赖于少量示例。
- 标签策略优化: 探讨更为稳定的标签生成方法,特别是在较小模型中解决格式不一致问题。
- 人机交互优化: 研究如何避免高亮带来的过度信任问题,平衡用户验证的准确性与效率。
7. 局限性
- 格式一致性: 较小的模型在生成 XML 标签时可能出现重复或不规范的问题,影响最终答案的可靠性。
- 标签依赖风险: 错误的标签生成可能使部分关键信息丢失或误导用户,从而降低验证效果。
- 少样本依赖: 当前方法依赖于 8-shot 或 15-shot 示例指导,未来工作需要探索更鲁棒的提示设计方法,减少对示例的依赖。
8. 结论
论文提出的 HoT(Highlighted Chain-of-Thought Prompting) 方法通过在问题和答案中添加 XML 标签,有效地提高了大型语言模型在多种任务上的回答准确性,同时加速了用户验证答案的过程。尽管该方法存在格式一致性和高亮可能诱导过度信任等局限性,但它为提高 LLM 解释性和可靠性提供了新的思路,并为未来的研究指明了方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









