






Resnet-50
Motivation:
深层次的网络往往能够提取到更丰富的特征,但是随着网络层数的加深会出现
网络退化的现象,也就是随着网络的加深性能变弱了。
Resnet50在网络层间加shutcut connection,实际网络学习的目标是一个残差项。如果当前网络已经达到最优,不需要再加深,那么接下来网络层的residual mapping部分会被push为0,只有identity mapping向下原封不动的传递上层网络的信息。如果当前网络还需要加深,那么接下来网络层residual mapping 部分继续学习层之间的参差项。
实现方式
传统网络输出到下一层的是F(X),那么resnet输出到下一层的是 F(x)+x,这里的F(x)就是指的residual mapping,而x是指identity mapping。对于residual mapping,v1的实现方式是以weight-bn-relu-weight-bn 加identity relu, v2的实现方式是bn-relu-weight-bn-relu-weight 加identity,是为了保证identiy mapping的分布一致性。
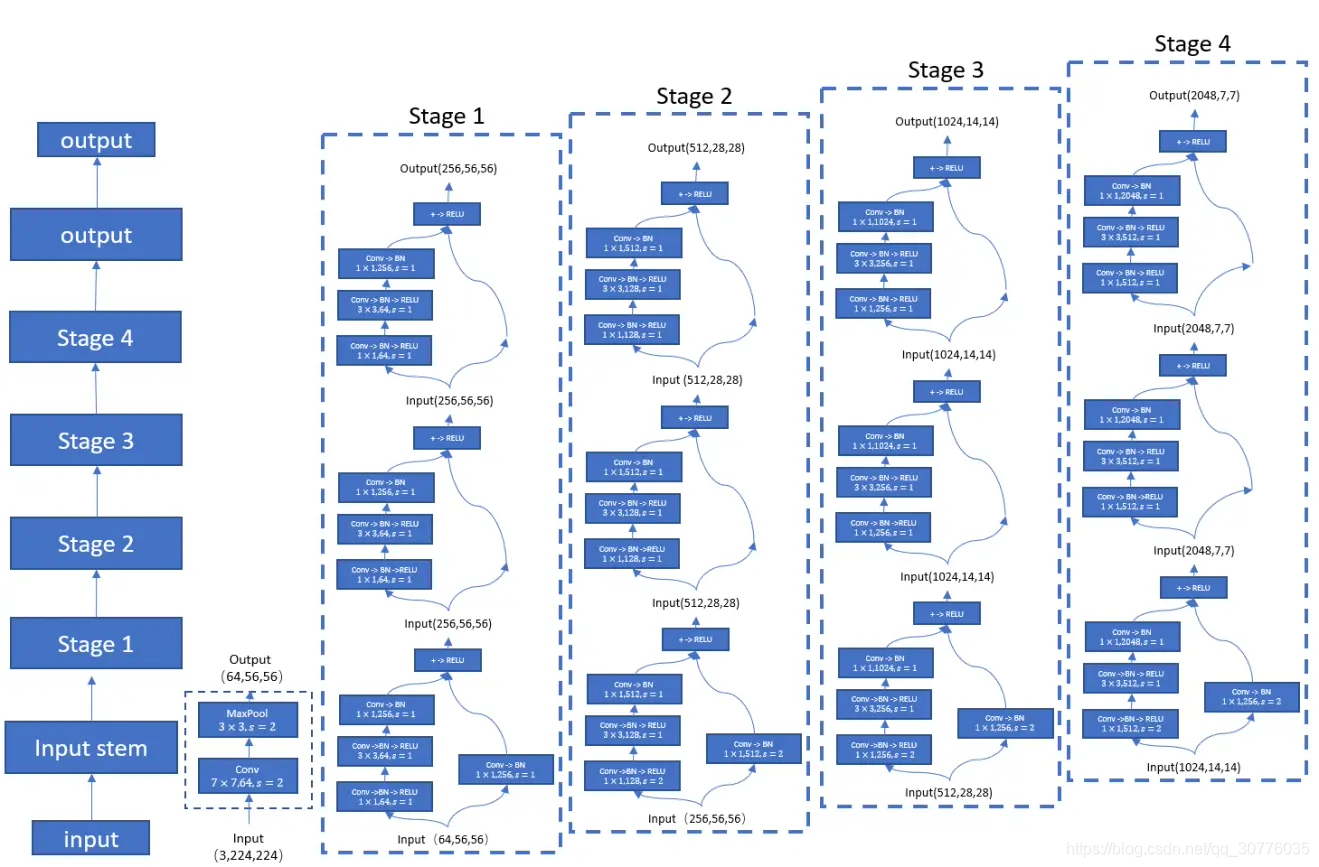
resnet-50 结构
分为5个stage,stage1由普通的conv 和maxpooling组成,对特征做一个初步提取,剩下的4个stage,每个stage 由1个下采样块和2个bottleneck block 也就是残差块组成。
bottleneck block名字中含有bottleneck 是因为这个block的residual mapping 分支在3x3conv的前后分别通过1x1 conv 来缩减、复原通道数,加入1x1conv之后减小了参数量和计算量。identity mapping分支直接该block的输入。
下采样块在残差块的基础上要处理随着stage深入减小feature map和通道对齐问题。stage3-5通过将residual 分支和identity 分支的第一个conv的stride设为2,来缩小feature map。stage 2-5通过在identity 分支加入1x1conv层,帮助完成通道扩张前后identity 分支 和residual 分支通道数的统一。通过设置第一个conv的stride=2实现feature map 的缩小。
Cross entropy loss
对输出过一个softmax函数算出样本属于各类的概率,然后最小化估计的概率分布和实际样本分布之间的交叉熵。
BN层训练、测试区别
在训练阶段,running_mean和running_var在每次前向时更新一次;在测试阶段,则通过net.eval()固定该BN层的running_mean和running_var,此时这两个值即为训练阶段最后一次前向时确定的值,并在整个测试阶段保持不变。
pytorch train() eval()
train() 训练阶段,打开dropout 和BN
eval() 测试阶段,关闭dropout、BN















 4681
4681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









